Unifying LLM-powered QA Techniques with Routing Abstractions
Summary
A variety of techniques for LLM-based QA over your data have emerged: e.g. semantic search, hybrid search for fact-based lookup, retrieving entire documents for summarization tasks, and more. Each technique is typically optimized for different query use cases.
We believe “router” abstractions can help unify these techniques under a single query interface. We discuss our recently released router implementation within LlamaIndex and also describe how these router abstractions can be generalized in the future.
Current Retrieval Techniques for LLM-powered QA
Given a relevant context and a task in the input prompt, Large Language Models (LLMs) can effectively reason over novel information that was not observed in the training set to solve the task at hand. As a result, a popular usage mode of LLMs is to solve Question-Answering (QA) tasks over your private data. They are typically paired with a “retrieval model” to form an overall “Retrieval-Augmented Generation” (RAG) system.
These days, a variety of retrieval techniques for LLM-powered QA have emerged. One common among all these techniques is that each typically works better for certain QA use cases, and works less well for other use cases.
Here are some examples:
- Semantic Search (top-k): Retrieve the top-k chunks from the knowledge corpus by semantic similarity. This typically works better for questions that require lookup of specific facts from the corpus, e.g. “What did the author do during his time in college?”
- Summarization: Retrieve all chunks from a document or set of documents. This retrieval method is typically used with queries that ask more general questions over your data, e.g. “What is a summary of this document?”
- Temporal Recency Weighting: Weight retrieved texts by their recency, prioritizing more recent texts over older ones. This can be achieved for instance by a simple decay function or can be achieved by reranking nodes by date. This method is optimized for queries that require “freshness” of the data.
Different retrieval techniques are optimized for different query use cases. A natural followup question to ask: how can we try unifying all these techniques under a single query interface? That way, the user can ask a question to a single interface and get back their desired answer, instead of having to tune a specific retrieval technique.
In this article, we focus on routing as a key component in the solution to this problem.
Routing
The router concept is not new; there’s a variety of papers on this topic, and it has inherently been a part of the LLM agent/tool abstraction. An agent inherently needs to make a decision to pick the best tool for the current task at hand, and this involves routing.

Having a router can be especially powerful for enhancing Retrieval Augmented Generation (RAG), by alleviating the issue of knowing apriori what retrieval technique to use for certain queries. A router can take in a user query as input, and automatically decide which retrieval technique to use under the hood. For instance, if it detects that the query requires summarization from a set of documents, it can call a “Tool” that is specialized in summarization. If it detects that the query requires fact-based lookup, it can call a simple vector store interface to perform top-k lookup and retrieval.
Simple Router Implementation (LlamaIndex)
A quick refresher: as of 0.6.0, LlamaIndex has multiple layers of abstraction to decouple the following: Indexes, Retrievers, Response Synthesis, and Query Engines. A query engine is the top-level abstract query interface that takes in a natural language input, and can (optionally) use retrievers/response synthesis modules to return an output that the user would want.

The base class essentially defines the following lightweight interface:
class BaseQueryEngine(ABC):
...
@abstractmethod
def query(self, str_or_query_bundle: QueryType) -> RESPONSE_TYPE:
passWe’ve now defined a RouterQueryEngine that can take as input a set of underlying query engines as QueryEngineToolobjects.
Each query engine can be defined for a given use case, and use a set of indices/retrievers under the hood to solve that given use case.
# define router query engine
query_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[
list_tool,
vector_tool,
]
)For instance, relating this to the examples given in the beginning, you could have one query engine optimized for semantic search, another query engine optimized for document summarization, and a third optimized for temporal recency.
Each underlying query engine is defined as a “Tool” — this is very similar to the agent interface. At the current moment, the way the “Tool” is defined is just with a text description attached to it. The router uses the text description in deciding which underlying query engine to select to execute the query.
Below, we show a simple sketch of how to use the Router Query Engine. We define a list_tool and vector_tool over a list index query engine and vector index query engine respectively. We then instantiate the RouterQueryEngine with these two tools along with a selector.
from llama_index.query_engine.router_query_engine import RouterQueryEngine
from llama_index.selectors.llm_selectors import LLMSingleSelector
# get list_query_engine and vector_query_engine
....
# define tool over summarization/vector query engines
list_tool = QueryEngineTool.from_defaults(
query_engine=list_query_engine,
description='Useful for summarization questions related to Paul Graham eassy on What I Worked On.',
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description='Useful for retrieving specific context from Paul Graham essay on What I Worked On.',
)
# define query engine
query_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[
list_tool,
vector_tool,
]
)
# ask summarization question
query_engine.query('What is the summary of the document?')
# ask fact-based lookup question
query_engine.query('What did Paul Graham do after RISD?')Additional Use Cases / Tutorials
The router query engine can be used in a variety of downstream use cases. We highlight them below.
Financial Analysis
For instance, the router can be used for financial analysis of yearly SEC 10-k filings. We design a query engine that can decide whether to look within the index of a 10-k filing for a given year, or to look across different documents to compare/contrast similar sections. More concretely, the router can “route” between different vector indices or to a graph structure that can perform compare/contrast queries.
This tutorial can be found here.
Joint Semantic Search/Summarization
Another basic example is to design a router that can route to either a query engine that can perform a semantic search or a query engine that can perform summarization.
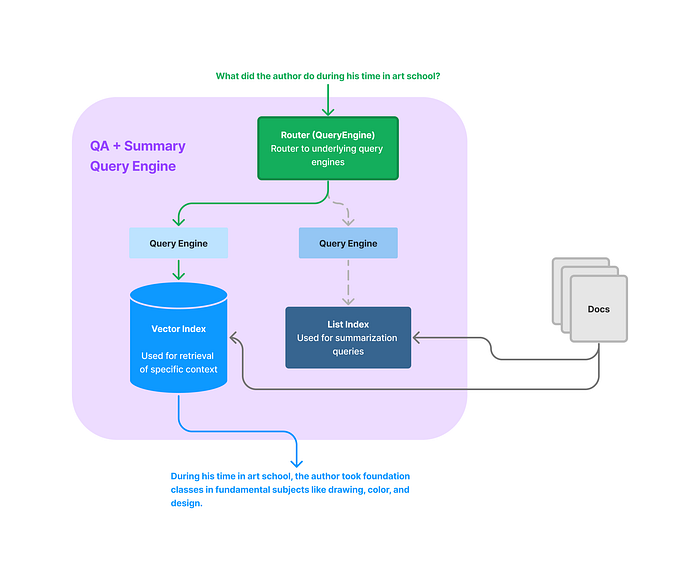
We package this entire system into a QASummaryQueryEngineBuilder class that you can deploy over any set of documents.
Take a look at the tutorial here.
Extension: Retrieval-Augmented Routing
As the number of query engines gets large, it makes sense to store the metadata for these query engines as part of an index as well. This allows us to hypothetically “route” a query to hundreds/thousands of query engines / data collections. We’re naming this Retrieval-Augmented Routing (RAR) — in a similar spirit as Retrieval-Augmented Generation, RAR uses a retrieval model to help with decision-making over large amounts of data.
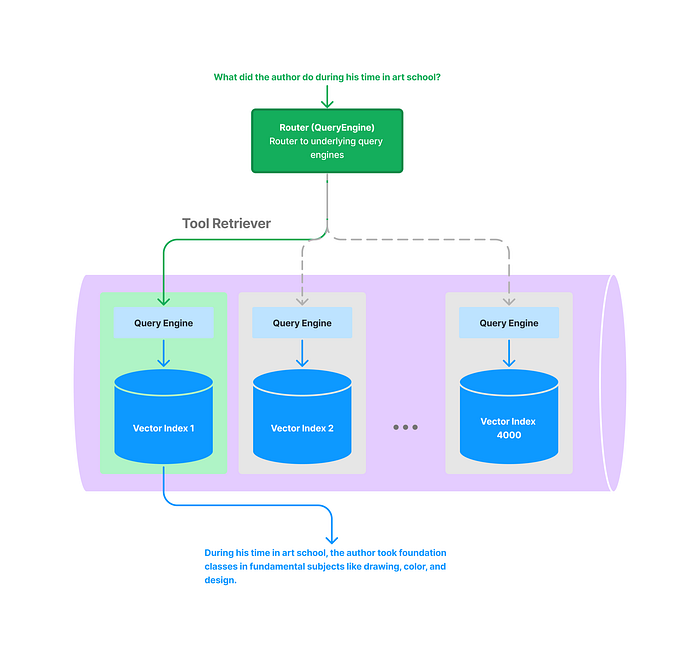
The key idea here is that we store the entire set of “choices” for the router in some collection, and define a retriever class over that collection: a RetrieverRouterQueryEngine .
For instance, we can store choices in a vector index, and define a retriever over that index. This allows the router to choose between an arbitrary number of choices. Besides embedding-based lookup, you’re free to define whatever retriever class you’d like over the router choices! For instance, keyword lookup, LLM-based lookup, and more.
Here’s a code snippet of how to use the RetrieverRouterQueryEngine :
from llama_index.query_engine.router_query_engine import RetrieverRouterQueryEngine
# define "Node" objects corresponding to different query engines
list_index_node = Node(
"Useful for summarization questions related to Paul Graham eassy on What I Worked On.",
doc_id="list_index"
)
list_query_engine = list_index.as_query_engine(
response_mode="tree_summarize", use_async=True
)
vector_index_node = Node(
"Useful for questions around the author's education, from Paul Graham essay on What I Worked On.",
doc_id="vector_index"
)
vector_query_engine = vector_index.as_query_engine(
response_mode="tree_summarize", use_async=True
)
# define mapping from node to query engine
def node_to_query_engine(node: Node):
"""Convert node to query engine."""
# NOTE: hardcode mapping in this case
mapping = {
"list_index": list_query_engine,
"vector_index": vector_query_engine
}
return mapping[node.get_doc_id()]
# create an outer "tool" index to store the underlying index information
tool_index = GPTVectorStoreIndex([list_index_node, vector_index_node])
# get retriever
tool_retriever = tool_index.as_retriever(similarity_top_k=1)
# define query engine
query_engine = RetrieverRouterQueryEngine(
tool_retriever,
node_to_query_engine
)For an interactive walkthrough, check out our Colab notebook. For more details, check out our class definition.
Looking Ahead
The router abstraction is currently a very simple but powerful interface; it takes in a set of query engines + descriptions, and decides which query engine to use.
There are extensions to this that would make routing more sophisticated, effectively adding agent-like behaviors over your data.
- Non-LLM-based routing. Routing to query engines not with LLM calls, but with other (faster?) techniques like embedding lookup.
- Routing to not only one query engine, but multiple query engines using a decision heuristic. This can be implicitly supported by having each router maintain a retriever class, and use the retriever class itself (which could use an index to store state) to select the set of candidate nodes. For instance, we could use a vector index retriever to retrieve a set of candidate nodes by top-k lookup, or we can use a keyword index retriever to retrieve a set of candidate nodes by keyword matching. These nodes would then be the nodes to route to.
- Incorporating not only automatic “selection” of a query engine, but also the automatic determination of which parameters the query engine should use (similar to LangChain’s Structured Tools on the agent side).
- Adding multi-step reasoning capabilities. An outer query engine could first break down a complex question into simpler ones, and query the router (which would then query other query engines) in sequential steps. LlamaIndex offers an initial version of this with the
MultiStepQueryEngineabstraction (has relationships with Chain-of-thought Prompting).
There are also some open challenges that we’d need to address in order to make this abstraction more production-ready:
- Latency: Adding any additional LLM call inherently incurs additional latency cost.
- Accuracy: If the router makes a wrong decision, then the wrong query engine will be picked, and the final result will likely be wrong. We’ve empirically noticed that many models pre-GPT -4 are prone to picking the wrong decisions if the text description isn’t carefully tuned. An open question is providing recourse for the model.
At a high level, our router abstraction is just one step towards building a sophisticated query interface over your data using LLMs. We look forward to continuing iterating upon this abstraction and coming up with new ones in order to best realize this vision.