LlamaIndex 0.6.0: A New Query Interface Over your Data
The central mission of LlamaIndex is to provide an interface between Large Language Models (LLM’s), and your private, external data. Over the past few months, it has become one of the most popular open-source frameworks for LLM data augmentation (context-augmented generation), for a variety of use cases: question-answering, summarization, structured queries, and more.
We’re excited to announce LlamaIndex 0.6.0: we’ve made some big changes to the LlamaIndex API that we believe will make it easier for developers to customize their query logic and define their own components.
LlamaIndex 0.6.0 makes some fundamental changes in the following areas:
- Decoupling State from Compute: We’ve separated our abstractions to more cleanly decouple state (data + indices) with compute (retrievers, query engines).
- Progressive Disclosure of Complexity: We want LlamaIndex to serve both the needs of both beginner users and advanced users. We’ve introduced a new developer-friendly low-level API that emphasizes composability and makes the interfaces clearer, so that it’s easier to implement your custom building blocks. In this blog post, we’ll discuss the key abstractions of LlamaIndex, highlight the API changes, and discuss the motivation behind them.
- Principled Storage Abstractions: we rewrote our storage abstractions to be much more flexible (to store both data and indices), and extensible (generalize beyond in-memory storage).
Decoupling State from Compute
We’ve redesigned LlamaIndex around 3 key abstractions that more cleanly decouple state from compute.

- At the core of LlamaIndex, an
Indexmanages the state: abstracting away underlying storage, and exposing a view over processed data & associated metadata. - Then, a
Retrieverfetches the most relevant Nodes from anIndexgiven a query. - Lastly, a
QueryEnginesynthesizes a response given the query and retrieved Nodes.
High-Level API — Get Started in 5 Lines of Code
Using LlamaIndex out of the box is as easy as before, with just a few small syntax changes. This uses default configurations that are great to start with, so you can get started in just a few lines of code.
Old syntax:
index.query("Who is Paul Graham?")New syntax:
query_engine = index.as_query_engine()
query_engine.query("Who is Paul Graham?")Progressive Disclosure of Complexity
Progressive disclosure of complexity is a design philosophy that aims to strike a balance between the needs of beginners and experts. The idea is that you should give users the simplest and most straightforward interface or experience possible when they first encounter a system or product, but then gradually reveal more complexity and advanced features as users become more familiar with the system. This can help prevent users from feeling overwhelmed or intimidated by a system that seems too complex, while still giving experienced users the tools they need to accomplish advanced tasks.
In the case of LlamaIndex, we’ve tried to balance simplicity and complexity by providing a high-level API that’s easy to use out of the box, but also a low-level composition API that gives experienced users the control they need to customize the system to their needs. By doing this, we hope to make LlamaIndex accessible to beginners while still providing the flexibility and power that experienced users need.

Starting from simple to arbitrarily flexible, users can:
- Quick setup: Use the existing index classes to easily get a pre-configured query engine to perform retrieval & synthesis.
- Configure retriever and synthesis modes: Pass keyword arguments to easily configure the retrieval and synthesis modes in high-level API
- Configure & compose pre-built retrievers and query engines: Gain more control over query logic by using the low-level composition API
- Implement custom retriever and query engines: Further, customize by extending existing components or implementing your own.
Low-level composition API — Customize with pre-built components, or build your own components
For those who need more control over the details, we’re introducing a new low-level composition API that allows you to customize existing components or define your own components. This gives you exactly the amount of low-level control over the details that you need, together with high-level convenience and under the hood optimization.
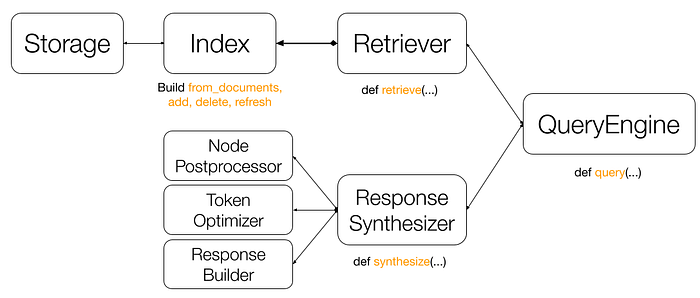
The core components are:
- Index: maintain the state of processes documents (i.e. Nodes). It can also be understood as a view of a collection of data, along with useful metadata that facilitates retrieval and response synthesis.
- Retriever: maintains the logic for fetching relevant Nodes from an Index. It is often defined for a specific index.
- Response synthesizer: manages the compute for generating a final response given retrieved Nodes. Its core component is the response builder, but can be optionally augmented by additional components e.g. node post processors and token optimizers to further improve retrieval relevancy and reduce token cost.
- Query engine: ties everything together and exposes a clean query interface. It can optionally be augmented with query transformations and multi-step reasoning to further improve query performance.
Here’s an example to showcase the full flexibility:
index = GPTSimpleVectorIndex.from_documents(documents)
# configure retriever
retriever = VectorIndexRetriever(
similarity_top_k=3,
vector_store_query_mode=VectorStoreQueryMode.HYBRID,
alpha=0.5,
)
# configure response synthesizer
synth = ResponseSynthesizer.from_args(
response_mode='tree_summarize',
node_postprocessors=[
KeywordNodePostprocessor(required_keywords=['llama']),
],
optimizer=SentenceEmbeddingOptimizer(threshold_cutoff=0.5),
)
# construct query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=synth,
)
query_engine.query("Who is Paul Graham?")Principled Storage Abstractions
Since LlamaIndex acts as an interface between LLM’s and your data, we need strong abstractions to both manage existing data (within a storage system), as well as any new data that we define (such as indices, other metadata). We rewrote our storage abstractions to more flexibly ingest different types of data, and to be more amenable to customization.
The diagram below shows our new storage architecture.
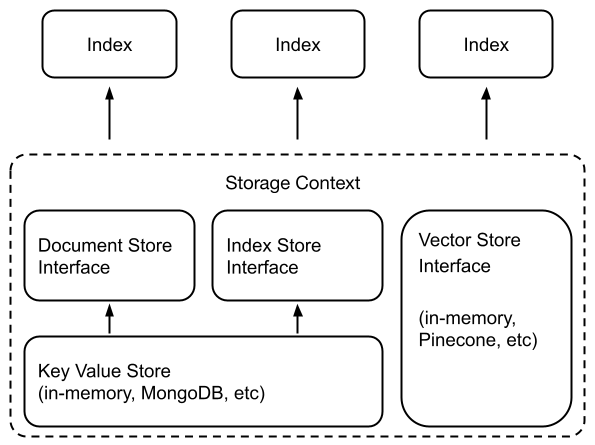
At the base layer, we need storage abstractions to store any data. We define a new Key-Value Store at this layer — a layer around any system that supports key-value storage (in-memory, filesystem, MongoDB, object storage, and more).
From here, we then define Document Stores and Index Stores:
- Document stores: where ingested documents (i.e., Node objects) are stored.
- Index stores: where index metadata is stored
How do Vector Stores Fit In?
Many vector stores provide storage capabilities for the raw data (e.g. Pinecone, Weaviate, Chroma); and all of them implicitly provide an “index” — by indexing embeddings, they expose a query interface through similarity search.
LlamaIndex provides robust storage abstractions with many vector store providers. Our vector store abstraction operates in parallel with our base KV abstractions, and with our document and index store abstractions.
An Index Is a Lightweight View Of your Data
A fundamental principle that’s highlighted with this change is that an index is just a lightweight view of your data. This means that defining a new index over your existing data does not duplicate data; a new index is akin to defining metadata over your data.
- Defining a vector index will index your data with embeddings.
- Defining a keyword index will index your data with keywords.
Defining metadata/indices over your existing data is a crucial ingredient to allow LLMs to perform different retrieval/synthesis capabilities over your data.
Conclusion
For comprehensive information and more details about the updated LlamaIndex API, please feel free to visit https://gpt-index.readthedocs.io/en/latest/.
We hope these changes will make it easier for you to use LlamaIndex and customize it to your needs. As always, if you have any questions or feedback, please don’t hesitate to contact us.
Best regards,
The LlamaIndex Team

