System Design Series: Apache Kafka From 10,000 Feet
Let’s look at what Kafka is, how it works, and when we should use it!

I have recently been reading more and more about Kafka and how it works under the hood. While that is very interesting, I realized there is quite a bit I didn’t know about Kafka under the hood.
Moreover, it seemed wrong to start discussing how Kafka works without exploring what it is and why it is even required.
So, I will do that in this article. I want to talk about Kafka, where and how data stream systems can be with it, instead of with a message broker (like RabbitMQ), and how to use Kafka with a little sneak peek into its internals. In the future, I’d like to talk more about the inner workings of Kafka, when it works, and most importantly, when it doesn’t, but more on that later.
If you don’t know anything about Kafka or know very little, this is my best attempt at explaining it to you.
Now that we are done with the intro, let’s dive into Kafka!
Problem Statement
Let’s look at the problem that inspired Kafka in the first place on Linkedin. The problem is simple: Linkedin was getting a lot of logging data, like log messages, metrics, events, and other monitoring/observability data from multiple services. They wanted to utilize this data in two ways:
- Have an online near-real-time system that can process and analyze this data.
- Have an offline system that can process this data over a longer period.
Most of the processing was done for analysis, for example, analyzing user behavior, how users use LinkedIn, etc.
This is a pretty common problem, but if you haven’t faced it, a simple use case could be to drive recommendations. If a user searches for a particular company on LinkedIn, your ad engine should catch that and, in near-real-time, suggest jobs in that company to the user in ads. Your offline systems can probably use this information to email the user when that particular company posts a job. Moreover, your analysis teams can find out how users search for companies and how they use the LinkedIn platform to find jobs.
The problem is easy to understand, but the solution can seem pretty complex. This is because the problem itself has so many constraints and requirements. Here’s some examples:
- The system should be highly scalable. Popular products can generate tens or hundreds of TBs of data in events, metrics, and logs daily! This requires an almost linearly scalable distributed system to handle such high throughput.
This is important because we need to support the extremely high traffic. Easily hundreds of thousands of messages per second. In fact, this blog post by LinkedIn in 2015 talked about ~13 million messages per second! This is impossible in a single node, so the system must be distributed. - It should allow “producers” to send messages and “consumers” to subscribe to certain messages. This is important since there can be multiple consumers(like the online and offline systems we discussed) to the same message, and messages are generally asynchronous.
Consumers should also be able to decide how and when to consume messages. For example, in the problem we discussed, we’d want one consumer to consume messages as soon as possible and the other to do it every few hours. - Messages can be immutable (there is no need to delete log data after all), transaction-like semantics, and complex delivery guarantees aren’t important requirements.
TLDR; The above is a very high throughput system that can get messages from point A to point B, but speed isn’t important, and there is no need for complex mechanisms or transactions — just the simplest way to get a ton of bytes from producers to multiple consumers.
Why Message Brokers Don’t Qualify
For those that know about message brokers(like RabbitMQ, ActiveMQ, etc.), you probably think message brokers could solve this problem. But they can’t. Let’s take RabbitMQ as an example and try to find out why it would fail.
Message batching
Since we are pulling a lot of messages on the consumer, it doesn’t make sense to pull messages one by one. Most of the time, you’d want to batch messages. Otherwise, most of your time would be wasted on network calls.
Since message brokers aren’t really meant to support such high throughput, they generally don’t provide good ways to batch messages.
Different consumers with different consumption requirements
If you remember, we discussed having two types of consumers, one online system which processes messages in real-time and the other an offline system that might want to read messages received in the past twelve or twenty-four hours.
This pattern doesn’t work with most message brokers or queues. This is because some message brokers, like RabbitMQ, use a push-based model, pushing messages from the broker to the consumer. This leads to lesser flexibility for the consumer since the consumer cannot decide how and when to consume messages.
Messages aren’t also stored for a long time in queues. Since message brokers aren’t built for large queues, message persistence is pretty limited. Increasing the size of the queue often comes with performance issues.
Due to a lack of flexibility for the consumer in consumption (lack of support for batching messages, or consuming older messages, for example) and a generally push-based model, it’s more difficult to write consumers who want to consume messages differently.
Small, simple messages
Message sizes are generally larger in most message brokers. This isn’t a bug, but it’s by design. Message brokers often support many features, like different options for routing messages, message guarantees, being able to acknowledge every message individually, etc., which leads to large individual message headers.
Large messages are fine as long as you don’t have a lot of them and you don’t have to store them, but that is precisely what we want to do in our system!
Distributed high-throughput system
One of the most important requirements is very high throughput. We want to support hundreds of thousands of messages per second, even going up to millions per second. Running this system in a single node is infeasible.
We need a distributed system that can support this throughput, which many message brokers don’t.
To be fair, RabbitMQ does support a distributed cluster, but its performance is much lower than Kafka's. This is because it isn’t meant to handle this high scale.
With claims like these, I should provide at least some resources, so I found a few performance-testing posts. This one by Confluent was pretty in-depth.
TLDR; Message brokers aren’t typically built to support high throughput messaging or run in large clusters.
Large queues
Message brokers often have varying support for large queue sizes. This depends on the message broker you are using and your configuration, but the internet is filled with people facing issues with message broker queue sizes.
Let’s Look at a System That Solves This Problem: Kafka
Just a quick heads up, I will be talking about Kafka without Zookeeper.
Topics
Topics are simply a stream of messages. Producers send messages to topics, and consumers poll them for messages.
You’d generally send similar messages on the same topic. For example, you could have one that receives all user clickstream events and one for logs, etc.
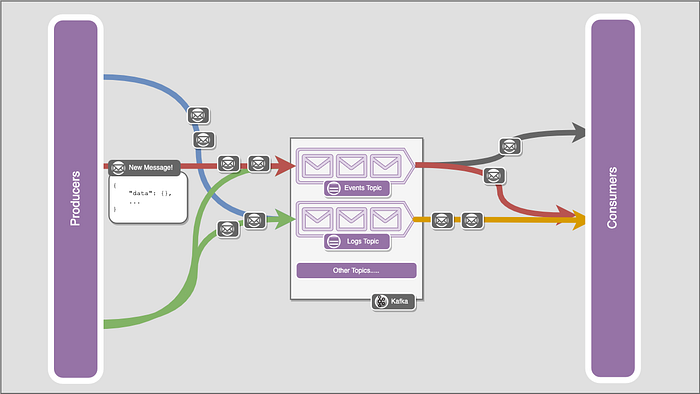
Consumers
A consumer is simply an application that wants to listen to a topic. It continuously polls the broker about any messages on the topic. With each polling request, the consumer specifies the last message it received and some other configurable parameters.
Producers
Producers are applications that produce a message and publish them to the queue. Publishing messages is pretty simple: specify a topic, a message, an optional key, and optional metadata, and send it to the broker.
Consumer groups
Consumers would typically be a part of a consumer group. Instead of a consumer listening to a topic, generally, a consumer group would listen to a topic. The consumer group comprises multiple consumers, and anyone will receive the message.
For example, let’s suppose you create a consumer group with four consumers in it, and you start listening to a topic. When a new message is published on the topic, any of the four consumers in the consumer group would receive the message.
Why is this important? Because of parallelism!
Generally, a single consumer would not be able to process many messages, so you’d need multiple consumers to handle messages. That way, you can support a higher throughput of messages.

Let’s look at an example to understand this better.
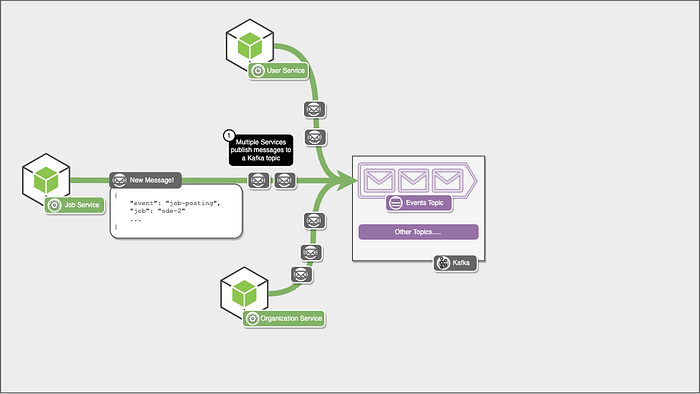
Let’s go back to our earlier example, where various services publish events to a Kafka topic. The events could be related to user or organization activity, such as a user searching for a company or a new job posting. There are two types of consumers listening to this. One is a recommendation service that processes these events and updates data in its database about future recommendations that must be provided to the user. The other is a script that is run once every 24 hours to provide insights into how users use our platform.
Let’s see what this looks like in action. First, let’s start small, with a few services pushing messages to a Kafka topic.
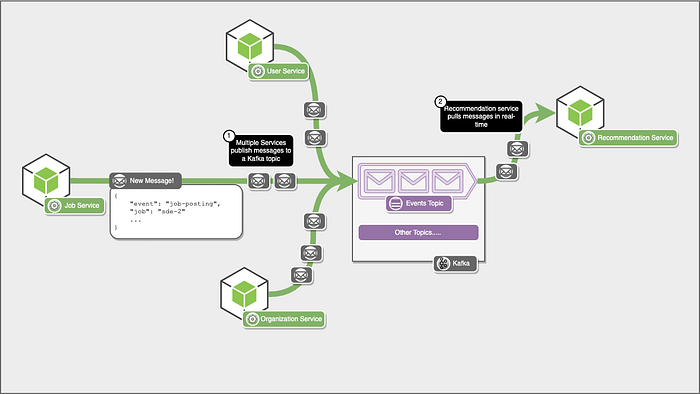
Now, let’s add the recommendation service that listens to this events topic in real time. This service does some processing and maybe puts some data in some database, but we don’t need to care about what exactly it does immediately.
However, we are getting many messages, and a single consumer in the Recommendation Service cannot keep up, so we must add more consumers. This is where consumer groups come in. Multiple consumers can be a part of the consumer group, and all the messages get divided into multiple consumers.
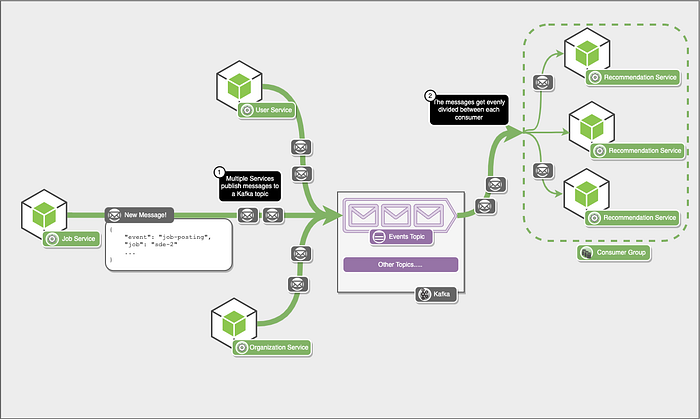
Now, we don’t need to worry about a high number of messages!
Partitions
Looking into topics, you’d see every topic is divided into a configurable number of “partitions.”
Every single message in a topic is sent to exactly one partition.
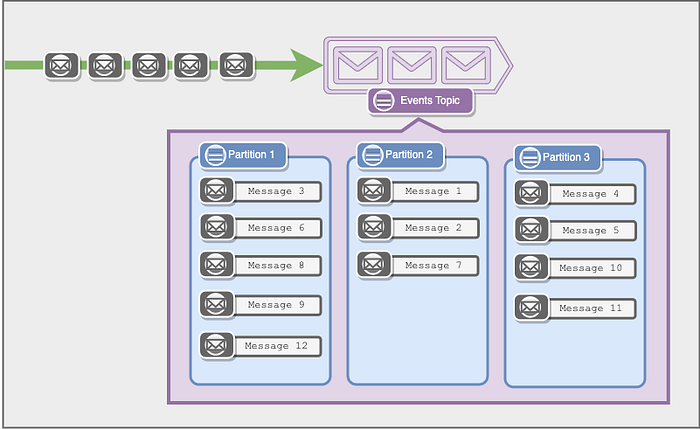
Depending on your configuration and the message, this can be either based on the message's key or in a round-robin fashion. Regardless, what’s important is that a message sent to a topic eventually goes into a single partition.
And partitions aren’t very complex. They are an append-only-like system to store messages. Think of them like a log file and the message like lines in a log file.
Consumers from a consumer group aren’t directly listening to topics. Instead, they listen to zero, one, or more partitions of the topic. Every consumer gets messages only from the partitions it listens to.
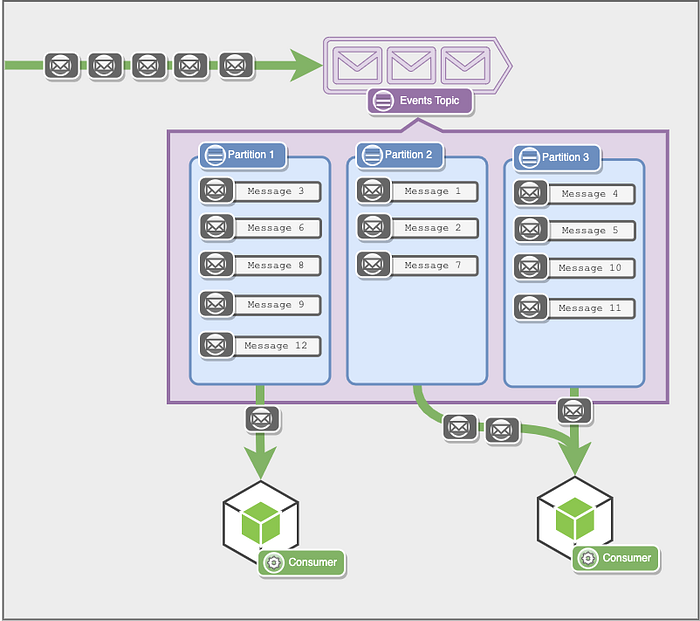
Since every consumer is assigned its own partitions on startup, consumers don’t need to discuss which messages have already been consumed. This is also helpful as it helps to scale Kafka linearly since adding more partitions/nodes doesn’t increase the work or communication between existing partitions/nodes. These partitions are often in different brokers running on different machines.
Why Would Kafka Work When RabbitMQ Didn’t?
Distributed high-throughput system
Kafka stores messages in partitions, which are stored in brokers which often run on multiple machines. All of these brokers together form a cluster. This means that it is very easy to run Kafka as a distributed system where multiple consumers from a consumer group listening to different partitions in a topic can essentially work in parallel.
This also comes with downsides, however. Since messages are stored in a log-type format, and consumers are simply at a particular position in this log, it isn’t possible to individually acknowledge a message. Acknowledging any message automatically means acknowledging all the messages in this partition that came before this one. Messages are also immutable so deleting them isn’t an option either. Since messages are routed to their own partitions from the start, there is no guarantee that messages in different partitions will be received in the order they were sent.
The advantage of a system is that it is simple, requires minimal communication between nodes, is linearly scalable, and can work as part of a large cluster.
Small, simple messages and large topics
Messages are generally small in size, headers are simple, and messages don’t have much metadata attached to them. Queues can easily become as large as you want them to be, and you can even set message retention to infinite.
Kafka doesn’t store messages in memory, so your underlying secondary storage size limits the topic size.
Message batching
Consumers can consume messages in large batches with various configuration options on how they want to receive messages.
Different consumers with different consumption requirements
Kafka supports a variety of ways in which consumers can consume messages. Consumers can listen to messages in real-time, wait and read messages in batches, read in long intervals, or even reread messages.
This gives consumers a lot of flexibility to decide when and what to read. For example, let’s consider the example we have been discussing till now, where we have one system that reads messages in real-time and one which reads messages maybe once in 12 hours or once a day in batch.
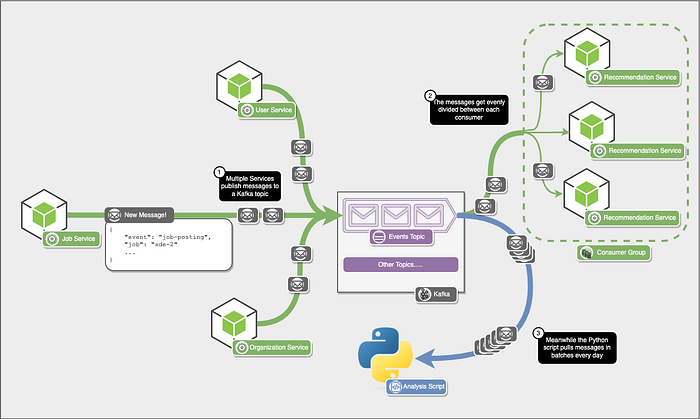
This type of architecture is possible with Kafka since we can have configurable persistence on a topic and read in batches. So, while our Node.js consumer group reads messages in real-time, our Python script runs once every few hours and reads messages in batches. Messages in a topic also typically don’t slow down the topic since they are written on disk right from the start.
Excerpts From the Original Kafka Paper
I like to read the origins of the technology since it helps me understand more about “why” it was originally developed. This is the original Kafka paper, and I recommend you give it a read.
If you don’t want to, then let me point out a few interesting sections from the paper,
Trading complex features for high throughput
“First, there is a mismatch in features offered by enterprise systems. Those systems often focus on offering a rich set of delivery guarantees. For example, IBM Websphere MQ [7] has transactional supports that allow an application to insert messages into multiple queues atomically.
The JMS [14] specification allows each individual message to be acknowledged after consumption, potentially out of order. Such delivery guarantees
are often overkill for collecting log data.”
The above quote shows that there is no perfect system. Each system needs to decide what it wants and what it doesn’t. Here, they explained how complex delivery guarantees aren’t required for their use case and can be traded off for higher throughput.
Simple storage
When reading about these systems, I often felt disconnected about how they actually store this data. For example, the primary job of a database is to store data persistently, but have you ever wondered how? where?
At the end of the day, the database application sees the same file system and OS API you and I do when we open a file manager. Just like us, it can create files and read them.
But how does it store a table in a file? Where is that file? Can I cat it? Can I edit it directly?
Kafka’s paper had this really nice paragraph that reminded me that these systems that seem so complex are still simply writing to the disk and the brains of the system aren’t how they write to the disk but what they write and when.
“ Kafka has a very simple storage layout. Each partition of a topic corresponds to a logical log. Physically, a log is implemented as a set of segment files of approximately the same size (e.g., 1GB). Every time a producer publishes a message to a partition, the broker simply appends the message to the last
segment file.”
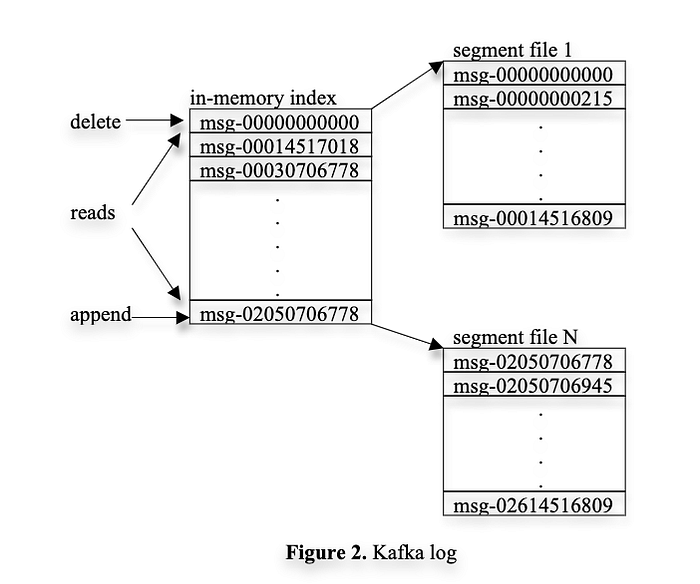
Simple storage format
Since Kafka doesn’t provide strong guarantees, query mechanisms, or any feature except reading and writing, it can store messages much more simply. It doesn’t require complex indexes or large headers with each message.
“Second, Kafka has a more efficient storage format. On average, each message had an overhead of 9 bytes in Kafka, versus 144 bytes in ActiveMQ. This means that ActiveMQ was using 70% more space than Kafka to store the same set of 10 million messages. One overhead in ActiveMQ came from the heavy message header, required by JMS. Another overhead was the cost of maintaining various indexing structures. We observed that one of the busiest threads in ActiveMQ spent most of its time accessing a B-Tree to maintain message metadata and state.
Finally, batching greatly improved the throughput by amortizing the RPC overhead. In Kafka, a batch size of 50 messages improved the throughput by almost an order of magnitude.”
I am not saying it was bad that ActiveMQ decided to have large headers and complex data structures for its indexes, but that was what it traded for its features.
Conclusion
Kafka isn’t perfect. Neither is RabbitMQ or any technology, for that matter. Kafka wanted to support a certain use case with very high throughput that was easy to run in a distributed system with few features.
I don’t know why I keep coming to the Rolls-Royce vs F1 racecar example, but I feel it fits so well here.

Kafka is like an F1 racecar. It's super fast but doesn’t have many features (maybe not even an air conditioner). RabbitMQ is like a Rolls-Royce Phantom. You get a lot of features, and it's super convenient to work with, but when you want absolute raw performance, the F1 will leave the Phantom far behind. But then again, you can’t really drive an F1 car on the road.
So, each serves its own purpose. Each has certain features it chose to prioritize and some that it had to give up.
It was fun to look at Kafka, but it really wasn’t my sole intention with this post. I feel Kafka is pretty interesting in general, and I want to dive deeper into it in the future. So, if you have managed to stay around so far, stay tuned for more.
Also, if you enjoyed this, I reckon you’d like this story as well, where I talk about Dynamo. You may also enjoy my articles on Cassandra.
In the future, I’ll probably continue this series and discuss more about Kafka. If you have any suggestions or feedback, let me know in the comments!

