System Design Concepts: Dynamo, 16 Sheets of Paper That Changed the World
Learn how to use the Dynamo Family, AWS DynamoDB, Cassandra, and SimpleDB in your system design

Quick Introduction Before We Begin
Back in 2004, Amazon was running a large distributed Oracle database cluster. Imagine a lot of servers, running a lot of bulky closed-source proprietary software not really focused on scale and availability. They were pushing the limits of the commercial database at the scale they were at.
It is important to understand this was a different time. Distributed systems weren’t common, relational databases served as the only major OLTP databases, and most importantly, there weren’t enough people or data online.

At this point, Amazon’s services were at the very cusp of pushing the boundaries of the scale of traditional SQL databases at the time and they decided that they needed a long-term sustainable solution to continue to grow at the pace they were growing.
Relational databases are complex systems. They give you a lot of flexibility in the type of queries you can run, give you strong ACID compliance, build relationships among tables, and the ability to JOIN tables. These features are not free and come at a cost. The cost is often limited scaling, availability, and lower performance.
As Werner Vogels, CTO of Amazon explains here, they evaluated that 70% of their operations were based on just primary keys and another 20% didn’t utilize any type of JOINs. So, they were using relational databases but they realized they didn’t really need most of the advantages relational databases provided. And furthermore, they were facing difficulty in horizontally scaling their databases.
So, they internally built an in-house database called “Dynamo” and tested it for a few years. In 2007, they publicly released a whitepaper, “Dynamo: Amazon’s Highly Available Key-value Store,” to help others facing similar scalability issues in relational databases.
This paper became popular and became a driving force behind NoSQL databases, which are now an important part of the tech stack of any large tech organization. As Werner Vogels describes it, “The Dynamo paper was well-received and served as a catalyst to create the category of distributed database technologies commonly known today as ‘NoSQL.’”
Dynamo was able to handle massive amounts of scale, with single tables being able to serve tens of millions of requests per second. The original Dynamo was able to serve 12.9 million requests per second back in 2017. I am sure the much more beefed-up present-day DynamoDB is probably pushing the limits even further.
Dynamo ended up inspiring many of the most popular databases in existence today, such as AWS’s SimpleDB and DynamoDB, and Cassandra. Most of these databases, like Cassandra, and DynamoDB ended up being very similar to the Dynamo paper and usually had the same pros and cons. Understanding the Dynamo paper will also help you better understand this Dynamo family of databases.
While reading through the success, the performance, and the almost fairytale-like story of what seemed like the most amazing database to ever exist, I wondered why are other databases still in use? What did the engineers at Amazon end up trading off for these massive gains in performance, scale, and availability? What does infinite scale actually cost? And is it affordable?
Setting the Stage
Quick overview of the system Dynamo describes
Dynamo describes a distributed database system that is built of multiple nodes.
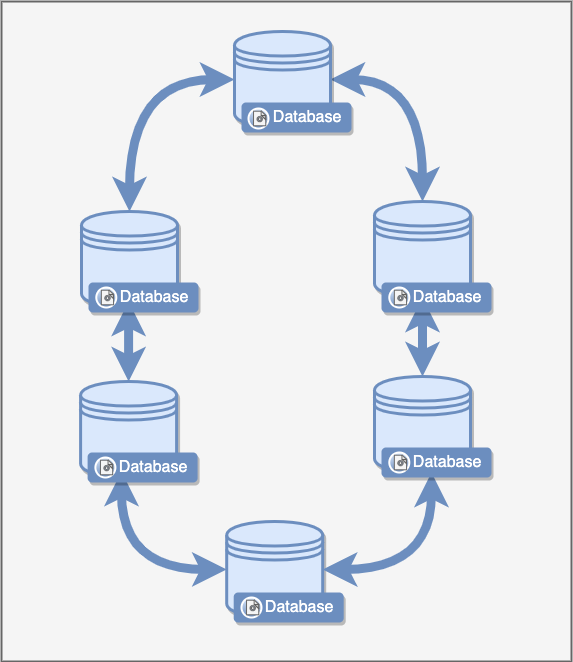
These databases can run in complete isolation from one another and in fact be physically located in different parts of the world.
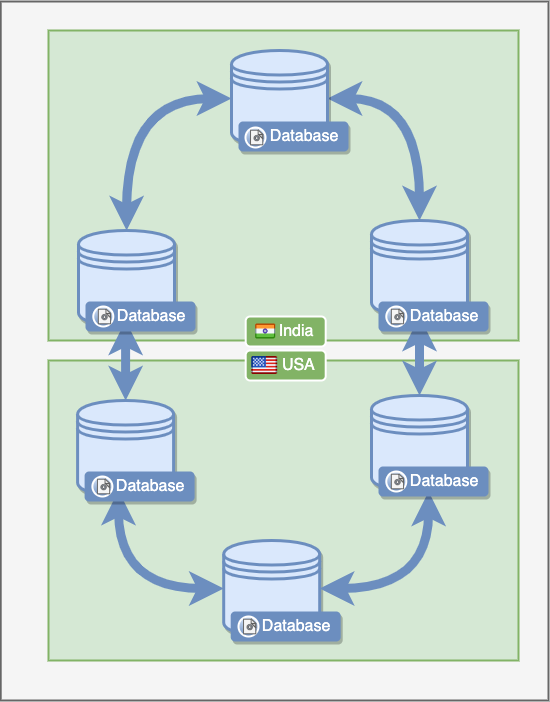
It describes that the system would be a master-less system. This means all the nodes are homogeneous and behave the same.
All data would be distributed in these identical nodes, and then replicated among them as well. For example, if I had to store two rows of, let’s say employee data, dynamo would internally store it as the following:
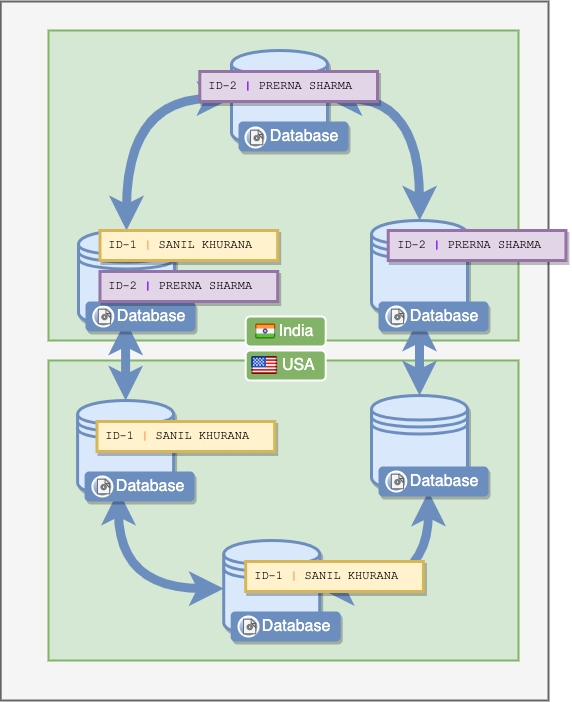
Notice how data can even be replicated on different continents!
To ensure performance, the cluster would often not wait for all nodes to actually write the data. For example, to write a new employee, of the ID 3, Dynamo might wait for a single node to actually acknowledge the write, and while others aren’t even done writing the data to disk, Dynamo might return a response to the user saying that the write is complete.
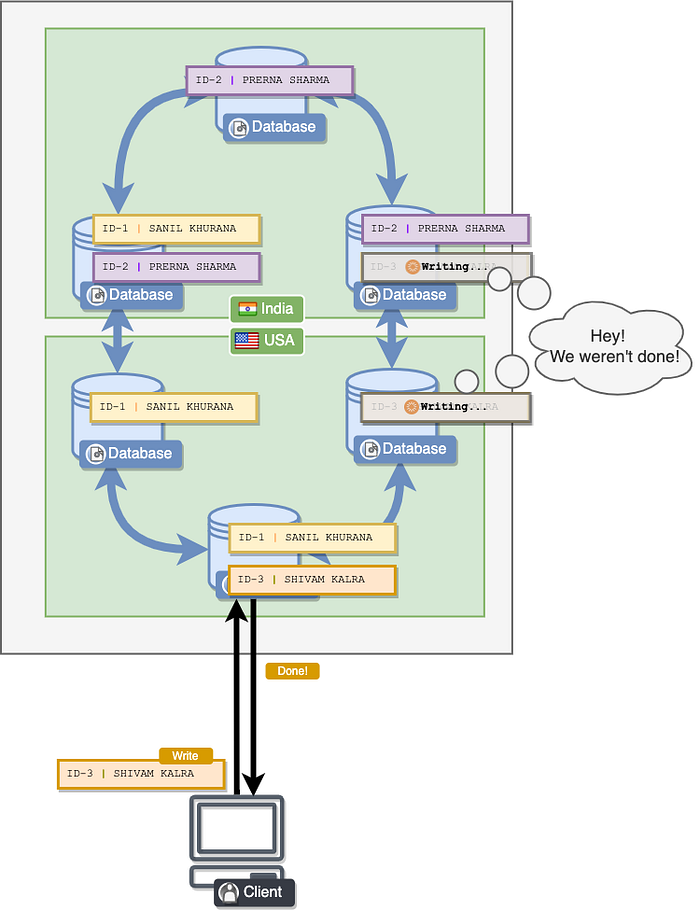
This means that your entire database cluster can be in an inconsistent state, where some nodes may store certain rows and others might not. For example, in the above diagram, two nodes weren’t done writing a new row, while one of them was done. This means that the nodes in some sense, disagree with one another on whether the row exists or not. Don’t worry, this is normal.
Eventually, all the nodes would finish writing the new row and the cluster would be in a consistent state. This is an eventually consistent data model because the entire cluster eventually attains consistency.
Before I continue it is important to note the existence of this new entity, the cluster. Early in my career, I worked with a single Postgres database running on a single server so when I got introduced to the idea of a distributed data system, I struggled to understand the concept of a cluster.
To understand this better, don’t think of the nodes as individual nodes that you have to manage. Think of a completely new entity, the cluster. This cluster is comprised of these individual smaller and simpler database processes running on servers.
The cluster is in fact managing these nodes, taking care of their health, and their communication, bringing more nodes up when required, and taking nodes down when they aren’t required.
Kind of like a branch manager:
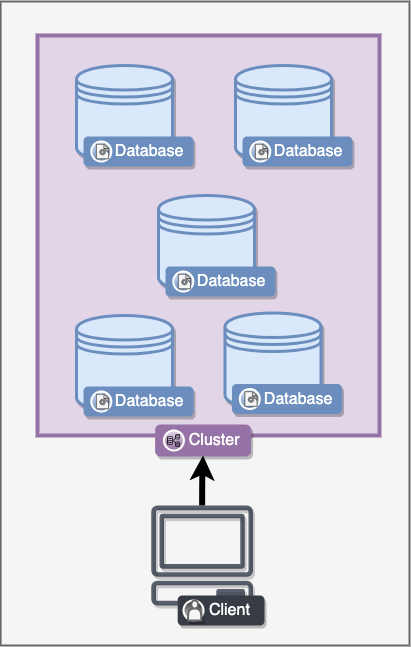
The nodes themselves are also aware of the cluster, and that they are a part of it. The nodes can talk to each other and discuss information related to the cluster.
You as a client would often interact with the cluster and often care about the characteristics the entire cluster exhibits, rather than the individual nodes. For example, the cluster can be in an inconsistent state, because some nodes would store updated data while some may not.
How the Dynamo Paper Changed the World
Werner Vogels, CTO of Amazon said,
“The Dynamo paper was well-received and served as a catalyst to create the category of distributed database technologies commonly known today as “NoSQL.””
Dynamo inspired many other NoSQL databases and created a framework for a large-scale highly available, distributed datastore. It has been cited 2,000+ times and has influenced how distributed data stores work in a variety of databases.
Simply put, simple relational databases would have simply been unable to sustain the write capacity of modern applications. Most big tech companies like Netflix, Apple, Discord, AirBnB, and many more use one of the Dynamo family of databases(DynamoDB, Cassandra, etc.).
“Changing the world” might be an overstatement, but the Dynamo paper has definitely been one of the most influential whitepapers, and has impacted many of the existing large-scale tech companies.
Key Takeaways and Trade-Offs
Key-value store
Dynamo presents a key-value data store, and this means that there is no support for tables, or for relationships, etc.
You can only store keys and their corresponding values. The key you use will be your partition key and this is the key Dynamo will use to figure out in which partition to put your data. Or, another way to look at it is, that partition keys decide which node your data will go to.
The partition key must be unique and to ensure equal distribution across nodes, it should be able to have a large set of values with roughly equal distribution.
For example, let’s say I have to store this data:
| ID | Name | Location
---------------------------------------------------------
| 1 | Sanil Khurana | Delhi
| 2 | Prerna Sharma | Delhi
| 3 | Shivam Kalra | Bangalore
| 4 | Nilesh Jain | Delhi
| 5 | Hardik | ChennaiIf I were to choose the Location as the partition key, this would mean that each node in my cluster would be responsible for storing data related to a certain set of locations.
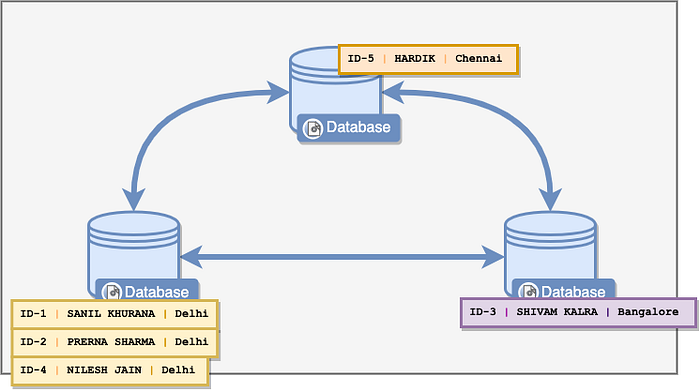
In the example above, you can see that each node was assigned to store a single location.
This already shows problems. Some locations are bound to be more popular than others, based on population and what locations your organization may be targeting. For example, your platform is being used more in Delhi than in Chennai. This leads to an unbalanced distribution of data across your nodes. Since all nodes are homogeneous, you are wasting the resources of nodes that aren’t storing a lot of data.
However, storing data based on an ID could be much better. Your application logic can assign an incremental ID or a random ID to each data item and you can partition your data on the basis of that ID.
Even though this data model is fairly simple, the Dynamo family of databases has evolved to support a much more complex data model. DynamoDB and Cassandra do support tables but it isn’t possible to query without the partition key.
They also support basic levels of sorting, limiting the results returned, etc. In short, iterations of the Dynamo paper are able to support a much richer model, though it lacks the features that relational databases generally come with.
Choosing your partition key has other nuances as well. Dynamo family of databases support a weaker ACID model, where some basic level of isolation or transactions or consistency is achievable. These are generally possible when the rows you are interacting with are on the same partition.
So TL;DR, the data model for Dynamo is very simple, with fewer bells and whistles. DynamoDB and Cassandra support a much richer data model, but still without any relations, relationships, flexible queries, etc.
Choosing your partition key is a very important part of deciding your data model and requires much more thought than with relational databases.
Less flexible query model
Dynamo exposes a much simpler, and more restricted query model.
It only exposes two functions, get(partition key) and put(partition key, object). This means that there is no support for sorting data, limiting the number of rows returned, etc. that you’d usually find in relational databases.
However, as I explained before, Cassandra, and DynamoDB present a much richer model, with the ability to filter data(similar to WHERE in SQL), sort data, limit the number of rows, etc. They still have limitations, mostly due to the fact that data has to be stored in different nodes.
You’d generally be limited by your partition key, which if you haven’t realized it already, is very important.
Distributed
Dynamo works as a distributed system. Running it in a single node system just doesn’t make sense. If you are running Dynamo, chances are you are running tens if not hundreds of nodes, because this is where Dynamo shines.
Lack of ACID support
“Experience at Amazon has shown that data stores that provide ACID guarantees tend to have poor availability. This has been widely acknowledged by both the industry and academia [5]. Dynamo targets applications that operate with weaker consistency (the “C” in ACID) if this results in high availability. Dynamo does not provide any isolation guarantees and permits only single key updates.”
As the paper so eloquently puts it, Dynamo does not support ACID properties. Instead of supporting higher consistency, it presents an AP system that targets availability over consistency.
This makes sense. For a lot of applications, strict consistency may be important. This means that nodes in your cluster should always agree on the current state of data. If you are working with payment-related data, for example, it may be important to have strict consistency. Imagine if nodes in a cluster disagree on how much money is in your account. Some nodes would allow a debit transaction and some may reject it.
Strict consistency, however, comes at a cost. The cost is often availability, performance, and durability.
For most applications, it doesn’t matter if your data store is in an inconsistent state. For example, if some nodes believe a certain tweet has 2,000 likes, and some believe it has 2,001, it doesn’t matter that much. Some users may see 2,000, and some may see 2,001, but it hardly affects the user experience. Dynamo is built for these applications. Where consistency is not important and availability and performance are paramount.
On a side note, Dynamo does give you the option to have tunable consistency. In simple terms, you can define what level of consistency you want. This has more nuances to it, but it is possible to have strict consistency albeit at a cost of availability. This concept requires a bit more depth so, in the interest of time, I’ll skip it for now. However, if you want me to write more about this, let me know in the comments!
Linearly scalable write performance
When you horizontally scale relational databases, you don’t get the full power of all of the nodes in the system. This is because relational databases running in a horizontally scaled cluster, especially when each node stores only a part of a relation, and not the entire relation, would constantly talk to each other for the simplest of queries.
For example, let’s say you have this simple customer table, sharded between three nodes on Postgres, so each node is storing some of the rows of the entire table. Since you are storing email addresses and phone numbers for each row, you’d also want to ensure these are unique across the entire table (again, which spans multiple nodes).
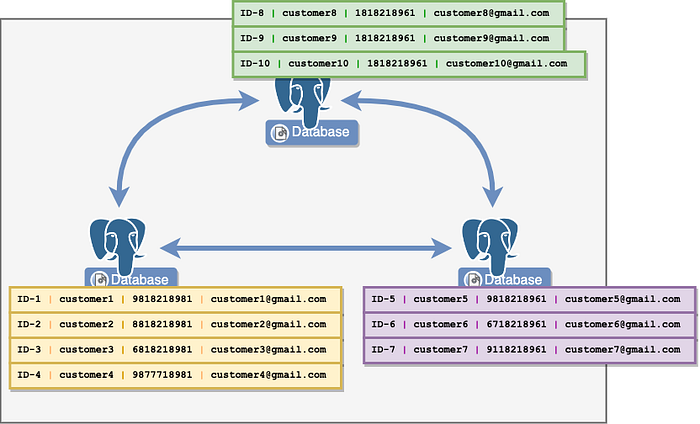
If you had to write a new customer, you’d first have to decide which node to write it on, then check whether a customer with the same phone number or email address doesn’t exist on any of the other nodes, then write it.
While you are doing all this, you also need to ensure that no new customer is written on the other nodes as well, since two customers with the same email or phone could be written at the same time, and thus break the UNIQUE constraint. Now imagine if these nodes were physically far apart as well.
Even in such a simple scenario, it is already evident how complex sharding can be in relational databases. And how adding more nodes would increase the work for every existing node as well since now it needs to connect and talk and gossip to another node.
The reasoning behind Dynamo is simple. A single node cannot sustain the number of reads and writes that are required. The only way to resolve this is to have a multi-node system with horizontal scaling. Dynamo is meant to present a system that can easily handle hundreds, thousands, or even more nodes. It does so because it can linearly scale write performance.
So the goal should be, that adding a node doesn’t increase the work of the other nodes. Every node only communicates the required information and Dynamo doesn’t promise validation or UNIQUE constraints or other features that will add to the burden of the nodes in the system.
Netflix performed a lot of tests to understand how Cassandra(belonging to the Dynamo family of databases) performs as you increase the node count. This graph perfectly sums up the linear scale.
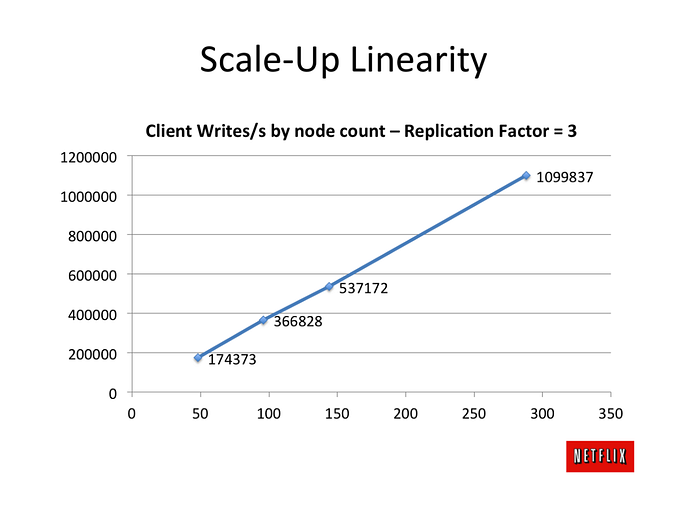
You can see how adding more nodes doesn’t decrease the performance of the other nodes.
Where to Use the Dynamo Family of Databases?
I think Werner Vogels really sums it up well:
“Our goal was to build a database that would have the unbounded scalability, consistent performance and the high availability to support the needs of our rapidly growing business.” — Werner Vogels
Dynamo and the Dynamo family of databases present an idea to store absolutely massive unimaginable amount of data with a consistent performance guarantee. It promises high availability, low latency, and linearly scalable write performance.
But it sacrifices the flexibility of its data model and querying capability, and lack of ACID support. It also presents a distributed system and would be useless running as a single node system.
I recently wrote in-depth about Cassandra here, and I had an analogy throughout the article that applies to Dynamo just as much.
Imagine Dynamo as a Lamborghini Huracan and the traditional relational database as the Rolls Royce Phantom. The phantom will give you more luxury, in this case, the luxury of the flexibility of your queries, and ACID properties but when you want to floor the gas and you want absolute raw performance, a Lamborghini Huracan will beat the Phantom hands down.
So, TLDR; use Dynamo when you want massive scale and availability in a distributed environment with consistent performance.
Interesting Quotations
An always writeable data store
“Dynamo is targeted mainly at applications that need an “always writeable” data store where no updates are rejected due to failures or concurrent writes. This is a crucial requirement for many Amazon applications.”
It is interesting how the above paragraph is worded in the paper. It emphasizes how Dynamo is built for writing and to always ensure that updates or failures are never rejected.
This philosophy of an always-writeable data store is present throughout the paper and was one of the main objectives of the system.
The emphasis on constant failure and how to handle it
“Dealing with failures in an infrastructure comprised of millions of components is our standard mode of operation; there are always a small but significant number of server and network components that are failing at any given time. As such Amazon’s software systems need to be constructed in a manner that treats failure handling as the normal case without impacting availability or performance.”
I really like the above quote and this being part of the introduction of the paper really sets the expectations from Dynamo. Being able to handle failure every day is part of Dynamo’s job requirements.
It also highlights how Dynamo’s key focus is availability and performance.
Gossiping
Dynamo is built to work in a distributed manner. At any point, there should be multiple nodes in the system storing data. This data is often replicated to multiple nodes. The nodes need to be aware of each other, each other’s health, and the system in general. There are a lot of interesting problems like load balancing, job scheduling, request routing, replica synchronization, handling failure, concurrency, etc. which require constant communication between the nodes.
Nodes talk to each other using a gossip-based protocol. This is a peer-to-peer communication method, which is in fact used a lot by database systems. I previously talked about this when talking about Redis here and when talking about Cassandra in my earlier post. The Wikipedia page on gossip communication is also an interesting read.
In short, think of the nodes as the average high school student, discussing an embarrassing outage of one of our nodes.
Versioning and conflict resolution
“Dynamo does not provide any isolation guarantees and permits only single key updates.”
This is interesting as, without isolation guarantees in a distributed system, it is possible for your datastore to have multiple versions of a single data item.
In fact, this is true for the database system the Dynamo paper describes. Dynamo, instead of falling back to guaranteeing isolation like traditional relational database systems, embraces the possibility of multiple versions.
This happens because an update needs to propagate the system asynchronously. This propagation can take a small amount of time. During this time, the data store would store multiple versions of the same data item. Dynamo uses the concept of vector clocks to determine versioning and tries to resolve versioning conflicts but it cannot always resolve them. In the cases when it can’t, it returns multiple versions to the user and leaves it up to the user to determine the right version.
The paper talks a lot about versioning and it’s a really fascinating read as to how they made these decisions, and what factors contributed to it.
It is important to understand that certain failure modes can potentially result in the system having not just two but several versions of the same data. Updates in the presence of network partitions and node failures can potentially result in an object having distinct version sub-histories, which the system will need to reconcile in the future.
This requires us to design applications that explicitly acknowledge the possibility of multiple versions of the same data (in order to never lose any updates).
The above paragraph especially highlights that these multiple versions come at the cost of the promise of “never missing an update.” This again relates to the always writeable data store that Dynamo promises to be.
Another excerpt from the paper talks about versioning and the decision-making process behind deciding who should do conflict resolution, the datastore or the application. Dynamo isn’t just lazy that it doesn’t want to do conflict resolution but the engineers behind Dynamo thought it might be better to let the application do conflict resolution
The next design choice is who performs the process of conflict resolution. This can be done by the data store or the application. If conflict resolution is done by the data store, its choices are rather limited. In such cases, the data store can only use simple policies, such as “last write wins” [22], to resolve conflicting updates. On the other hand, since the application is aware of the data schema it can decide on the conflict resolution method that is best suited for its client’s experience.
While reading this section, I was intuitively thinking why not just have the “last write wins” method of determining the current state of a data item for all data items, and the paper provided a really good example of when that solution would not work.
For instance, the application that maintains customer shopping carts can choose to “merge” the conflicting versions and return a single unified shopping cart.
Interesting take on lack of durability for high availability
Generally, databases are forced to make a choice between availability and consistency. This is one of the biggest choices that databases make and impacts their use-case massively.
The paper talks about this in-depth since one of the big changes in the status quo Dynamo was trying to bring was to shift away from consistency when not required in favor of availability and performance.
People would assume availability and durability go hand in hand, as the paper also notes,
Traditional wisdom holds that durability and availability go hand-in-hand. However, this is not necessarily true here
It further talks about how in the case of Dynamo, it’s the opposite. Since all nodes don’t always acknowledge the write, it is possible that the data item is written to only a small number of nodes, maybe even one.
This means that there is a small window of time when the data hasn’t been replicated and durably stored in multiple locations. This can impact durability since a single node can, very rarely, lose data due to hardware failure.
This also introduces a vulnerability window for durability when a write request is successfully returned to the client even though it has been persisted at only a small number of nodes.
The paper didn’t talk much about durability, it would be interesting to read how they sync data to the OS, is it a forced sync on every transaction similar to relational databases, or is it a more periodic sync that is sometimes seen in today’s NoSQL databases. Also, couldn’t find anything related to write-ahead logs or something similar so it’s difficult to assess the durability of the individual node.
Conclusion and Resources
I felt the whitepaper was very interesting, and it was written in a way that the average software engineer could understand and make sense of it. I’d really recommend the full read, it’s much more detailed than I have been able to cover. Here’s the link if you are interested.
I’d really recommend the article by Werner Vogels written a decade after Dynamo here.
The AWS two-part series on data modeling for DynamoDB is also very interesting, though that focuses more on DynamoDB than Dynamo. It really shows how data querying and the data model are completely different than the relational model. Here’s the link if you are interested.
If you enjoyed this post, let me know in the comments if you have used Cassandra or DynamoDB and how was your experience with it.
Also, if you enjoyed this article, you’d probably like the recent article I did on Cassandra as well.


