How To Work With uint256 Blockchain Data Type Using SQL and Other Data Analysis Tools
Efficiently aggregate uint256 values using popular tech stacks
uint256 is a commonly used data type in a variety of blockchains. Including the most popular ones: Bitcoin (see arith_uint256.h) and EVM-compatible ones (Ethereum, Polygon, BSC, Solana — see go-ethereum GitHub).
Blockchains use this type to represent hashes of transactions, blocks, and other entities, addresses (which are also hashes, effectively), and numeric values like transfers amounts. In EVM (Ethereum), JSON RPC API uint256 values are represented as strings (e.g. blockHash, from):
{
"blockHash": "0xf8de4bddf97dfe1d84c16d1a506463bf910d543b2c0c73ad392d56d8583bafe2",
"blockNumber": "0x1076bb3",
"contractAddress": null,
"cumulativeGasUsed": "0xefd307",
"effectiveGasPrice": "0x9418b127e",
"from": "0x47d3f937151be62033a0fa9b1de1ef598bc05f70",
"gasUsed": "0xf6dd",
"logs": [
{
"address": "0xdac17f958d2ee523a2206206994597c13d831ec7",
"topics": [
"0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef",
"0x00000000000000000000000047d3f937151be62033a0fa9b1de1ef598bc05f70",
"0x000000000000000000000000bccb19bc3b6a1c0481733bad6f6d70622b0a9ecf"
],
"data": "0x00000000000000000000000000000000000000000000000000000000029f6300",
"blockNumber": "0x1076bb3",
"transactionHash": "0xd7949f64aad11944d10d585f12d0496a5dfa927e6afce97caafa974895efacbf",
"transactionIndex": "0x82",
"blockHash": "0xf8de4bddf97dfe1d84c16d1a506463bf910d543b2c0c73ad392d56d8583bafe2",
"logIndex": "0x127",
"removed": false
}
],
"logsBloom": "0x00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000010000000000000000000000000000000000000000000000000000000008000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000010000000000000010000000000000000000000000000000000000000000100000000100000000000000000000000000080000000000000000000000000000000000000000000000002000000008000000000000000000000001000000000000000000000000000000000010000000000000000000000000000002000000000000000000000",
"status": "0x1",
"to": "0xdac17f958d2ee523a2206206994597c13d831ec7",
"transactionHash": "0xd7949f64aad11944d10d585f12d0496a5dfa927e6afce97caafa974895efacbf",
"transactionIndex": "0x82",
"type": "0x2"
}An example above is a response of eth_getTransactionReceipt API method with a USDT transfer. Hashes (e.g., blockHash and transactionHash fields) and addresses (e.g. to and from fields) may be treated as strings for Data Analysis purposes: it makes no business sense to convert them to numbers.
A transferred USDT amount in the example above is contained in logs[0].data field as a uint256 number (in hex): 0x0…029f6300. To operate these values as numbers (to perform sum/avg/min/max/… and other calculations) you have to translate them into a native numeric type of your data analysis tool.
In this article, I explain options to operate the uint256 type using popular data analysis tech stacks. These approaches are based on my experience and have been successfully applied to multiple crypto projects I lead.
This post continues my previous one: “How to Export a Full History of Ethereum Blockchain to S3.” So, if you are interested in blockchain data ingestion approaches, check it out.
TL;DR: Approaches Overview
We have three major options to address the uint256 hex-to-number challenge:
- Use a tool that natively supports
uint256type: for example, Python (which has an unbounded built-ininttype) or ClickHouse (which has a range of signed and unsigned numeric types up to 256 bits). - Convert a hex value to a built-in type with a lower precision for approximate calculations: the majority of databases and SQL engines support 64-bit floating point numbers types (
doubleorfloat64) or even 128-bit numeric types (likedecimalin AWS Athena), which lose some precision as the numbers’ scale increases but have a reasonable relative error. - Implement long arithmetic based on arrays for exact calculations.
In the following sections of this article, you will find detailed explanations and implementation tips for each of the above approaches.
Approach #1: Use a Tool That Natively Supports uint256
This is the simplest option if you are not limited by the tech stack choices and are able to use any tool.
ClickHouse: UInt256 type
One of the best options here is ClickHouse database. I extensively use ClickHouse for most data projects I lead: it provides a convenient experience for both developers and analysts while demonstrating an impressively high performance for analytics-oriented workloads.
In particular, after uploading Ethereum data to S3 (this stage is described in my earlier article), the daily pipeline then imports the data into ClickHouse using a built-in s3 table function that provides a seamless integration.
After uploading the raw Ethereum data into ClickHouse, I then convert the hex strings into a native UInt256 type using reinterpret, reverse, and unhex functions:
┌─reinterpretAsUInt256(reverse(unhex('123ABC')))─┐
│ 1194684 │
└────────────────────────────────────────────────┘⚠️ But be careful! If you leave 0x prefix in your raw data, ClickHouse will interpret it as a part of the hex representation and produce a different output:
┌─reinterpretAsUInt256(reverse(unhex('0x123ABC')))─┐
│ 4279384764 │
└──────────────────────────────────────────────────┘🟢 Here is the first implementation tip: when performing an unhex conversion in ClickHouse, make sure the 0x prefix is removed before the conversion.
Regular leading zeroes are treated as expected (returns the same result):
┌─reinterpretAsUInt256(reverse(unhex('000123ABC')))─┐
│ 1194684 │
└───────────────────────────────────────────────────┘The above expression looks complex. The good news is that ClickHouse supports user-defined functions so that you may define a shorthand one yourself:
CREATE FUNCTION hexToUInt256
AS (hexValue) -> reinterpretAsUInt256(reverse(unhex(hexValue)));
SELECT hexToUInt256('123ABC');
┌─hexToUInt256('123ABC')─┐
│ 1194684 │
└────────────────────────┘🟢 Implementation tip: in ClickHouse, create a user-defined function for the uint256 unhex purpose.
You may also incorporate a logic to trim the 0x prefix from the input hexValue into this function to avoid misinterpretations.
Once you have converted the raw hex values into a native numeric type, you may leverage the full power of ClickHouse to do aggregations with the UInt256 values without losing in performance:
SELECT max(hexToUInt256(logData)) AS maxERC20TransferValue
FROM ods.evm_logs
WHERE
-- filters for ERC-20 Transfer event
(eventLogSigHash = 'ddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef')
AND (length(logTopics) = 3)
AND (length(logData) = 64)
┌────maxERC20TransferValue─┐
│ 335850000000000000000000 │
└──────────────────────────┘
1 row in set. Elapsed: 0.045 sec.Python: unbounded built-in int type
One of the amazing features of Python is built-in support for long arithmetic. This means that Python’s int type can handle unlimitedly big numbers (limited by your hardware resources, of course). Moreover, Python has a built-in hex-to-int conversion functionality:
>>> int('123ABC', 16)
1194684
>>> int('0x123ABC', 16)
1194684The second argument of int function is base: by default, it is equal 10. As you may have also noticed, in contrast to ClickHouse, Python handles the 0x hex prefix more intuitively.
Python is a good tool for performing ad hoc data analysis research with individual items. However, traditional data analysis scenarios usually require performing aggregation on top of the data. Sadly, popular Python-based tools like pandas do not support uint256 or Python’s built-in long arithmetic natively because they are based on a lower-level С code.
You may try some workarounds, but in general, you should prefer specialized Big Data tools to generic Python for regular workloads. See the other options listed in this article as alternatives.
Approach #2: Convert uint256 to a Native Floating Point Type
The above approaches are good when you have some freedom to choose a data analysis tool for your data platform. However, if you are limited, you probably have at least a database within your stack (because we are building a data solution, huh? 😉). Most databases are not 256-bits-numbers-friendly but natively support 64 bits numeric types: integers and floating point.
You will not be able to exactly represent a uint256 number using a smaller type because you will cut some binary digits. But you may rely on an approximate representation using the native types. While approximate calculations are unsuitable for some use cases (finances and accounting, for example), they are pretty usable in data analysis scenarios where you need to understand trends rather than have exact calculations.
And floating point numbers suit this need very well: they lose some precision as the number grows, but in fact, the relative error is very small (for double it is about 10⁻¹⁶).
Why floating point numbers and not “exact” integers?
We prefer floating point numbers to integers in this approach because this scaling feature, described above, is built into the floating point numbers design. And in blockchain data analysis, you will operate huge numbers because of long fractions. For example, BNB token has 18 decimals which means that 18 (!) trailing digits of the number represent an amount less than 1 BNB token — they are probably insignificant for you when aggregating loads of transfers in a single query.
🟢 Implementation tip: convert uint256 to floating point type to leverage the scaling feature for a fair small fraction rounding.
How to convert uint256 to double: Athena
As an example of an SQL engine not supporting uint256 but supporting floating point numbers with up to 64 bits (and decimal with 128 bits) we consider AWS Athena.
I use Athena even more often than ClickHouse because it is a convenient AWS-managed service providing querying capabilities on top of raw AWS S3 data. And I use S3 as a landing zone for all the projects I lead.
Athena has a function called from_base which converts a string representation of a number in a given base into a bigint value. (Athena is based on Presto. Thus, the link leads to Presto’s documentation.)
However, this function can easily overflow, as you can see here:
SELECT from_base('8000000000000000', 16)
<<< An error has been thrown from the AWS Athena client.
<<< INVALID_FUNCTION_ARGUMENT: Not a valid base-16 number: 8000000000000000Of course, this is a valid hex number, but it is just too big for bigint: bigint is a 64-bit signed type, so the biggest hex number it may represent is 7fffffffffffffff (2⁶³–1):
SELECT from_base('7fffffffffffffff', 16)
<<< 9223372036854775807This is a pretty small number considering the blockchain scale. In fact, 2⁶⁴ only represents 25% of the 2²⁵⁶ number hex length (64 x 4 == 256).
A workaround here is to shrink the hex representation of a number to the first N significant hex digits. But how big should N be? How many digits are considered significant for our case?
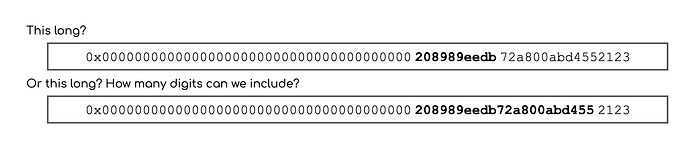
To understand this, let’s dive into our next step: as an output, we want a number of a double Athena type, which is a 64-bit floating point number. The numeric types are described in IEEE 754 standard, which states that the double precision floating point number has 53 significant bits.
The good news is that 53 bits is less than 64 bits, so bigint type should handle the “double-significant” part of a uint256 number.
Let’s calculate the number of significant hex digits, since we plan to extract a substring from a hex representation of a uint256 number. A single hex digit represents numbers from 0 to 15 => 2⁴ numbers => equal to 4 bits. 53 bits divided by 4 is 13.25. Being rounded up gives us 14 significant hex digits. A quick check: 14 hex digits = 14 ✕ 4 bits = 56 bits < 64 bits of bigint’s capacity.
The last thing is to remove the leading zeroes from a string representation of uint256: EVM hex values are usually zero-padded to 64 (for hashes) or 40 (for addresses) hex characters. So, even if the number is a small one, in EVM JSON API, it looks like this:
0x000000000000000000000000000000000000000000000aed2223130e11f7e1c0I believe you find the above explanation too simple, so let’s add regular expressions to make things more spicy: everything becomes better with an unreadable regex! 😈
SELECT
cast(
from_base(
regexp_extract(
input_value,
-- the regex skips 0x prefix and leading zeroes
-- and also extracts the first 14 significant digits
'^0x0*([\da-f]{1,14})',
-- extract the first group from the regex result (part in brackets)
1),
-- convert from base 16
16)
-- finally cast to double
as double)
-- shift double representation by non-significant hex digits as an exponent
* pow(
16,
-- skip the 14 significant digits, calculate a remaining length
length(
regexp_extract(
input_value,
'^0x0*[\da-f]{0,14}([\da-f]*)',
1)))
FROM (VALUES
('0x000000000000000000000000000000000000000000000aed2223130e11f7e1c0')
) AS t(input_value)
<<< 51598003004938240000000In the above query, you have noticed the pow part. This one is required to restore the scale of the input number: when you only leave the first 14 digits, you should consider the remaining ones and zeroes and multiply by an exponent of 16. See an explanation below:
- Input:
0x000000000000000000000000000000000000000000000aed2223130e11f7e1c0 - Trim 0x prefix and leading zeroes:
aed2223130e11f7e1c0 - Extract the first 14 digits:
aed2223130e11f | 7e1c0 - Round:
aed2223130e11f | 7e1c0≈aed2223130e11f | 00000 - Finally, shift:
aed2223130e11f7e1c0≈aed2223130e11f ✕ 16 ^ len('7e1c0')
This is the end of the implementation explanation, phew 😅. Thanks for going that far with me. For a real hardcode part, see the third approach with long arithmetic using SQL.
What we have now is the output value which not only represents the input uint256 number as a native numeric type, but also does not overflow when performing calculations; it just decreases the precision as the calculations results scale increases. In contrast to decimal which may overflow.
🟢 Implementation tip: prefer floating point numbers types to decimal because the latter may overflow.
Here is an example of how the precision is lost when calculations are performed:
SELECT
sum(
cast(from_base(regexp_extract(value, '^0x0*([\da-f]{1,14})', 1), 16) as double)
* pow(16, length(regexp_extract(value, '^0x0*[\da-f]{0,14}([\da-f]*)', 1)))
)
FROM (VALUES
('0x8000000000000000'),
('0x8000000000000000')
) as t(value)
<<< 18446744073709552000The above query sums up two big numbers (you remember that number that could not be handled by from_base function because of bigint limitations? It is it, supported now 😉) and returns 18446744073709552000, which actually differs from an exact result. We can calculate this precisely using Python:
>>> int('0x8000000000000000', 16) + int('0x8000000000000000', 16)
18446744073709551616A delta between the calculations’ results is 384, which is about 2 ✕ 10⁻¹⁷ from the exact value. You may follow this approach if this precision is not a critical blocker for your use case.
An approach to converting uint256 numbers to a floating point type is widely adopted: the two most popular public datasets with Ethereum data (AWS S3 and Google BigQuery described in my article) are using exactly it to represent the transfers values.
🟢 A recap on the Athena double-based approach
- Understand the number of significant digits supported by your database’s floating points numeric type. It is probably 53. Same as for Athena because of the IEEE standard.
- Trim
0xprefix and leading zeroes. - Extract the significant digits and convert them to a number using a built-in function.
- Convert the significant part to
double. - Multiply the significant part as
doubleby 16 in a power of the remaining hex digits length. - ̶W̶r̶i̶t̶e̶ ̶a̶n̶ ̶a̶r̶t̶i̶c̶l̶e̶ ̶o̶n̶ ̶M̶e̶d̶i̶u̶m̶ 😅
Approach #3: Implement Long Arithmetic
But what if you do not have time to integrate a new Big Data tool like ClickHouse into your stack but need exact calculations? When building a blockchain data platform for one of the projects, I was asked to implement a solution calculating exact balances for each wallet and token to show it to our crypto wallet app users.
At that time, I was also using Athena as a primary data transformation tool:
- The
double-based approach could not satisfy our needs since users want to see the exact numbers of their crypto assets. - At the same time, the balances calculation involves aggregating a full history of transfers, limiting the possibility of using simple tools like a Python script and forcing it to use a Big-Data-oriented solution.
- And as always, in startups, there was no time to onboard a new tool.
So, I was limited in various approaches and decided to choose the most optimal one: implementing an array-based long arithmetic in Athena.
What is long arithmetic?
Long arithmetic is a programming approach which allows you to support unlimitedly big numbers by representing them as arrays of smaller values of native numeric types. Each array element becomes a “digit” of an original big number represented with a big base.
Here is a simple example for you to get a better idea:
- Input number = 99186.
- Let’s say our “native” numeric type can support numbers from 0–99. The new base becomes = 100.
- The input number can be represented as an array of “digits” up to 100 each: 9, 91, and 86.
- When represented internally, the array will be reversed: [86, 91, 9]. This is because the arrays grow left-to-right: the bigger the number, the more array elements are appended (to the right end).
How to represent uint256 in Athena using a long arithmetic approach?
To represent a uint256 number, let’s use the biggest integer type available in Athena: bigint which is a 64-bit signed integer.
This “signed” nature of Athena type disallows us to naively split uint256 into 4 bigint numbers: a single 1/4 part of uint256 will be an unsigned uint64 number (256 / 4 == 64), and its range does not fit signed bigint’s. For example, 2⁶³ can be represented by unsigned uint64 (range: from 0 to 2⁶⁴–1) but not by signed int64 aka bigint (range: from –2⁶³ to 2⁶³–1).
Thus, we are going to split uint256 into 8 parts (256 / 8 == 32) each representing a uint32 number as a value of bigint type: uint32’s range is fully included into bigint’s. A visualization should help you understand the idea better:

uint256 hex into an array of 8 uint32 hexes: each part has a corresponding colourHere is the Athena query doing that (read from the innermost comments to the outermost to follow the transformation logic, steps are enumerated for your convenience):
SELECT
-- 6. apply a transformation to each matching substring
transform(
-- 5. returns an array of matching substrings (non-overlapping)
regexp_extract_all(
-- 1. reverse right-to-left number to left-to-right array
reverse(
-- 0. START HERE: THIS IS INPUT HEX VALUE
value_uint256_hex),
-- 2. split into groups of up to 8 hex characters
'.{1,8}'),
part -> from_base(
-- 3. reverse each individual part back to the original
reverse(part),
-- 4. convert to number from base=16
16)
)
FROM (VALUES
('abcdef1234567890')
) AS t(value_uint256_hex)
<<< {878082192,2882400018}The returned array consists of two uint32 “digits”: each number is less than or equal to 8 hex characters ≤ (2⁴)⁸ ≤ 2³² — fits uint32 type. The leftmost number is the least digit.
To convert it back to its decimal representation, we do a regular conversion operation between numbers systems: 878082192 + 2³² ✕ 2882400018 — we multiply by 2³² because it is our new number’s representation base. Let’s compare the results using Python:
>>> int('abcdef1234567890', 16)
12379813812177893520
>>> 878082192 + 2**32 * 2882400018
12379813812177893520The values are the same.
Implementing long arithmetic calculations in Athena
But the conversion is not our final goal: we want to perform the calculations now. Let’s implement a sum aggregation. In long arithmetic, we do it the same way we did a column addition at school — digit by digit with carrying:
WITH
input_uint256 AS (
SELECT value_uint256
FROM (VALUES
-- just random input numbers
-- they have 17 characters length
-- => when split into parts of 8 hex characters
-- they will produce arrays of 3 elements each
('1234567890abcdef1'),
('abcdef1234567890a')
) AS t(value_uint256)
),
uint32s AS (
SELECT
-- transforming to an array of uint32 as shown above
transform(
regexp_extract_all(reverse(value_uint256), '.{1,8}'),
part -> from_base(reverse(part), 16)
) AS value_uint32_arr
FROM input_uint256
),
sum_uint32s AS (
SELECT
ARRAY[
-- simply sum each digit individually
sum(value_uint32_arr[1]),
sum(value_uint32_arr[2]),
sum(value_uint32_arr[3])
-- for the demo purposes array has only 3 elements
] as sum_uint32_arr
FROM uint32s
),
carried1 AS (
SELECT
ARRAY[
-- carry from the smallest digit to the next one
-- 4294967296 is 2³² — our long arithmetic base
sum_uint32_arr[1] % 4294967296,
sum_uint32_arr[2] + sum_uint32_arr[1] / 4294967296,
sum_uint32_arr[3]
] as sum_uint32_arr
FROM sum_uint32s
),
carried2 AS (
SELECT
ARRAY[
sum_uint32_arr[1],
-- carry the second digit's overflow to the last one
sum_uint32_arr[2] % 4294967296,
sum_uint32_arr[3] + sum_uint32_arr[2] / 4294967296
] as sum_uint32_arr
FROM carried1
)
SELECT sum_uint32_arr
FROM carried2
>>> {1344563195,3760478380,11}Let’s convert the result into a number using Python and compare to a Python calculation:
>>> 1344563195 + 2 ** 32 * 3760478380 + 2 ** 64 * 11
219065316471564691451
>>> int('1234567890abcdef1', 16) + int('abcdef1234567890a', 16)
219065316471564691451The numbers are exactly equal.
The above example is limited to only relatively short hex numbers of 17 hex characters. When implementing the same solution for full-pledged uint256 numbers, you will have to do the sum step for an array of 8 elements and do seven iterations of carrying. We had only two here since the numbers were limited to three long arithmetic “digits.”
How to handle negative numbers in the long arithmetic approach?
A special case left unhandled yet is negative numbers. When calculating balances, you must distinguish incoming and outcoming transfers for each wallet and sum them with a corresponding sign (+ or –).
Let’s update our input data with a multiplier specifying its sign and use it to propagate the sign to the individual “digits”:
WITH
input_uint256 AS (
SELECT multiplier, value_uint256
FROM (VALUES
-- this is an outgoing transfer value
(-1, '1234567890abcdef1'),
-- and this is an ingoing transfer value
(1, 'abcdef1234567890a')
) AS t(multiplier, value_uint256)
),
uint32s AS (…), -- parse uint256 into array of uint32 as before
uint32s_signed AS (
SELECT
transform(
value_uint32_arr,
-- apply sign to each individual digit
part -> multiplier * part
) AS value_uint32_arr
FROM uint32s
),
…Now comes another challenge: Athena’s integer division with a remainder is not mathematically correct. In math, a remainder is always a non-negative value, while in Athena, this query produces a wrong output:
SELECT
-- in math: -1 == -1 * 1000 + 999 (a nonnegative remainder)
-1 / 1000, -- returns 0; should return -1
-1 % 1000 -- returns -1 (negative!); should return 999Compare to Python, which is mathematically correct:
>>> divmod(-1, 1000)
(-1, 999)This is important to notice when carrying the negative remainders: you should convert them to a mathematical notation first. We may achieve it with a simple trick:
SELECT
val as divisible,
1000 as divisor,
val / 1000 as quotient_athena,
val % 1000 as remainder_athena,
-- if the divisible is positive => Athena behaves correctly
-- also, if remainder is 0 => Athena behaves correctly
-- otherwise a patch is required
val / 1000 + if(val < 0 and val % 1000 != 0, -1, 0) as quotient_math,
val % 1000 + if(val < 0 and val % 1000 != 0, 1000, 0) as remainder_math
-- a set of representative numbers
FROM (VALUES (1001), (1000), (1), (0), (-1), (-1000), (-1001)) AS t(val)
+---------+-------+---------------+----------------+-------------+--------------+
|divisible|divisor|quotient_athena|remainder_athena|quotient_math|remainder_math|
+---------+-------+---------------+----------------+-------------+--------------+
|1001 |1000 |1 |1 |1 |1 |
|1000 |1000 |1 |0 |1 |0 |
|1 |1000 |0 |1 |0 |1 |
|0 |1000 |0 |0 |0 |0 |
|-1 |1000 |0 |-1 |-1 |999 |
|-1000 |1000 |-1 |0 |-1 |0 |
|-1001 |1000 |-1 |-1 |-2 |999 |
+---------+-------+---------------+----------------+-------------+--------------+As you may see in quotient_math and remainder_math columns, this patch makes integer division in Athena behave mathematically correct: divisible == divisor * quotient_math + remainder_math AND 0 ≤ remainder_math < divisor.
🟢 Implementation tip: be careful with Athena division, since it is not mathematically correct for negative divisibles! Use the above-described patch to fix it.
The last thing we need to do is apply this to each carrying part of the above Athena query:
WITH
…,
carried1 AS (
SELECT
ARRAY[
sum_uint32_arr[1] % 4294967296
-- applying the division patch to a remainder
+ if(
sum_uint32_arr[1] < 0
and sum_uint32_arr[1] % 1000 != 0, 1000, 0),
sum_uint32_arr[2]
+ sum_uint32_arr[1] / 4294967296
-- applying the division patch to a quotient
+ if(
sum_uint32_arr[1] < 0
and sum_uint32_arr[1] % 1000 != 0, -1, 0),
sum_uint32_arr[3]
] as sum_uint32_arr
FROM sum_uint32s
),
…And this fully completes the implementation of long arithmetic in Athena!
The real magic of the negative-powered approach is that you get immediate support for negative numbers too (uint256 starts behaving as a signed int256!); it comes in the form of two’s complement. Yup, this is an unexpected time to remember your CS course, ha-ha 🤓.
I am not going into too much detail about it here; it’s better to try the approach yourself and investigate how it behaves when a balance goes below zero.
🟢 A recap on Athena array-based long arithmetic approach
- Split the input
uint256hex value into an array ofuint32hex representations: up to 8 hex characters each. Don’t forget toreversethe input value. - Convert
uint32hexes tobigintnumbers. Don’t forget toreverseeach part back. - Implement digit-by-digit aggregations (
sumhas the most straightforward logic). - Perform digit-by-digit carrying starting from the smallest one. Don’t forget about negatives division Athena behaviour: apply a patch.
- Convert the output value to the output format you need.
Regarding the last step, here is a handy code snippet to convert an array of uint32s back to a hex representation:
SELECT
array_join(transform(
reverse(ARRAY[1344563195, 3760478380, 11]),
x -> lpad(to_base(x, 16), 8, '0')
), '')
>>> 0000000be02458ac502467fbCompared to Python’s output:
>>> hex(1344563195 + 2 ** 32 * 3760478380 + 2 ** 64 * 11)
'0xbe02458ac502467fb'Exactly the same up to the leading zeroes.
How to avoid code duplication for each digit?
To avoid duplicating this logic in a pipeline for each digit, I am using Airflow templating:
WITH
…
sum_uint32s AS (
SELECT
ARRAY[
{% for i in range(1, 9) -%}
sum(value_uint32_arr[{{ i }}])
{%- if not loop.last %},{% endif %}
{% endfor -%}
] as sum_uint32_arr
FROM uint32s
),
…
{%- for j in range(1, 9) %}
carried{{ j }} AS (
SELECT
ARRAY[
{% for i in range(1, 9) -%}
{%- if i == j -%}
sum_uint32_arr[{{ i }}] % {{ pow2_32 }} + if(
sum_uint32_arr[{{ i }}] < 0
AND sum_uint32_arr[{{ i }}] % {{ pow2_32 }} != 0,
{{ pow2_32 }},
0
)
{%- elif i == j + 1 -%}
sum_uint32_arr[{{ i }}]
+ sum_uint32_arr[{{ i - 1 }}] / {{ pow2_32 }}
+ if(
sum_uint32_arr[{{ i - 1 }}] < 0
AND sum_uint32_arr[{{ i - 1 }}] % {{ pow2_32 }} != 0,
-1,
0
)
{%- else -%}
sum_uint32_arr[{{ i }}]
{%- endif %}
{%- if not loop.last %},{% endif %}
{% endfor -%}
] as sum_uint32_arr
{% if not loop.last %},{% endif %}
{%- endfor %}
SELECT sum_uint32_arr
FROM carried8🟢 Implementation tip: when using Airflow for long arithmetic, rely on its templating functionality to avoid code duplication.
Alternatives
Speaking about big numbers support in Athena specifically, you may also consider using a user-defined function. This functionality allows executing an arbitrary transformation using a Lambda function. But the execution environment options for this functionality are limited to Java only. The good news is that Java has a built-in BigInteger class with an efficient implementation of long arithmetic.
Conclusion: How To Choose the Right Approach?
The main idea behind all the approaches is converting the hex representation into a native numeric type. You choose the native representation approach based on the capabilities of your executional environment:
- If your environment supports the big numbers natively (like ClickHouse, Python, or Java), do a straightforward conversion.
Otherwise, choose an approach based on your precision requirements:
- For approximate calculations, use a simpler floating-point numbers-based approach. These calculations will also be fast and user-friendly (simply
sum(value)and you are done). - If you need exact calculations (e.g., for a strict financial use case) and you do not have the option to migrate to an environment supporting them out of the box, go with the most complex-yet-working approach: array-based long arithmetic.
In general, you should always follow the golden rule of Data Engineering: use the right tool for the right job. If you may transition your workloads to a database with a native uint256 support, this will simplify things a lot for you.
But if you are looking for quick prototyping options using the tech stack you have in place, consider the advanced approaches which are applicable to the majority of databases and SQL engines.
Further Reading
If you want to read more about the Blockchain Data Platforms design, have a look at my previous article: “How to Export a Full History of Ethereum Blockchain to S3,” in which I describe a scalable and fault-tolerant way to ingest blockchain data.
Working on something similar? I am happy to have a further discussion with you. Let’s get in touch via LinkedIn or Telegram!

