How to Export a Full History of Ethereum Blockchain to S3
Using a public Ethereum node or public BigQuery datasets
If you are here just for a straightforward guide, here are the main takeaways:
- Ideally, run your own node. Implementations of Ethereum nodes have good synchronization facilities, so let the node first sync with a blockchain and then use JSON RPC API through an IPC interface to unload data from the node directly.
- As an alternative, use one of the public node providers. The majority of them do not require any authentication, so the request will be as simple as
curl -XPOST https://cloudflare-eth.com/ -d '{"method":"eth_blockNumber", "params": [], "id": 1, "jsonrpc": "2.0"}' - Follow the KISS (“keep it simple, stupid”) principle: simply loop through the blocks from 0 to
eth.block_number(current latest block). Firstly, fetch blocks withhydratedparameter set totrue. This will include transactions data into blocks responses. If you need logs (e.g. to extract ERC-20Transferevents), also fetch receipts (one per transaction). Receipts include logs.
A basic pipeline is fairly simple:
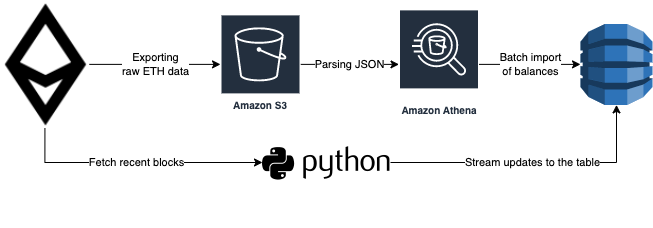
- Use batch requests: send an array of requests as a payload to the JSON RPC API. Example:
[{"method":"eth_getBlockByNumber","params":["0x1",true],…},{"method":…},…]. In a batch response, you will get an array of individual responses. Important: the response order is not guaranteed by a specification. - Parallelize batch requests: run async or multithreaded.
- As the best Data Engineering practice: dump raw data without transformations (in a raw format like JSON). You may store it in S3, for example (blocks + transactions + receipts + logs is around 4.5TB total now). This will allow you to rerun any calculations based on the whole history without touching JSON RPC API again.
- Using a combination of these approaches has costed us nothing extra (except hours from an EC2 instance) and taken 10 days to export the full history. Hosting an uncompressed JSON dataset in S3 costs us ≈$110 per month.
- For a quick initial population of your data lake, you may use public BigQuery datasets with Ethereum data. This approach has costed us ≈$100 and has taken around 24 hours to export blocks, transactions, and token transfer datasets.
The rest of the article covers the above in detail.
🎞 Prefer watching videos? Watch my talk on YouTube for a quick summary of this article. Or see my transcription for the video with slides. Or even a super-brief summary (2 minutes read) available here.
What’s inside?
Here is a brief plan for the article:
- The goal and requirements: why we decided to export this data?
- Exporting data from BigQuery public
bigquery-public-data.crypto_ethereumdatasets: is it a good idea? how to do it efficiently? how much does it cost? - Naive approach — fetch Ethereum data from a node: how long does it take for a full sync? how much does it cost to host the resulting dataset?
- Serving tokens balances with low latency: how to achieve it? how to handle uint256 in Athena?
- Ongoing Ethereum updates: fetching recent blocks in real time.
- The current state of our approach’s architecture with a diagram visualization.
Why do we need the full history of the Ethereum blockchain?
In CoinStats.app we build an advanced crypto portfolio manager. Apart from standard features like balance tracking and transaction listing, we help our users to search for new tokens to invest.
However, tokens balances tracking is still our core functionality. Originally we’ve been relying on various third-party services. But they have several cons:
- tend to be inaccurate/incomplete,
- lag a lot from the latest block,
- and/or do not allow retrieving the balances of all tokens for a wallet in a single request.
Altogether, this has led us to the following set of requirements:
- the solution must have a minimum possible lag from the blockchain
- provide 100% accurate balances
- and return a full wallet portfolio in a single response
- additionally, to further extend our product with analytics-based features, the solution must provide SQL interface on top of the blockchain data
- and we must not run our own Ethereum node.
Yeah, I know, the last requirement is controversial. However, the team I have joined already had an unpleasant experience maintaining a node. They insisted on using node providers. So, let’s treat this as a non-negotiable requirement for now.
In general, our goal was to (1) export the full history of blockchain transactions and receipts to low-cost storage (AWS S3), (2) attach an SQL engine (AWS Athena) to it, and (3) use it in real-time applications like balance tracking.
Existing solutions
We wanted to speed up the release of an MVP version of our new Data Platform, so we have decided to look for existing solutions. The shiniest one right now is Ethereum ETL. It is an open-source (hosted on GitHub) toolset for exporting blockchain data (mainly Ethereum).
In fact, ethereum-etl repository is a core part of a much bigger Blockchain ETL — a number of solutions for exporting blockchain data into various data destinations from Postgres to BigQuery and PubSub+Dataflow. There is even a special repository adapting all the scripts to Airflow DAGs.
An amazing fact is that Google hosts public BigQuery datasets with a full Ethereum history, which is collected using the Ethereum ETL project. See them yourself on the BigQuery console. Important note: even though the datasets are publicly available, you (as a Google Cloud user) pay for querying them. So, don’t do SELECT * if you do not want to go bankrupt 😅
However, Ethereum ETL has some cons:
- It is heavily Google Cloud-oriented. Repositories have some support for AWS, but they look poorly maintained. My contribution with Kinesis support is stale for several months now. Whereas I prefer AWS for data-related projects.
- The solution was well covered with articles (one, two, three, …) at the time of creation, but now looks very outdated. Airflow version is very old, and data schemas (especially for AWS Athena) are not in sync with an actual exporting format.
- Ethereum ETL does not preserve a raw format of the data. It does too many conversions at the time of ingestion. Thus, it is a ETL (extract-transform-load) solution, while a modern approach is ELT (extract-load-transform). And CoinStats.app is used to best practices
How we have started: unloading BigQuery to S3
Anyway, Ethereum ETL has laid a good foundation for our own initiative. Fetching raw data naively by requesting public node’s JSON RPC API would take more than a week to complete. So, we have decided to use BigQuery to initially populate our S3 bucket.
In brief, we are going to make the following steps: export BigQuery table to Google Cloud Storage (in gzipped Parquet format), copy it to S3 using gsutil rsync, and then make this data queryable in Athena.
Below you will find detailed instructions on how to do this.
1. Discover public Ethereum dataset on BigQuery
Open BigQuery console on Google Cloud Platform. In the datasets search field (on the left) type crypto_ethereum or bigquery-public-data and then click “Broaden search to all”.
❕ You must have a paid GCP account (with billing details configured) to discover public datasets: otherwise search results will be empty. You do not pay anything yet, but without a configured billing you will find nothing.
For further navigation convenience, I recommend you pin bigquery-public-data project once found.
2. Export a table to Google Cloud Storage
Choose any table, e.g. blocks. To export a full table, click “Export” at the top right corner and choose “Export to GCS”.
Instead of exporting the full table, you may export the results of a particular query: every query produces a new temporary table (shown in the job details in “Personal history” at the bottom). Once executed, click on a temporary table name in the job details and export it as a usual table. This can be useful for filtering out some unnecessary data in huge tables (e.g. logs or traces). Do not forget to check “Allow large results” in the query settings. Otherwise, you will see only a sample of data (≈128MB).
Note: if you run a query on a public dataset, you pay for it as a GCP user (see BQ analysis pricing). Exporting a full table is free (see details below).
For exporting, choose any GCS location. Feel free to create a new bucket with default settings (Standard storage will be the cheapest for our use case). You may delete the bucket right after the data is copied to S3 (this is the next step).
The only important GCS configuration option is region: “choose the same region as your target S3 bucket has”. In that case, your transfer costs and speed will be the most optimal ones.
Export format = Parquet. Compression = GZIP. This combination provides the best compression ratio, so it will speed up the data transfer from GCS to S3.
⏱ Usually, this job finishes in ≈30 seconds (see the job progress in “Personal history” at the bottom).
Export jobs are free up to 50TB per day (see BQ pricing), while total crypto_ethereum size is <10TB.
You will pay only for cheap GCS storage ≈$0.02 per GB-month. The data is compressed (blocks is around 65 GB as of August 2022) and is going to be stored no more than for a couple of days, so this will cost you <$5.
3. Copy the data from GCS to S3
Once the BQ export job is finished, you may export the data to S3. This can be done using a convenient CLI utility gsutil. To setup it:
- Create an EC2 instance. Consider EC2 network throughput limits when choosing the instance size. Ideally, choose the same region as GCS and S3 buckets have.
- Follow installation instructions for
gsutil. - Run
gsutil initto configure GCS credentials. - Populate
~/.botoconfiguration file with AWS credentials: simply setaws_access_key_idandaws_secret_access_keyto proper values. For AWS, a user with S3 multipart-upload and list-bucket permissions is enough. Of course, you may use your personal AWS keys for simplicity, but I should not have told you that… Related docs: Boto config reference, managing IAM access keys. - Create an S3 bucket, if not yet. To speed up the transfer, you have to create the S3 bucket in the same region as the GCS bucket.
- To copy the files, use
gsutil rsync -m.-moption parallelizes the transfer job by running it in a multithreaded mode.
We have used a single m5a.xlarge EC2 instance to transfer the data. This is not the most optimal way: EC2 has bandwidth limits and a hardly predictable “burstable” network throughput. We have considered using AWS Data Sync service: however, it relies on EC2 VMs too (you have to deploy an agent yourself), so I do not expect a large benefit compared to gsutil rsync unless you choose a larger instance.
For us, this took around 24 hours to export blocks, transactions and logs datasets from Google Cloud Storage in the gzipped Parquet format.
At this stage you will pay for:
- GCS network egress (to the outside of GCS). We paid around $100 total for several compressed datasets.
- S3 storage: compressed datasets occupy <1TB of data ≈ $20 total per month.
- S3 PUT operations. Exported transactions dataset contains of 8k objects, so this results in ≈$0.05 total.
- GCS data retrieval operations ≈$0.01.
- Obviously, hours of an EC2 instance you are using to transfer the data.
- You will also pay for temporarily storing the data in GCS, but this will be very cheap compared to the costs above: <$1.
4. Make data SQL-queryable with Athena
Once the data reaches S3, you may attach an SQL engine on top of it using AWS Athena. You may find the schemas I have recently updated, here.
Initially, the exported data is not partitioned on S3, so you have to create a single non-partitioned table, pointing to the exported data. Then, I recommend you partition the datasets by month: Athena cannot write into >100 partitions at once, so daily partitioning will require extra effort. The monthly partitioning query will be as simple as:
INSERT INTO partitioned SELECT *, date_trunc('month', block_timestamp) FROM nonpartitionedIn Athena, you pay for an amount of data scanned. So, right now it will cost you nothing.
Now, you may run SQL queries on top of the exported data. For example, we have used it for calculating tokens balances per wallet…
…but the calculations based on BQ dataset appeared to be incomplete! 🤯 The reason was that the bigquery-public-data.crypto_ethereum.token_transfer table contains only ERC-20/ERC-721 Transfer events, however for a complete view of some other events (e.g. Deposit) are required too.
So, we have switched to an alternative exporting method — fetching the full raw history from a public Ethereum node.
Where we have come to fetching from an Ethereum node
This approach has a significant advantage over using the Ethereum ETL public datasets: the data is exported as-is from a node. We may store it in a raw format and unlimitedly reuse it further, even mimicking the Ethereum node responses “offline”.
⏱ However, fetching the data this way takes much longer. In a multithreaded mode (20 threads on 16 cores) with batch requests, this has taken around 10 days total to export the full history and store it to S3.
Some overhead comes from Airflow which has been managing this export in a per-day fashion. For blocks ranges calculation an Ethereum ETL function get_block_range_for_date has been used.
We have used public nodes with a fallback mechanism, requesting providers one after another in case of failures.
💰 Total size of the resulting raw dataset (blocks with transactions + receipts with logs as an uncompressed JSON with non-compact separators=(', ', ': ')) occupies ≈4.5 TB which costs us ≈$110 per month.
To reduce the costs, you may reformat the dataset into Parquet with GZIP compression: this is the most optimal one. This will both save the storage and Athena querying costs.
Quick tip: the majority of node providers allow up to 1000 requests in a batch mode, but in fact they timeout when >200 blocks (eth_getBlockByNumber) with hydrated transactions are requested. So, limit your batch size to 200 for blocks and 1000 for receipts (the latter is times out hardly ever).
Importing into DynamoDB
Being a web application, CoinStats.app requires a low-latency and cost-efficient storage to retrieve balances for individual wallets. Athena and S3 are not the right tools for this job, and that is why an OLTP database is required. We use DynamoDB which allows us to prototype quickly.
⚡️ Luckily, AWS has recently introduced an awesome feature: DynamoDB tables can now be imported from S3! This allows you to create a new table and initially populate it with data from S3.
💰 Using this, you pay only for the volume of uncompressed data inserted from S3. Our balance dataset is 28.5 GB, which costs <$5 to be exported. Documentation does not mention any additional S3-related costs.
⏱ The operation is executed significantly fast: the 30GB dataset is imported in 3 hours.
For comparison: a naive approach with batch PutItem calls and provisioned capacity of 3K WCUs has taken us 21 hours to complete. Higher write capacity has been underutilized because of EC2 instance throughput limits. Parallelisation was an option but required an unnecessary extra effort.
Another significant advantage of the table import functionality is that it does not consume DynamoDB table’s write capacity! So, you may create an on-demand table, initially populated with tons of data from S3.
Balances calculation: the uint256 challenge
You may wonder: how do we calculate tokens balances given that the token transfer value type is uint256, not supported natively by Athena?
Athena numeric types are limited by Decimal which may represent up to 128-bytes numbers. To overcome this limitation, I have implemented long arithmetics in Athena. Briefly, this approach is as simple as:
- Split the hex value of a transfer into parts:
regexp_extract_all(reverse(value), ‘.{1,8}’).uint256value is represented as 64 hex characters, so this extraction produces 8 parts, each representing auint32number. These numbers will be our long arithmetic “digits”. - Parse each part:
from_base(reverse(digit), 16). - Sum each digit independently:
SELECT ARRAY[SUM(digits[0]), SUM(digits[1]), …]. - Normalize the digits to remainders:
SELECT ARRAY[sums[0] % uint32, sums[1] % uint32 + sums[0] // uint32, …]. Repeat this for every digit.
I have explained this approach in detail in my other article: “How to work with uint256 blockchain data type using SQL and other Data Analysis tools” — alongside with other viable alternatives like converting to double and using ClickHouse. Check it out if you plan to adapt blockchain data to real use cases. And if you like nerdy engineering topics 🤓
Beware that running SUM(digits[*]) on the whole history may overflow Athena’s bigint type. To avoid this, I recommend you calculating balances cumulatively on a monthly basis.
⏱ Calculating balances this way from the very beginning (Jul 2015) till now (Aug 2022) takes 2 minutes.
💰We are using a compressed Parquet dataset for historical balances calculation, so the query execution (= reading the full history using Athena) costs us around $0.65.
If you are familiar with Java, you would rather prefer Athena UDF functionality for this manipulation since Java has a built-in BigInteger class. Other languages are not supported for Athena UDFs.
Convert to the import format
The final step before uploading the data into DynamoDB is a conversion to one of the supported import formats. We have decided to use Athena for this conversion too and tried all three formats, but all have drawbacks:
- CSV is the simplest option, but does not support numeric types: all the non-key attributes are imported as strings.
- DynamoDB JSON format requires explicit attributes types: e.g. a numeric field is represented as
{"field_name": {"N": "1234"}}. - Both Ion and DynamoDB are case-sensitive, while Athena lowercase all the field names.
Fun thing, but I have finished up with a ROW FORMAT DELIMITED (aka CSV) Athena table, but mimicking the DynamoDB JSON format using string concatenation:
'{"Item": {"wallet": "' || wallet || '", …}}' as csv_fieldAnd this works fine!
The streaming part: fetching blocks in real-time
The only limitation of the DynamoDB table import functionality (apart from standard quotas) is that it can only populate a newly created table. Existing tables cannot be overwritten this way.
However, this excellently fits our use case: we use Athena to calculate balances based on the full history, upload them to a new DynamoDB table, and then continue fetching recent blocks to update the DynamoDB balances table in place.
The latest part is quite simple: we poll Ethereum node for the latest block number and when new blocks appear, we fetch them using eth_getBlockByNumber. Same way as we did when fetching the historical data, but continuously and as the new blocks appear.
A better approach would be using eth_subscribe method, but polling is just a simpler one.
Conclusion
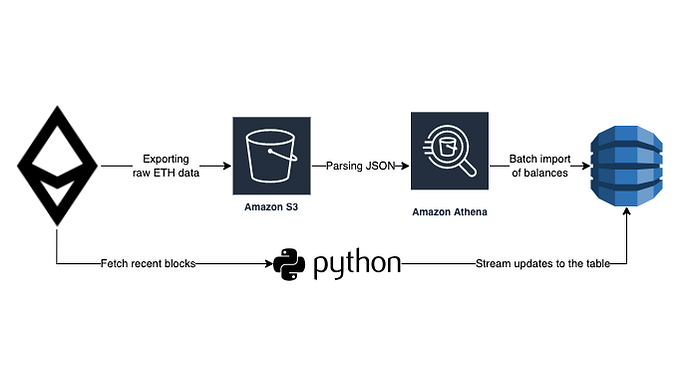
Right now we have:
- An Airflow-managed data pipeline that exports new Ethereum blocks (with transactions) and receipts (with logs) on a daily basis.
- The raw JSON data is parsed using Athena.
- The data is then reformatted into Parquet format for cheaper scans.
- This allows us to easily recalculate the token's balances and transaction history in about 2 minutes and for $0.65 only.
- At the end of the pipeline, we may also manually trigger a data import job into DynamoDB. For this, firstly, we use Athena to reformat the output data into DynamoDB JSON, and then we make an AWS API call to create a new DynamoDB table from the tokens balances dataset.
- Once a new table is deployed to DynamoDB, we “attach” a script to it which streams new blocks updates directly to the table.
This approach allows us to keep the full Ethereum blocks and logs dataset at ≈$100 per month, recalculate tokens balances from scratch for $0.65, deploy a DynamoDB table with new balances calculations in 3 hours and reduce the new blocks handling latency to <1 second.
Thank you for reading!
Want to discuss further or even hire me?Drop me a direct message through LinkedIn or Telegram, and I will be happy to reply!
To better grasp the knowledge and browse this article in other formats:
- A short summary of the main concepts (2 minutes read). Useful to refresh your memory later.
- My YouTube talk is based on this article: slides and speech with some extra details for better clarification.
- My transcription for the YouTube talk with slides.