Writing a High-Performance Golang Client Library — Batching on Pipeline
Batching on the writing path of the pipeline the right way
Rueidis is a high-performance Golang Redis client library I built recently on my own in order to use the server-assisted client side caching feature which has not been well supported yet by other existing golang libraries since time Redis 6 was released (in 2020).
Besides client-side caching, I learned a lot of common techniques, from building the library, that could also be useful in daily programming.
In this series of posts, I will share tips that I have learned and used in rueidis. These tips are recommended to not only library authors but also programmers dealing with networking or RPCs in their daily life. They are:
- Part 1 — Batching on pipeline
- Part 2 — Reading again from channels?
- Part 3 — Remove the bad busy loop with the
sync.Cond - Part 4 — Gracefully close channels from concurrent writers
Request and Response Model
Many client and server communications are designed on the Request and Response model.
From the client library point of view, it is very easy to program in this way:
- Write the request to the socket.
- Read the response from the socket.
Both write and read operations incur system calls and the socket is occupied until the read operation is finished.
To support concurrent operations and reduce handshake overhead, client libraries usually use the connection pooling technique. However, the costs of system call and round trip time are still huge.
Pipelining
TCP or QUIC provides the abstraction of reliable streams. And higher-level protocols that rely on the streams, such as HTTP 1.1, Redis Serialization Protocol 3, or PostgreSQL Protocol 3.0, usually support pipelining.
That is, a client library can just keep writing on the outgoing stream, and simultaneously, just keep reading on the incoming stream without waiting on each other.
Furthermore, in this way, multiple operations on each stream can be batched into one system call.
Therefore, if the client is programmed to use pipelining, then it doesn’t need to pay the costs of the two read/write system calls and an RTT for every operation, and thus it can have better performance.
The above Redis document is recommended to be read. It well explained how batching on the pipeline can be beneficial and improve 10x throughput.
Batching on Pipeline in Golang
In Golang, It is fairly easy to implement batching in this case just using channel and the bufio.Writer.
Here is a code snippet that is similar to what I have used in rueidis to automatically batch requests on the pipeline.
How does this code snippet work? The bufio.Writer already helps us reduce the socket write system call with its default 4k buffer. When the buffer is full, it will call the socket write system call automatically. However, in other words, until the buffer is full, the requests just remain unsent in the client buffer.
As a client library, we can not let requests remain in the buffer and wait for the user to send more requests to fill the buffer. What if there are no further requests to send? We need to send them out as soon as possible.
We use the non-blocking read operation select case with default of channels here to detect if there is no further request. If it does, then flush the bufio.Writer buffer immediately. After that, we use blocking operation only for the next read on the channel to avoid the loop from busy spinning.
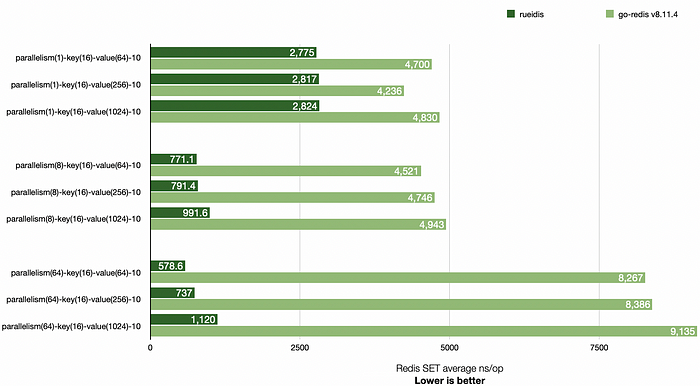
Result
As a result, with a similar batching technique, rueidis has better throughput than the go-redis in a local parallel benchmark across 1, 8, 64 parallelisms:
What’s Next
Batching on the writing path of the pipeline is fairly easy in Golang, but the reading path is much more difficult to handle.
As the following PostgreSQL documentation mentioned:
While pipeline mode provides a significant performance boost, writing clients using the pipeline mode is more complex because it involves managing a queue of pending queries and finding which result corresponds to which query in the queue.
This might be the reason why most libraries don’t do this by default.
In the next series of posts, I will share how does rueidis map pipelined responses back to the request and response model.

