Understanding Swift Strings, Emoji, Characters, and Scalars
Learn how Swift works with characters, using emoji as a fun and easy example

The relationship between characters and glyphs can be a bit confusing. By using emoji and observing the way Swift handles them, we’re going to dive into the topic. Lets’ say you want to check if a string contains one or more emoji — how would you do that?
A Little Background on Emoji
The word comes from two Japanese words: 絵 meaning picture (e) and 文字 meaning character (moji/mohdzi). The fact the word might make you think of emoticon or emotion is purely coincidental.
They’ve been around longer than you might think. Although they gained worldwide popularity around 2010, they were already being used in Japan since 1997. Starting out with a set of less than 80 symbols, the emoji set has grown to contain over 1,200 icons.
2010 was also the year the first set of emoji was added to the Unicode standard. Unicode is an industry standard designed to unify the handling and presentation of text. It also contains an index of characters from writing systems from all around the world to do so, both current and ancient. This standard keeps growing — the latest version as of writing (12.1) consists of nearly 138,000 characters.
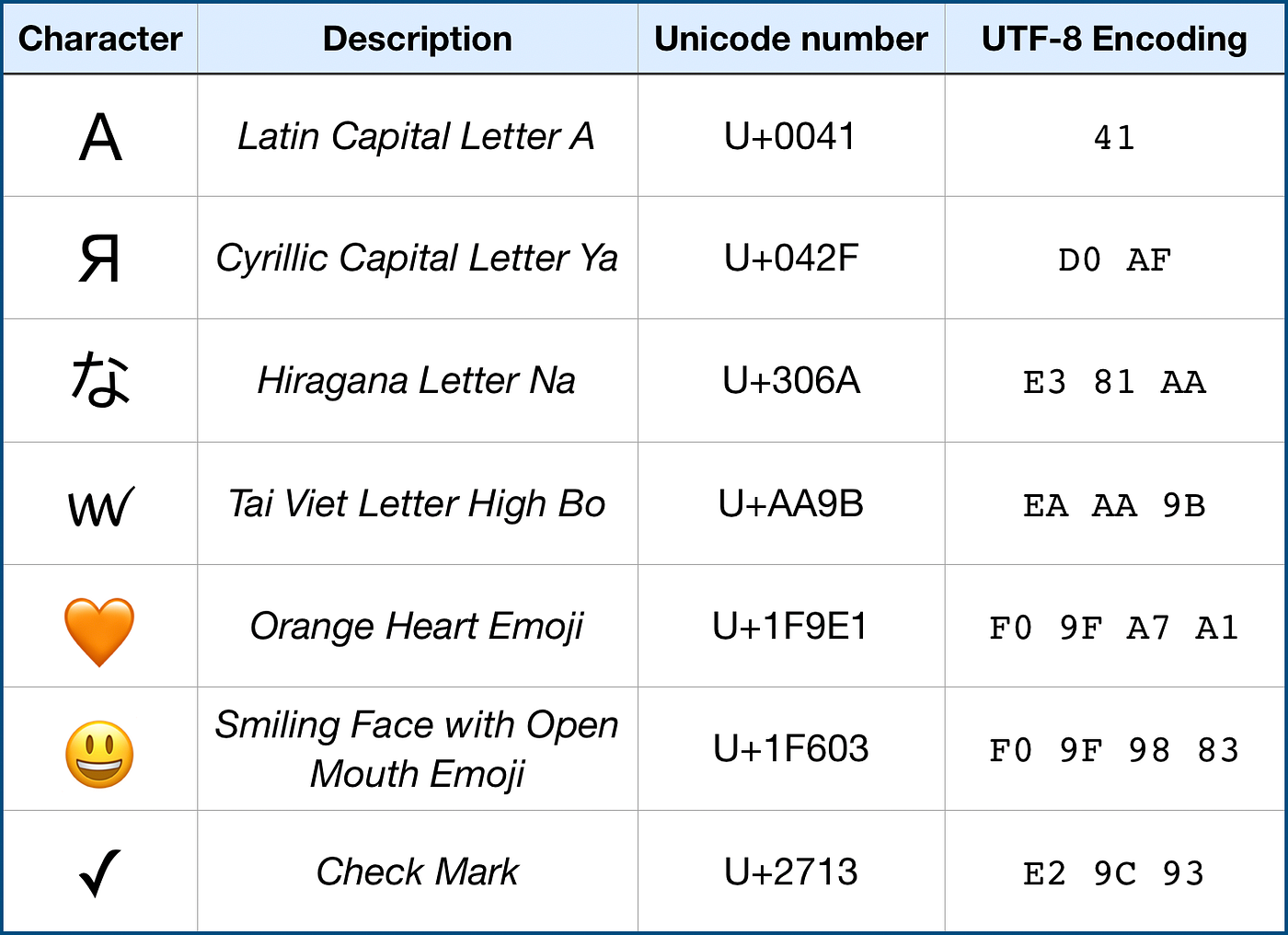
The standard includes not only characters from alphabets from around the world but also special characters that aren’t visible and can’t be used independently. We’ll get into that later.
I highly recommend checking out the Unicode® Character Table to get an idea of the scale of this. Simply scroll down the table on the main page to discover the combinations and possibilities.
Diving in
Every character defined by the Unicode standard has a hexadecimal identifier (unicode number) and characters are categorized into blocks, such as Hebrew or Arabic.
It’s important to to understand the difference between characters, glyphs, and scalars. Unicode consists of characters specified by a Unicode number. A character may or may not be represented on a screen. Also, a combination of characters may result in one character on screen. Swift distinguishes between there terms by defining them slightly different. It’s quite a complex story, but the gist of it is:
- A string consists of characters
- A character consists of unicode scalars
- Each Unicode scalar represents a Unicode character
Back to the Unicode characters. Here’s an example: the grinning face (😀) is identified as U+1F600 and is part of the emoticons block. You can represent the emoji in a Swift string in several ways:
let smiley1 = “😀”
let smiley2 = “\u{1F600}” // Hex code, also "😀"“So we can find the unicode block for emoji and check if a character is from that block?”
Well, no.
There’s not one block for Emoji characters. There’s separate blocks for transport and maps, supplemental symbols and pictographs, and a whole bunch of icons in miscellaneous symbols and pictographs. Even if we determine which blocks or what list of characters are emoji, chances are it won’t be future-proof. The standard is ever-evolving and expanding.
But if you dig deeper, you’ll see that last block also has strange characters, for example:

I’m not sure what it’s supposed to be (apart from the literal description given by Unicode), but my browser sure doesn’t know how to display it:

Applying this to code
Up to Swift 4.2, we were stuck trying to figure out if a character is an emoji by checking if the Unicode number belonged to one of the predefined Unicode blocks.
But along came Swift 5.0, and with it, a new Unicode.Scalar.Properties class, giving us a whole range of flags to help us figure out what we’re dealing with. We can fetch the array of Unicode scalars that represent our string very easily.
Enough boring talk — here’s an example:
// Here's our emoji
let smiley = "😀"// Get an iterable of the scalars in our String
let scalars = smiley.unicodeScalars // UnicodeScalarView instance// We have one character, so we'll be getting that one
let firstScalar = scalars.first // is 128512// Note that 128512 is actually the decimal
// value for hexadecimal 1F600 (the unicode identifier for 😀)// Get the properties
let properties = firstScalar?.properties
// Check if it's an Emoji
let isEmoji = properties?.isEmoji // = true
Eureka! So we’re done?
Well, no. How about this:
// Strangely enough, this will return true:
"3".unicodeScalars.first?.properties.isEmojiThis is because the scalar 3 can be presented as an emoji, even though in this particular case it isn’t. The property isEmoji is really misleading in this way. Luckily, there’s another property:
// This will return true like before:
"😀".unicodeScalars.first?.properties.isEmojiPresentation// And this will return false like we expect:
"3".unicodeScalars.first?.properties.isEmojiPresentation// By the way, that 'Notched Left Semicircle with Three Dots'
// also returns false, as we cannot actually render it:
"🕃".unicodeScalars.first?.properties.isEmojiPresentation// Unfortunately, this doesn't hold true for all emoji:
"🌶".unicodeScalars.first?.properties.isEmojiPresentation // false
"🌶".unicodeScalars.first?.properties.generalCategory == .some(.otherSymbol) // true
A lot better, right? But we’re not quite there yet. There’s also characters that actually consist of multiple glyphs. See how we used unicodeScalars.first?
Consider the following examples:
"1️⃣".unicodeScalars.first?.properties.isEmojiPresentation // false"♦️".unicodeScalars.first?.properties.isEmojiPresentation // false"👍🏻".unicodeScalars.first?.properties.isEmojiPresentation // true"👨👩👧👧".unicodeScalars.first?.properties.isEmojiPresentation // true
To explain why this is happening, let’s take a look at the unicodeScalars property. The property unicodeScalars returns an instance of UnicodeScalarView.
The debugDescription of it will just result in the original string, so inspecting the contents directly (or logging it) doesn’t offer much insight. Fortunately, there’s a map function that’ll return a regular array, so we end up with an array of the Unicode.Scalar elements:
// This will create an UnicodeScalarView
let scalarView = "1️⃣".unicodeScalars// Map the view so we get a regular array which we can inspect
let scalars = scalarView.map { $0 }
The resulting contains three values:
- Decimal 49 (hex U+0031): A plain old Digit 1
- Decimal 65039 (hex U+FE0F): Variation Selector-16
- Decimal 8419 (hex U+20E3): Combining Enclosing Keycap
There are those special scalars we were mentioning earlier. So the combination of these characters is used to form the emoji, turning a regular number 1 into this symbol. The second and third scalar modify the initial one. Just to clarify, you can also use the hexadecimal unicode identifiers to create this combination manually:
"\u{0031}" // turns into: 1"\u{0031}\u{20E3}" // turns into: 1⃣"\u{0031}\u{FE0F}\u{20E3}" // turns into: 1️⃣
Similarly, other emoji can be combined:
// Black Diamond Suit Emoji
"\u{2666}" // ♦// Adding 'Variation Selector-16':
"\u{2666}\u{FE0F}" // ♦️
// Thumbs up sign:
"\u{1F44D}" // 👍// Adding 'Emoji Modifier Fitzpatrick Type-4':
"\u{1F44D}\u{1F3FD}" // 👍🏽
// Man, Woman, Girl, Boy
"\u{1F468}\u{1F469}\u{1F467}\u{1F466}" // 👨👩👧👦// Adding 'Zero Width Joiner' between each
"\u{1F468}\u{200D}\u{1F469}\u{200D}\u{1F467}\u{200D}\u{1F466}" // 👨👩👧👦
Yep, that’s seven scalars combined into one character.
Finally, it’s good to note not every character that’s made up of multiple scalars is an emoji:
"\u{0061}" // Letter: a"\u{0302}" // Circumflex Accent: ̂"\u{0061}\u{0302}" // Combines into: â
Little side note: Maybe you’ve seen messages/text online that seem pretty messed up (almost like it’s a glitch in the matrix), looking something like this:

This is generally referred to as Zalgo, and actually just consists of many Unicode characters being merged into single characters on screen:
let lotsOfScalars = "E̵͉͈̥̝͛͊̂͗͊̈́̄͜"
let scalars = lotsOfScalars.unicodeScalars.map { $0 }
// Merge into a string, adding spaces to see them individually
// This will result in: E ̵ ͛ ͊ ̂ ͗ ͊ ̈́ ̄ ͜ ͉ ͈ ̥ ̝
let scalarList = scalars.reduce("", { "\($0) \($1)" })
Getting the Right Information
Let’s combine this information to add some helper properties to the character and string classes. We’ll:
- Check if a character is exactly one scalar that’ll be presented as an emoji
- Check if a character consists of multiple scalars that’ll be combined into an emoji
extension Character {
var isSimpleEmoji: Bool {
guard let firstScalar = unicodeScalars.first else {
return false
}
return firstScalar.properties.isEmoji && firstScalar.value > 0x238C
}var isCombinedIntoEmoji: Bool {
unicodeScalars.count > 1 && unicodeScalars.first?.properties.isEmoji ?? false
}var isEmoji: Bool { isSimpleEmoji || isCombinedIntoEmoji }
}
Next, we’ll add some computed properties to the string to access our character extension:
extension String {
var isSingleEmoji: Bool {
return count == 1 && containsEmoji
} var containsEmoji: Bool {
return contains { $0.isEmoji }
} var containsOnlyEmoji: Bool {
return !isEmpty && !contains { !$0.isEmoji }
} var emojiString: String {
return emojis.map { String($0) }.reduce("", +)
} var emojis: [Character] {
return filter { $0.isEmoji }
} var emojiScalars: [UnicodeScalar] {
return filter { $0.isEmoji }.flatMap { $0.unicodeScalars }
}
}
Now checking our string for emoji becomes very simple:
"â".isSingleEmoji // false
"3".isSingleEmoji // false
"3️⃣".isSingleEmoji // true
"3️⃣".emojiScalars // [51, 65039, 8419]
"👌🏿".isSingleEmoji // true
"🙎🏼♂️".isSingleEmoji // true
"👨👩👧👧".isSingleEmoji // true
"👨👩👧👧".containsOnlyEmoji // true
"🏴".isSingleEmoji // true
"🏴".containsOnlyEmoji // true
"Hello 👨👩👧👧".containsOnlyEmoji // false
"Hello 👨👩👧👧".containsEmoji // true
"👫 Héllo 👨👩👧👧".emojiString // "👫👨👩👧👧""👫 Héllœ 👨👩👧👧".emojiScalars // [128107, 128104, 8205, 128105, 8205, 128103, 8205, 128103]
"👫 Héllœ 👨👩👧👧".emojis // ["👫", "👨👩👧👧"]
"👫 Héllœ 👨👩👧👧".emojis.count // 2"👫👨👩👧👧👨👨👦".isSingleEmoji // false
"👫👨👩👧👧👨👨👦".containsOnlyEmoji // true
Summing It Up
There’s an important difference between characters and scalars: Basically, it’s up to the string that defines the scalars and the system rendering it to decide which characters the scalars will result in.
While Unicode defines each code point as a character, Swift really calls these scalars and uses the term character for the combination of scalars that may result in a single glyph in the string. I say may because things like control characters (e.g., null and backspace) will be counted as separate characters.
Thanks for reading!

