Turn Website Data Into Data Sets: A Beginner’s Guide to Python Web Scraping
Extract information from websites in no time in a highly automated manner
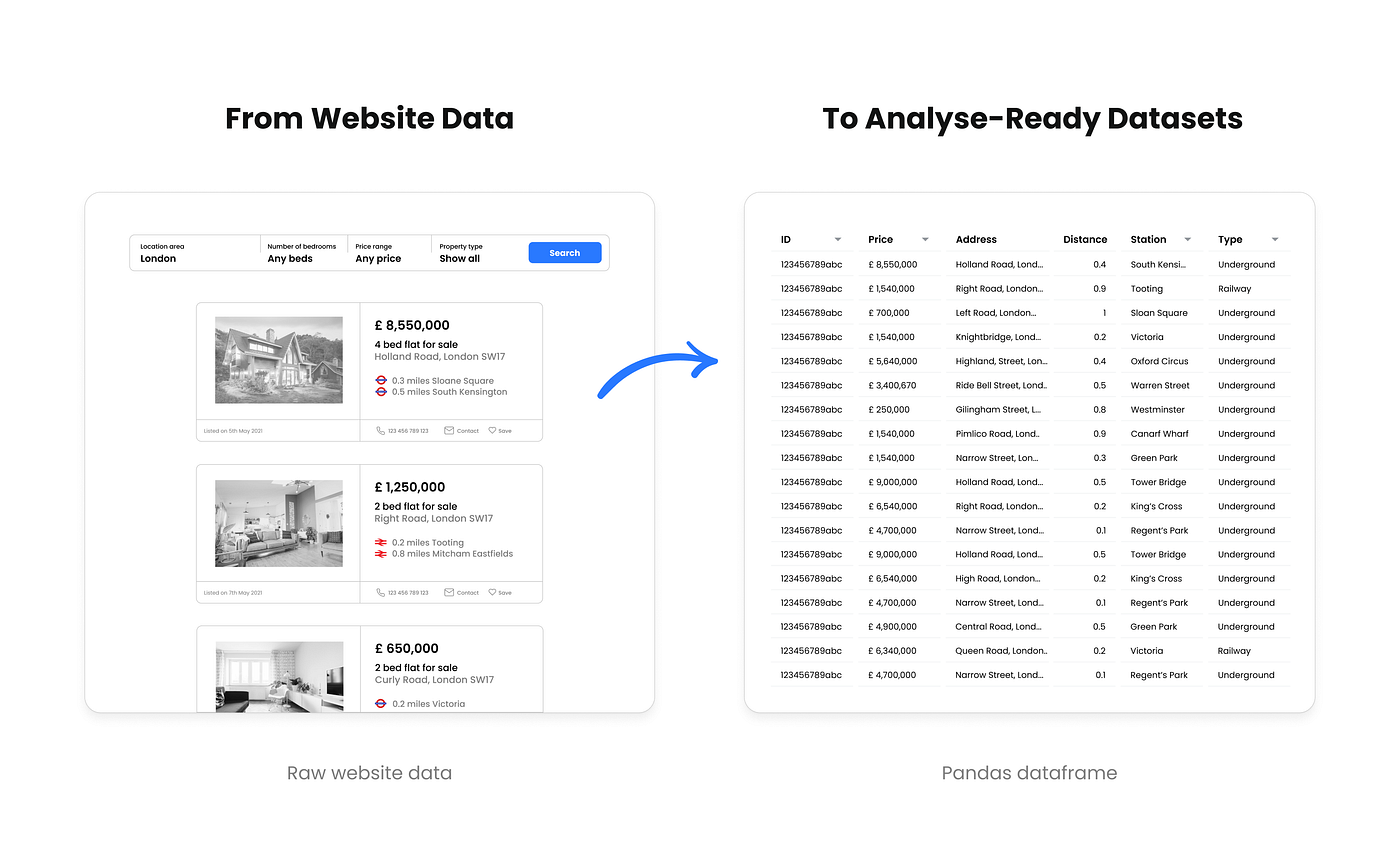
Overview
What the article covers
- Technical and legal considerations of web scraping
- Example for scraping a search-based platform using the HTML-based method with Python’s Beautiful Soup library
- Common techniques to tackle anomalies and inconsistencies in data when scraping
- An outlook of how the discussed example can be transformed into a data pipeline using Amazon’s cloud-computing platform, AWS, and Apache Airflow to regularly collect data
What is web scraping?
Web scrapers access the underlying code of a website and gather a large amount of data which is later saved on a local file or database. It has become an established discipline in data science and also in business: Companies collect competitor trends, pursue market studies, and perform in-depth analyses, all on data that can be accessed publicly.

How do web scrapers work in general?
There are different approaches to web scraping. This article focuses on HTML scrapers and covers a brief overview of other methods in the last section. As the name already reveals, these types of scrapers use the underlying HTML code of a website to retrieve the desired information. This method informally accesses the website, which is why using code with a customized logic is required in order to decipher the desired data.
Difference compared to API calls
An alternative method of fetching website data makes use of processes called API calls. An API (application programming interface) is officially provided by the website owner and allows requests of particular information in which the data is directly accessed from the database (or plain files). This usually requires permission from the website owner and is highly secured (e.g., API keys and tokens). However, APIs are not always available, which is why scraping is highly appealing, but it also raises the question of legality.
Legal considerations
Web scraping might violate copyright norms or terms of service of a website owner, especially when it is used for competitive advantage, a financial windfall, or abusive purposes in general (e.g., sending requests within very short time intervals). However, scraping data that is publicly available and is used for 1) private consumption, 2) academic purposes, or 3) other cases without commercial intention can generally be considered legally harmless.
If data 1) is protected behind a login or paywall, 2) is explicitly prohibited from being scraped by the website owner, 3) contains confidential information, or 4) compromises the privacy of the individual, any kind of scraping activity must be avoided¹. Therefore, bear in mind to always act responsibly and follow compliance first.
Beautiful Soup Setup in Python
Beautiful Soup is a Python library for collecting data from websites by accessing the underlying HTML code.
Install the latest version of Beautiful Soup in your terminal:
$ pip install beautifulsoup4Install requests to be able to call websites (the library sends HTTP requests):
$ pip install requestsWithin a Python or Jupyter notebook file, import these libraries:
from bs4 import BeautifulSoup
import requestsAnd some standard libraries for data processing and transformation steps:
import re
from re import sub
from decimal import Decimal
import io
from datetime import datetime
import pandas as pd0. Introduction
Imagine we want to scrape a platform that contains publicly available ads of properties. We want to obtain information such as the 1) price of the property, 2) its address, and the 3) distance, 4) station name, and 5) transport type to the nearest public transport stations to find out how property prices are distributed across public transport stations in a particular city.
For example, what is the average housing price for a public transport station XY if we consider the 50 closest properties to this station?

Important note: We explicitly avoid using a specific website as we do not want to promote a run for the same website. This why the code in this article is generalized and a fictive website with fictive HTML code is used. Nevertheless, the example code highly corresponds to real-life websites.
Assume that a search request for properties will lead to a results page that looks like this:
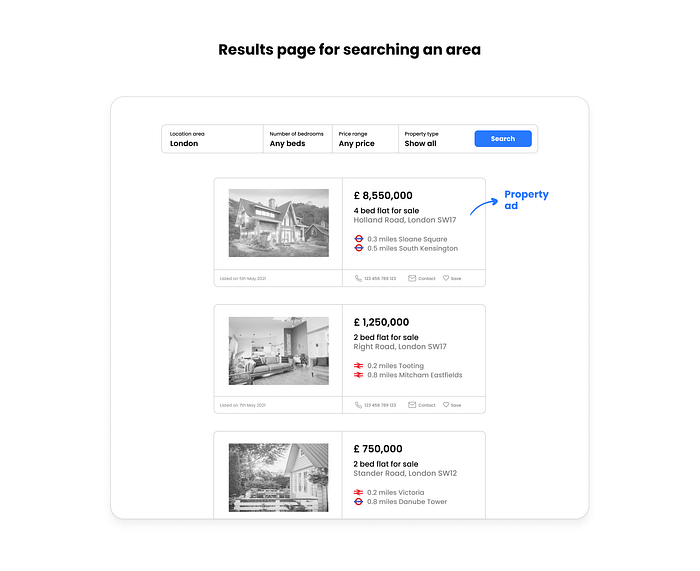
Once we know what layout and structure the ads are shown in, we need to come up with a scraping logic that allows us to fetch all desired features (e.g., price, address, public transport information features) from every ad available on the results page.
Whenever I am confronted with a scraping task of this nature, I approach it by the following steps:
- How to get one data point for one feature?
(E.g., get the price tag from the first ad.) - How to get all data points for one feature from the entire page?
(E.g., get price tags of all ads on the page.) - How to get all data points for one feature available across all results pages?
(E.g., get price tags of every ad shown for a particular search request.) - How to tackle inconsistency if the data point of interest is not always applicable in an ad?
(E.g., there are some ads in which the price field says “Price on application.” We would end up having a column consisting of numeric and string values, which does not allow a ready-to-go analysis in our case. Of course, we could simply exclude string values when doing the analysis. This step is just to demonstrate how to anticipate a cleaner data set from the beginning on, which might be even more valuable in other cases.) - How to better extract complex information?
(E.g., assume every ad contains public transportation information, such as “0.5 miles to subway station XY.” What does the logic need to look like so that we can store this mix of information directly in the right format: distance = [0.5], transport_type = [“underground”], station = [“name XY”])

1. Logic to get one data point
Important note: All code snippets discussed below can also be found in a complete Jupyter Notebook file in my repository on GitHub.
Call website
First, we replicate the search request we have done in the browser in the Python script:
# search area of interest
url = 'https://www.website.com/london/page_size=25&q=london&pn=1'
# make request with url provided and get html text
html_text = requests.get(url).text
# employ lxml as a parser to extract html code
soup = BeautifulSoup(html_text, 'lxml')The variable soup now contains the entire HTML source code of the results page.
Search feature-specific HTML tags
The trick is now to find distinguishable HTML tags, either classes or ids, that refer to a particular information point of interest (e.g., price, see illustration below).
For this step, we need the help of the browser. Some of the popular browsers offer a convenient way to get the HTML information of a particular element directly. In Google Chrome, you 1) mark the particular feature field and do a 2) right-click to get the option to inspect the element (or simply apply the keyboard shortcut Cmd + Shift + C). Source code is then opened next to the browser view and you directly see the HTML information.
In the example of the price, using the HTML class css-aaabbbccc will return the information £550,000 as shown in the browser view.

Understanding HTML class and id attributes
HTML classes and ids are used by CSS and sometimes JavaScript to perform certain tasks². These attributes are mostly used to refer to a class in a CSS style sheet so that data can be displayed in a consistent way (e.g., display price tag on this position in this format).
The only difference between class and id is that ids are unique in a page and can only apply to at most one element, while classes can apply to multiple elements³.
In the example above, the HTML class used for retrieving the price information from one ad also applies for retrieving prices from other ads (which is in line with the main purpose of a class). Note that an HTML class could also refer to price tags outside of the ads section (e.g., special deals that are not related to the search request but are shown on the results page anyway). However, for the purpose of this article, we are only focusing on the prices within the property ads.
This is why we target an ad first and search for the HTML class only within the ad-specific source code:

Using .text at the end of the method find() allows us to only return the plain text as shown in the browser. Without .text it would return the entire source code of the HTML line that class refers to:

Important note: We always need to provide the HTML element, which is p in this case. Also, pay attention to not forget the underscore at the end of the attribute name class_.
Get other features with the same logic
- Inspect feature of interest
- Identify corresponding HTML class or id
- Decode source code using
find(...).text
For example, getting the address, the HTML class might look like this:
(...)# find address in ad
address = ad.find('p', class_ = 'css-address-123456').text# show address
address

2. Logic to get all data points from one single page
To retrieve the price tags for all the ads, we apply the method find.all() instead of find() for catching the ad:
# get all ads within one page
ads = ad.find_all('p', class_ = 'css-ad-wrapper-123456')The variable ads now contains the HTML code for every applicable ad of the first results pages, as a list of lists. This storage format is very helpful as it allows to access ad-specific source code by index:
# identify how many ads we have fetched
len(ads)# show source code of second ad
print(ads[0])
For the final code, to get all price tags, we use a dictionary to collect the data and iterate over the ads by applying a for-loop:
Important note: Incorporating an id allows identifying ads in the dictionary:
# show first ad
map[1]
3. Get data points from all available results pages
A typical search-based platform has either pagination (click the button to hop to the next results page) or infinity scroll (scroll to the bottom to load new results) to navigate through all available results pages.
Case 1. Website has pagination
URLs that result from a search request usually contain information about the current page number.
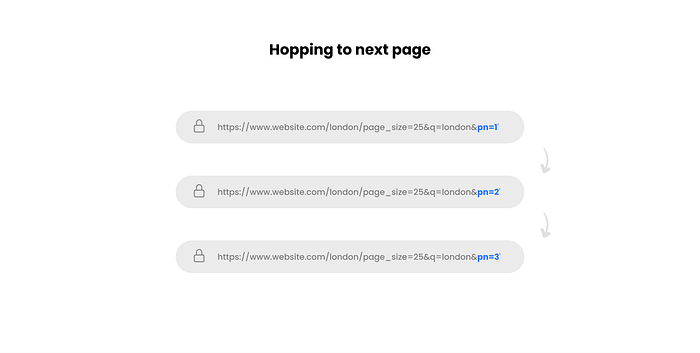
As can be seen in the illustration above, the ending of the URL refers to the results page number.
Important note: The page number in the URL usually becomes visible from the second page. Using a base URL with the additional snippet &pn=1 to call the first page will still work (in most cases).
Applying another for-loopon top of the other one allows us to iterate over the results pages:
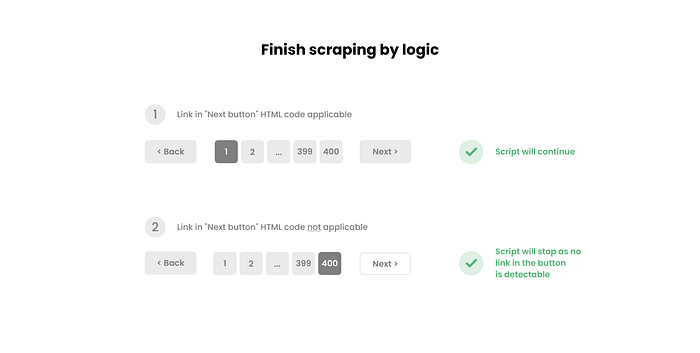
Identify the last results page
You may wonder how to identify the last results page. In most cases, after the final page is reached, any request with a larger number than the actual number of the last page will lead us back to the first page. Consequently, using a very large number to wait until the script has finished does not work. It will start to collect duplicate values after a while.
To tackle this problem, we can incorporate a logic that checks whether a link in the pagination button is applicable:
Case 2. Website has infinity scroll
If the website follows an infinity scroll approach, an HTML scraper might not be helpful as it requires reaching the bottom of the page browser-wise to load new results. This cannot be simulated by an HTML scraper and demands a more sophisticated approach (e.g., Selenium — see alternative scraping methods further down in the article).
4. Tackling information inconsistency
Data is never in the right shape, especially if it is collected. As mentioned at the beginning of the article, a possible scenario might be that we see price tags that do not represent numeric values.

If we want to avoid noise data from the beginning, we can apply the following workaround:
- Define function to detect anomalies
2. Apply function in the data collection for-loop
3. Optional: On-the-fly data cleaning
You may have already noticed that the price format £ XX,XXX,XXX still represents a string value due to the presence of the currency sign and comma delimiters. Act efficiently and do the cleaning while scraping:
Define function:
Incorporate function into data collection for-loop:
5. Extracting nested information
The features of the public transport section are mixed together. For the analysis, it would be best to store the values for distance, station name, and transport type separately.
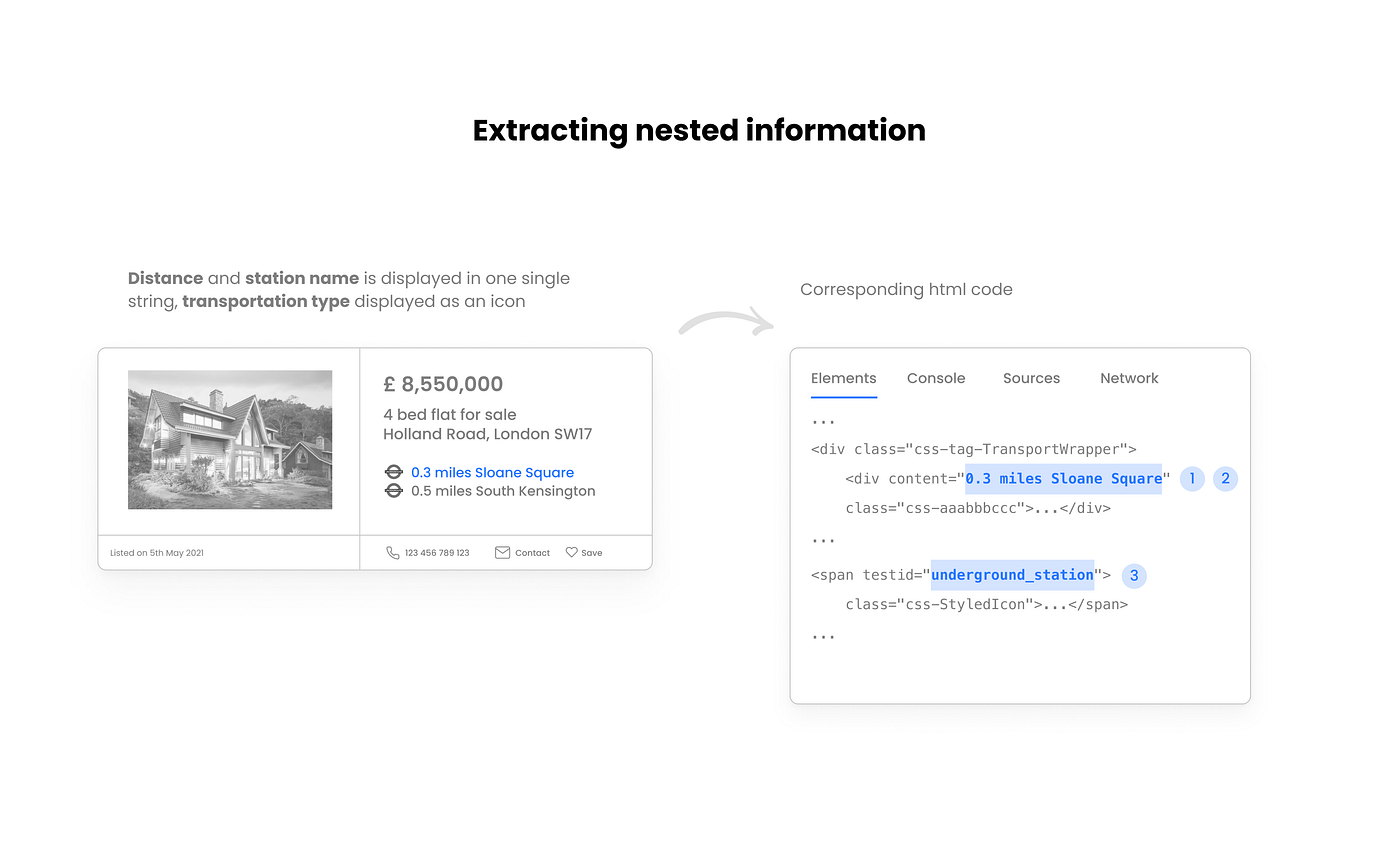
1. Distill information by rules
As illustrated above, every piece of information about public transport is represented in this format: “[numeric value] miles [station name].” See how “miles” acts as a delimiter here, and we can use it to split the string by this term.
Always try to identify a rule to distill information instead of deciding by best guess. We can define the logic as follows:
Initially, the variable transport stores two lists in a list as there are two public transport information strings (e.g., “0.3 miles Sloane Square,” “0.5 miles South Kensington”). We iterate over these lists using the len of transport as index values and split each string into two variables, distance and station.
2. Search for additional HTML attributes to decode visual information
If we dive deeply into the HTML code, we find an HTML attribute, testid, that reveals the name of the icon that is used to display the transport type (e.g., “underground_station” — see illustration above). This information serves as metadata and is not shown in the browser view. We use the corresponding HTML class css-StyledIcon to get the entire source code of this section and add testid to carve out the information:
This example shows how useful it can be to dig deeper into the source code and watch out for metadata that can reveal meaningful information for optimizing the web scraper.
6. Transform to data frame and export as CSV
When the scraping task is done, all fetched data is accessible in a dictionary of dictionaries.
Let’s consider only one ad first to better demonstrate the final transformation steps.
Output of the first ad in the dictionary:
# show data of first ad
map[0]
1. Transform dictionary into a list of lists to get rid of nested information
We transform the dictionary into a list of lists so that each category only holds one value.

See how we got rid of the multiple values in the public transport section and created an additional entry for the second public transport data point. Both entries are still identifiable by the id 1 we have inherited.
2. Create data frame using the list of lists as input
df = pd.DataFrame(result, columns = ["ad_id", "price", "address",
"distance", "station", "transport_type"])
The data frame can be exported as a CSV as follows:
# incorporate timestamp into filename and export as csv
filename = 'test.csv'
df.to_csv(filename)Transformation to transfer all ads into data frame
We made it! That was the final step. You have built your first scraper that is ready to be tested!
7. Limitations of HTML scraping and alternative methods
This example has shown how straightforward HTML scraping can be for standard cases. Extensive research of library documentation is not really necessary. It demands, rather, creative thinking as opposed to complex web development experience.
However, HTML scrapers also have downsides⁴:
- Can only access information within the HTML code that is loaded directly when the URL is called. Websites that require JavaScript and Ajax to load the content will not work.
- HTML classes or ids may change due to website updates (e.g., new feature, website redesign).
- Cannot transmit user content to the website, such as search terms or login information (except search requests that can be incorporated into the URL, as seen in the example).
- Can be detected easily if the requests appear anomalous to the website (e.g., a very high number of requests within a short time interval). This is prevented by defining rate limitations (e.g., only allow the performance of a limited number of actions in a certain time) or other indicators, such as screen size or browser type, in order to identify a real user.

Learn how to transform a simple web-scraping script into a cloud-based data pipeline
As a next step, we could have turned this script into a data pipeline that automatically triggers scraping tasks and transfers results to a database — everything in a cloud-based way.
A first step would be to create or identify an id that is purely unique for one ad. This would allow fetched ads to be re-collected and matched to run historical price analyses, for instance.
How this can be achieved and what technical steps are required to deploy a data pipeline in a cloud environment will be covered in the next article.

GitHub repository
References
[1]: Tony Paul. (2020). Is web scraping legal? A guide for 2021 https://www.linkedin.com/pulse/web-scraping-legal-guide-2021-tony-paul/?trk=read_related_article-card_title. Retrieved 10 May 2021.
[2]: W3schools.com. (2021). HTML class Attribute https://www.w3schools.com/html/html_classes.asp. Retrieved 10 May 2021.
[3]: GeeksforGeeks.org. (2021). Difference between an id and class in HTML? https://www.geeksforgeeks.org/difference-between-an-id-and-class-in-html/#:~:text=Difference%20between%20id%20and%20class,can%20apply%20to%20multiple%20elements. Retrieved 10 May 2021.
[4]: JonasCz. (2021). How to prevent web scraping https://www.w3schools.com/html/html_classes.asp. Retrieved 10 May 2021.
[5]: Edward Roberts. (2018). Is Web Scraping Illegal? Depends on What the Meaning of the Word Is https://www.w3schools.com/html/html_classes.asp. Retrieved 10 May 2021.

