Member-only story
Try, Catch, Retry
How to tackle failures in your RPA service so you can do less manual work
In March 2022, I deployed an RPA service on my Synology NAS. It downloads a CSV with information about the electricity production of the solar system I have installed at home daily. After the CSV is downloaded, a small Python service picks it up and aggregates the data, saving it into a Postgres database.
I have created dashboards in Grafana to monitor the electricity consumption and the application's state. The entire setup is detailed in the Applications section.

Out of 160 runs, 51 were done manually due to the timeouts encountered while downloading the CSV file. It happens quite often for the website to be unresponsive and for the RPA service to fail to navigate to the page with the download button. It also happens to upgrade the Synology operating system, which usually replaces my Postgres configurations, and the data load service fails due to missing access rights. In this article, I will go through how I tackle the failures in my service to decrease the number of manual interventions I need to make.
Error Handling
First, let’s check the high-level diagram of my application:
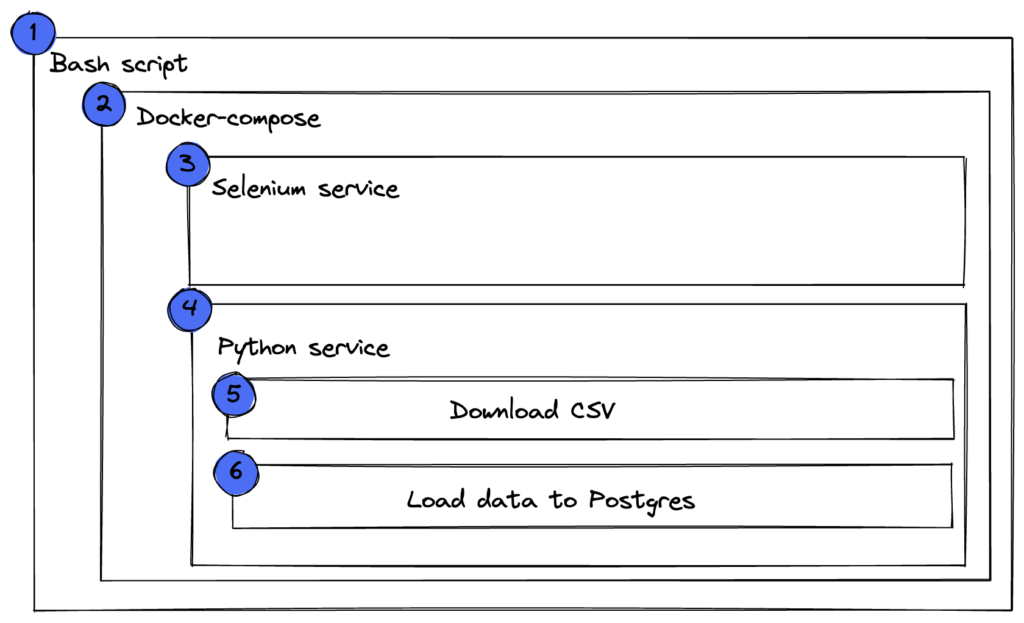
Each day at 7:00 a.m., the bash script: (1) executes a docker-compose command (2) which will start the Selenium service (3) and the Python service. (4) The Python service will first download the CSV (5) and afterward will load it into Postgres (6).
The final scope of the application is to load data from the previous day into Postgres. Hence, the main failure is when there is no data loaded.
Error Handling — Orchestration
One way to handle the failure of missing data would be to have error handling in the bash script (which is the orchestration choice). A successful execution means that a file with yesterday’s date in the file name…

