Four Aspects of Scalable I/O in Applications
Applications interact with their environments, but the more they scale, the more important it is to keep business logic neatly separated from the outside world
It is a fundamental rule of software that scale exposes weakness. Many architectures work fine for smaller applications but will collapse under their weight when as more features are added. An application designer lucky enough to be responsible for a large codebase must understand how their design may fail at scale and take the appropriate actions to refactor before it’s too late.
As I’ve argued, your application’s scalability depends on how well you decouple business logic from state, but in this article, I’d like to discuss another factor that is just as important: Inputs and Outputs (I/O). We need to decouple inside from outside.
I/O is dependent on context, so it is more difficult to generalize than business logic. I will focus on the domain I’m familiar with — video players — because I’m trying to fill a void of documentation around that type of application. These ideas, however, can be applied widely.
Video players scale by adding features (and more features) on top of one or more core playback engines. Each feature adds a new thread of overlapping business logic, each with its own inputs and outputs. This complexity requires different types of I/O interactions above and beyond what you’d find in most web applications.
The Four Aspects
There are two dimensions to I/O: direction and specificity.
The direction is fairly straightforward. You have data coming into the application from outside; this is input. You have transformed data leaving the application possibly kicking off side effects; this is output.
The other dimension, specificity, is a bit more subtle. I/O is diffuse if your application doesn’t care where the input comes from or where the output is going. I/O is specific if you need to know the precise interface you are interacting with.

1. Diffuse Input: API Function Calls
In any application, you must allow the outside context to kick off internal business logic.
Take a video player’s pause function. The player shouldn’t care who wants to pause the media; it could be called from a button click or some process in the context itself. Any code that needs to pause the media calls this function, and the player takes care of the rest.
The base requirement here is that an API is created by your application and then made available within your application’s context for outside code to access.
But be careful; here be dragons. I’ve seen too many ‘Application’ objects that contain API functions and instantiate a zoo full of various managers and controllers. These application god classes almost always become garbage dumps for all the code that doesn’t fit anywhere else.
This is the malign beating heart of the Controller Manager Muddle. It is every failed application’s original sin.
But what’s the scalable alternative? The problem here is not so much the API but the fact that its instantiation gets used as a god class.
Each piece of business logic should be decoupled from the others and the API itself. Instantiation of the business logic is a different concern from building your API.
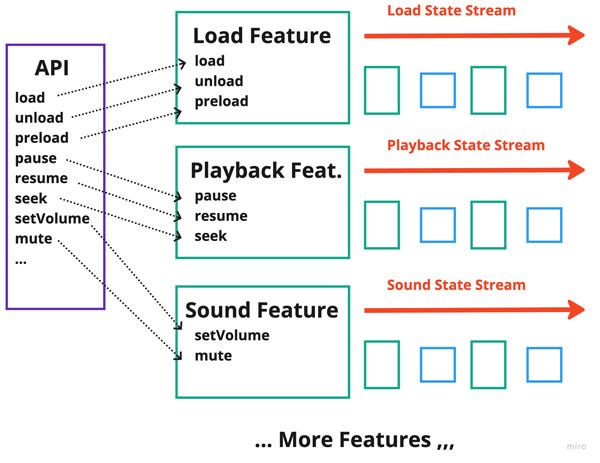
An API class should do nothing other than route the calls to the correct business logic. For those whose language includes annotations, you could even build the API at compile-time, removing all the temptation to dump random business logic in there. Unfortunately, the JavaScript ecosystem doesn’t condone annotations, so it’s all hand-rolled — just try to keep it simple.
2. Diffuse Output: Events
Often, at the moment when state is created or changed within your application, you want to notify interested external applications so they can use the data as input to their own business logic. An event is good for this. Events can be consumed in ten places or none. Your application doesn’t care.
As such, events are a basic way to decouple applications, and even beginner-level developers should be familiar with them, especially in UI development.
But make no mistake; events are often misused. They can destroy your application.
The trouble comes when you use events to transfer data across your application between two pieces of code that otherwise don’t know about each other. Surely that’s better than injecting all those random controllers and managers into each other, right?
Not the case. It’s actually worse. Much worse. Hard-coding function calls to other controllers gets insanely messy, but at least you can track down what your code is doing if you have enough fortitude. However, if your internal business logic depends on events, you’re asking for trouble.
I’ve seen this pattern (and its even more corrosive cousin, the shared mutable object), so often I throw up a little in the back of my mouth when I encounter it in a codebase.
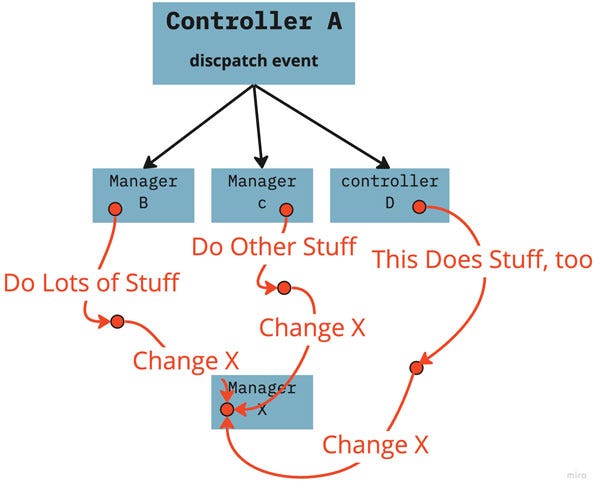
Here’s the issue: by definition, events are consumed by indeterminate code and are fired in indeterminant order. As complexity increases with scale, two or more lines of code execution kicked off by the same event are eventually going to unpredictably transform the same piece of state, causing nightmare bugs.
Your internal order of execution splits open like a piñata at a birthday party.
Once you use events inside your business logic, there is no good way to shove the candy back into the piñata. You’re forced to add a special-use state to disambiguate the little grey areas of overlapping executions that arise. One, then another, then another.
They say the road to hell is paved with good intentions.
3. Specific Inputs: Plugins
It’s often necessary and desirable to let external code participate in the business logic of your application. This can enhance the extensibility of your code by allowing functionality to be swapped out at runtime.
But this external code shouldn’t be reacting to an event and sending back its data via an API function call. This is another pattern I’ve seen (and built, unfortunately), and obviously, it runs into the same issues as the internal events I described above.
What you want to do instead is find a spot in your code where you can encapsulate the execution of that external business logic, then create an interface specifically tailored to handle the exchange.
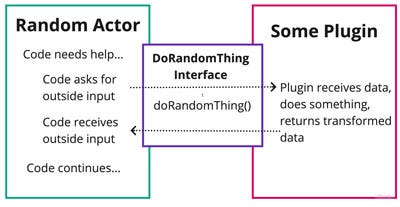
The advantage here is that your internal application retains complete control over the order of execution. The external code, often a plugin that loads at runtime, will receive the relevant data via a callback, do its work, then return the transformed data.
And a discrete interface is easy to document and understand. Don’t underestimate the importance of allowing other teams to interact with your code in a predefined, autonomous way. Plugins are an easy win for extensibility. A good plugin setup allows your application to be used in ways you never anticipated, which is a good thing!
4. Specific Outputs: App Interfaces
In large-scale applications, we often create an ecosystem of peer sub-applications, each with its own complicated business logic and multi-faceted API. These sub-applications should be built along fracture planes in your system, allowing multiple teams to work on your application independently.
For example, there are subtle (and not-so-subtle) differences in low-level video playback between different browsers and devices. Any video player worth its salt must abstract away these details from higher-level business logic by hiding them behind a common interface.
These interfaces, however, must be carefully constructed, or they become sources of coupling and pain.
The biggest problem is the leakage of shared states across the interface. Often, I’ve seen teams that haven’t gone far enough to sequester one codebase from another.
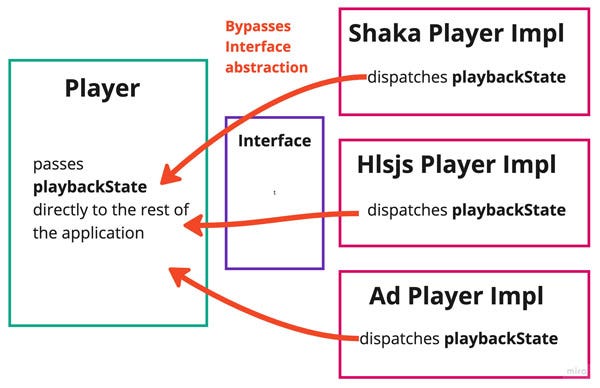
What if you need to modify how the playback state works? It now must be refactored across both sides of the interface, including every implementation — not an easy thing to keep track of. This type of coupling can make it very difficult to refactor your system, as changes on one side of the interface may produce unintended results on the other.
Better to keep these interfaces impermeable. Turn them into a formalized API. Never shuttle state directly from one side to the other. Put the code in different repositories. Keep the teams separate if you can. Never let implementation details from one side of the API change the other without an explicit change to the official documentation.
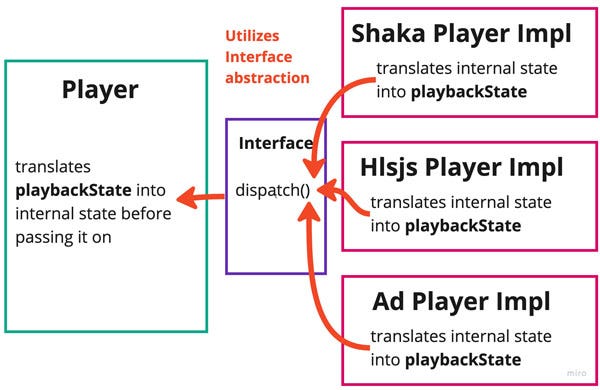
When you do this, you’ll often find that you need to sharpen the API into something general enough to work for every possible use case. This is a good thing. It forces you to consider where to draw the line between sub-applications seriously.
The Interface Segregation Principle
APIs for any normal application are meant to handle a wide variety of functionality. Take the API for the HTML video element. It is full of functions and properties for handling wildly different business logic concerns: media startup, playback, sound, captions, layout, etc.
Almost every video player I’ve ever dealt with treats this jumble of randomness as a monolithic entity, creating monster multi-thousand-line classes to handle all that interaction in one place, no matter how unrelated.
Um, can we not do that, please? There is a great way to deal with this issue. Namely, the ‘I’ in SOLID — the Integration Segregation Principle.
I’ve seen teams practically worship SOLID in name but fall far short of the ideal in practice. They LOVE the ‘D’ (Dependency Inversion), overuse the ‘L’ (Liskov Substitution), misunderstand the ‘O’ (Open-closed), openly break the ’S’ (Single Responsibility), and treat the ‘I’ as if it doesn’t exist.
But, in a large-scale frontend application that interacts with other application APIs, Interface Segregation is possibly the most important and useful of the SOLID principles. It is the principle that, when followed, allows all the others to be fulfilled correctly.
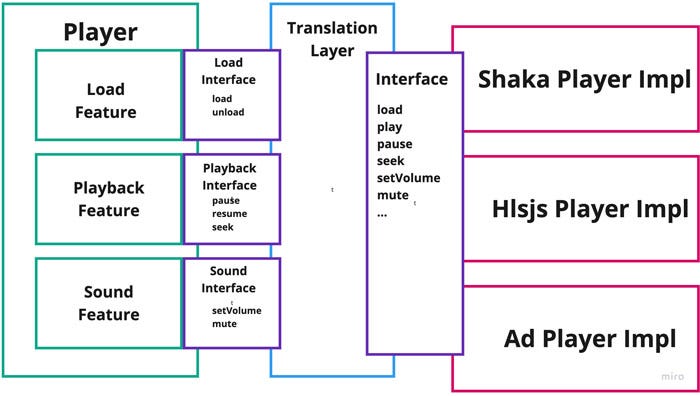
When an API is split into different interfaces, each interface can be focused solely on whichever slice of functionality a certain bit of business logic needs. This is fundamental to turning your application away from the Controller Manager Muddle and towards an extensible Business-Logic-centric model.
This is the last of my architecture essays for the time being. Thank you all for reading this far, and I hope you’ve found something useful.
There is much more to say on reactive programming, and I intend to return to the subject, but for the moment, I’m interested in addressing another pressing issue.
Namely, how do we create an effective process for building software?
Until then, happy coding!

