Singly and Doubly-Linked Lists in JavaScript
Lists aren’t just arrays

When programmers see the word “list”, we usually immediately think “array”.
Arrays are great for storing data to iterate over, but since they have numbered indexes, manipulating elements in the array can be costly in terms of time and space complexity.
For example, if we wanted to insert a new element at the 10th index in a 100-element array, we’d have to re-index the other 90 elements after insertion.
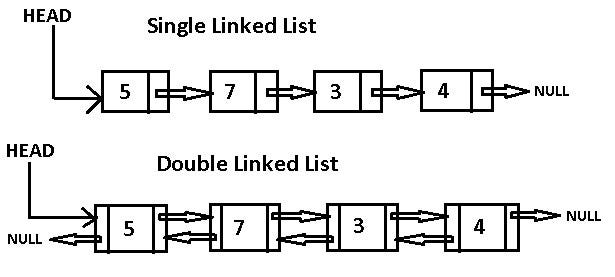
If we need to work with a list of data that is constantly updated, we might want to use a data structure known as a linked list. A linked list can be thought of like a chain — it is a group of nodes with an established head, tail, and length.
Each node contains a value and a pointer to the next node in the chain. Singly-linked lists have pointers to the next node in the list while doubly-linked lists have pointers to both the previous and the next node in the chain.
Creating a Singly-Linked List
(I recommend following along with the example at Visualgo). We need to create classes for a Node and for the List. See below for the properties of each.

In order to manipulate anything in our linked list we’ll need to follow three rules:
- Make sure to increase or decrease the length of the list when adding or removing nodes.
- Make sure the list has the correct head, tails, and all nodes have accurate pointers.
- When removing, make sure all pointers to removed nodes are severed, to ensure the node is properly deleted from memory.
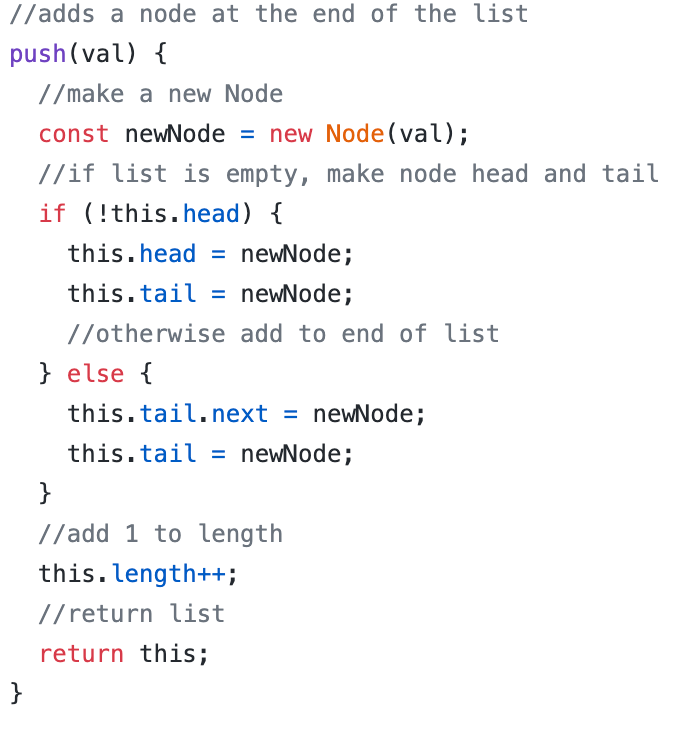
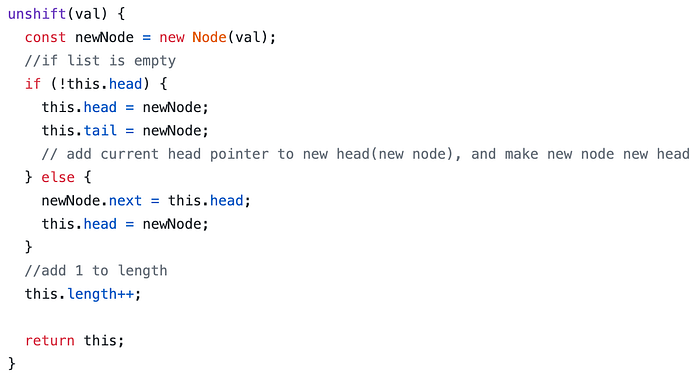
Push and unshift
When we add a node to either side of the list, we need to make sure the head and tail of our list are correct.
Since a list with one node’s head and tail are the same, we need to account for that case in our implementation. Take a look at the commented code below.
Pop and shift
When we’re removing a node from either side of the list, we’ll need to account for two more things — a list that is left with one node (because we’ll need to make sure our tail and head are accurate), and an empty list (so we can avoid runtime errors).
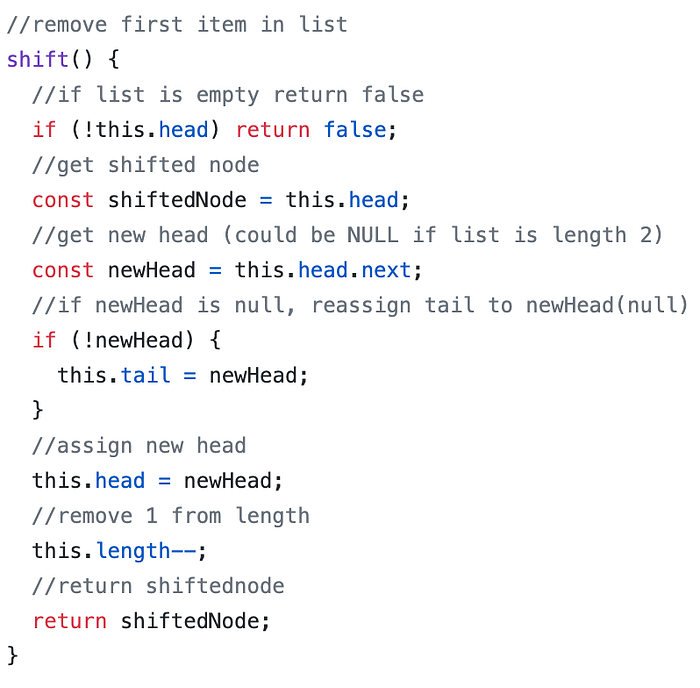
By the nature of the linked list, we have access to the new head of the list by simply checking the current head’s pointer.
However, when we are popping off of the list, we need to iterate through the list in order to find the new tail. I’ll be employing a helper method that we can reuse in later methods on our class called getNodeAtIndex.
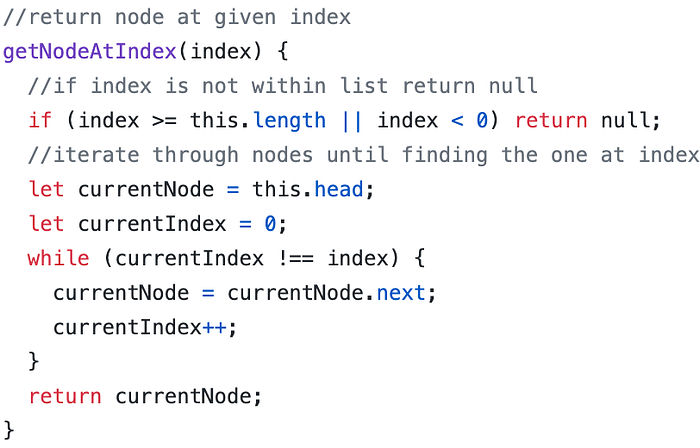
This function uses a counter and iterates through the list until we get to the index of the node we need. In this case, we’ll need the second to last node, or list length minus two.

Getting and setting
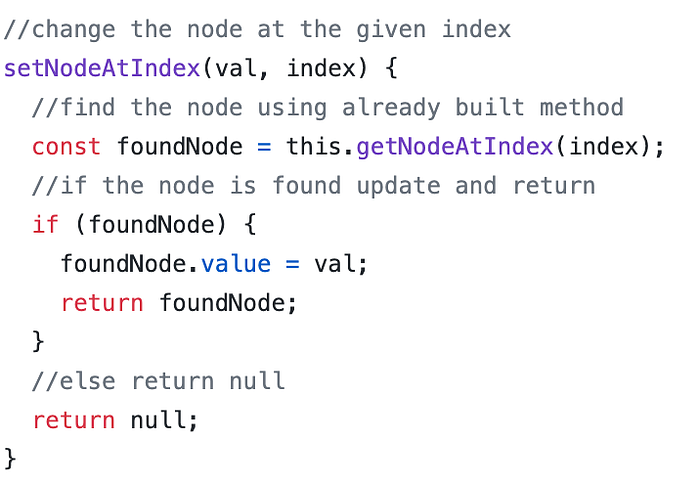
Since we already implemented the get method above for use in our pop implementation, all we need to do is implement the set method.
This method finds a node at the specified index, and changes its value to the passed-in variable. It will also use our getter method. We just need to handle the case if the node is not found.
Inserting and removing
Inserting and removing items from linked lists is made easier by all the previous methods we’ve just written. We’ll need to follow these steps:
- Check if the index exists in the linked list (return
falseif not). - If removing/adding at the beginning or end of the list, use the already written methods (no more worrying about the tail/head!).
- Get the nodes before and after the inserted/removed node and assign their pointers properly.
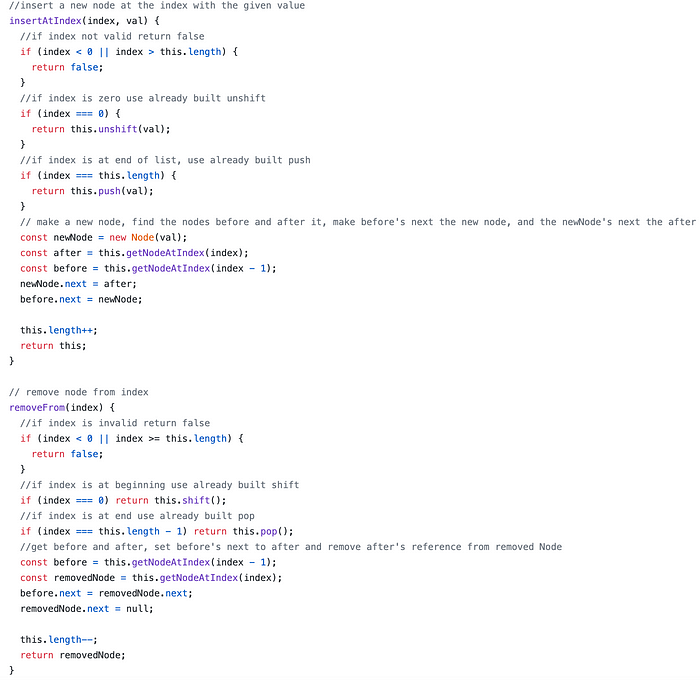
I’ve included the full implementation in a GitHub gist at the bottom of the page, along with a method to print our nodes for testing.
Doubly-Linked Lists
Doubly-linked lists have a similar implementation, but the references to both the previous and next nodes in the list have some benefits and disadvantages.
- We have to keep track of both previous and next pointers and make sure they are properly set when mutating the list.
- Since we have access to the previous node reference, we no longer need to iterate over the list for the
popmethod. - Doubly-linked lists use more memory per node since they hold two pointers, but it allows us to traverse the list in both directions.
- Doubly-linked lists have constant time for insertion and deletion at a known position while singly-linked lists have linear time.

