Member-only story
Semantic Search in Confluence Wiki With LlamaIndex and Pinecone
Exploring LlamaIndex Confluence data loader, Pinecone, and cost estimates
We will continue to expand our DevSecOps knowledge base chatbot in this article. Instead of using static PDF documents as its data source and local file storage as its vector index, we will integrate with Confluence wiki as its data source and Pinecone as its vector store.
High-Level Architecture
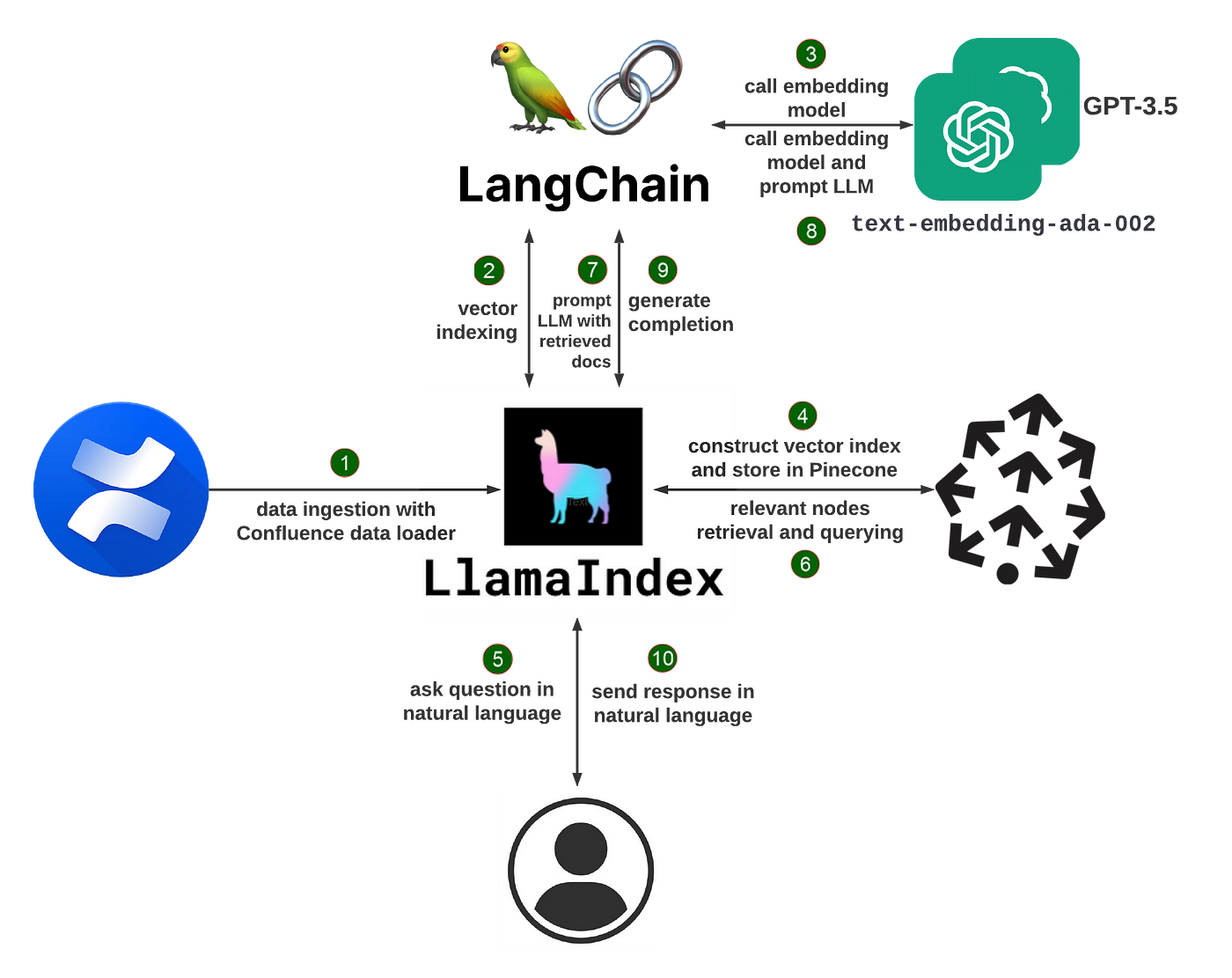
Now that we are familiar with the two-stage process of data ingestion/indexing and data querying, let’s combine the two stages into one diagram. See below. Follow the numbering for each step to walk through the overall flow.
Confluence
Confluence is a web-based collaboration and documentation platform developed by Atlassian. It is a centralized workspace where teams can create, organize, and share content, enabling collaboration and knowledge management within organizations.
Confluence allows teams to create and maintain documentation in pages, blog posts, and files. Teams can store important information, best practices, procedures, and project documentation in confluence. The content can be easily organized into spaces and subspaces, making it easy to navigate.
However, how easy is it to search for the content in Confluence? Let’s look at the search results before and after using LlamaIndex.
Lexical Search vs Semantic Search
Lexical search and semantic search are two methods of data retrieval used to find relevant information from large databases or document sources such as Confluence. Lexical search is a keyword-based search that looks for exact matches in the data sources, while semantic search is a more advanced type of search that looks at the meaning of words and phrases.
I have uploaded my five blogs mentioned in my DevOps self-service series to my Confluence wiki. In one of my Confluence pages, I converted my blog titled The Hidden Cost of Parallel Processing…

