Reduce Tail Latency at Scale: Two Classes of Patterns to Supercharge Your System’s Responsiveness
Takeaways from “The Tail at Scale” paper: what is tail latency, why you should care about it, and how to become tail tolerant

Introduction: A Small Puzzle
Let’s start with a small puzzle. Imagine the following scenario:
Let’s say you run a travel agency. You deal with customer requests to look up travel information from different datasets. To start with, you are the only person in the agency. You realize that this is impacting your responsiveness, so over time, you hire 100 backend people so that you can parallelize the operations. Each backend person now handles a specific subpart of the data.
When you get a customer request, you now “fan it out” to each of the 100 members, get a response from each based on their part of the data, put it all together, and return the final response to the customer. Let’s say each backend person’s 99th percentile (P99) latency is one minute, i.e., if you send 100 requests to one of them, only 1 of those 100 requests will take one minute or more (they are quite fast, aren’t they?).
You, as the customer-facing person, receive concurrent customer requests, and you fan out each request to your backend team.
Here’s the puzzle:
What percentage of those customer requests will take a minute or more?
If you were the only person handling the customer request and your P99 latency was one minute, the answer would have been 1%. But now you need to consider the latency of responses you are getting from each fan-out request. Even if only a small fraction of the fan-out operations took longer than usual, it would affect the overall latency at your level. If you do some simple math, you will see that a whopping 63% of customer requests in this example will take one minute or more. Because now, instead of 99% of the requests taking one minute or less, it is (0.99) power 100 = 0.366 — this means that only ~37% of requests that will take one minute or less.
What you are seeing above is the effect of “Tail Latency at Scale”. One of the interesting papers on this topic is the The Tail At Scale paper by Jeffrey Dean and Luiz André Barroso. Below, I cover my key takeaways from it.
OK, So Why Is Tail Latency at Scale a Problem?
The reason this is a problem is simple: As we saw in the above example, this can kill the responsiveness of a service. Most people don’t want to use an unresponsive system!
But is such a parallel fan-out pattern common? Absolutely. It is widely prevalent in many large-scale distributed systems — in web search, social networks, distributed file systems, etc. You need this pattern whenever you want to parallelize suboperations across many different machines, each suboperation having its own portion of a large dataset.

The paper shows that even if only 1 out of 10,000 requests to a leaf node takes one second or more, at scale when the fanout is to 2,000 servers, 20% of the overall customer requests will have a response time of one second or later. Of course, this is not good. The authors capture this as key insight #1:
Even rare performance hiccups affect a significant fraction of all requests in large-scale distributed systems.
The parallel fan-out pattern is not the only one affecting service level tail latency. In the world of microservices, you can have a chain of calls of one service calling another, which can affect the overall tail latency.
OK, So What Can We Do About It?
The paper discusses the need to make our systems latency-tail tolerant (aka tail tolerant) and a set of techniques to help us achieve it.
We already know how to make systems fault-tolerant — we can build a reliable whole out of unreliable parts. The authors use that analogy and ask:
“Can we build a predictably responsive whole out of unpredictable parts”?
I liked this analogy of comparing it with achieving fault tolerance and thought it was a good framing to think about this problem.
But Why Does the Latency Vary in the First Place?
The paper explains several situations why the latency can vary at a component level (“component” here refers to a part of the overall system/service, e.g., a leaf node involved in the fan-out). This includes aspects such as:
Resource contention: This could be due to other workloads running in the same shared environment or resource contention within the same workload. This is often one of the main reasons for the latency variability.
Background activities: Log compaction or garbage collection can increase the latency.
Queuing delays: Multiple layers of queueing can increase latency variability.
The paper talks about a few more such causes that can cause latency variability at a component level.
How To Reduce the Component Level Variability, and Can It Solve the Tail-Latency at Scale? (Hint: No)
The paper covers a few practices to reduce variability at a component level. This includes aspects such as:
- Controlling Background activities: This includes things like having good rate limiting for the background activities, ensuring that they are scheduled at times of low load, breaking them up into smaller pieces, etc.
- Having different classes of service and multiple queues: If your service serves both interactive and non-interactive requests, you should prioritize the former so that its latency is not affected by the latter. For example, this can be done by maintaining higher-level priority queues.
- Reducing head-of-line blocking: You don’t want a request at the head of a line to block or delay smaller requests behind it in the queue. The authors talk about a time-slicing approach used in Google Search to make sure CPU-intensive queries don’t affect cheaper queries.
Techniques such as the above to reduce component tail-latency are necessary but insufficient. Why? There will always be some condition (e.g., resource contention due to shared environments) that can result in higher latency in a component. The paper describes this as key insight #2:
Eliminating all sources of latency variability in large-scale systems is impractical, especially in shared environments.
So, we need other techniques to make a system tail tolerant. For this, the paper describes two classes of patterns.
The First Class of Patterns for Becoming Tail-Tolerant: “Within the Same Request”
These are a set of techniques that are applied within the context of the same customer request. These usually happen within a matter of a few milliseconds.
1. Making hedged requests
You typically have multiple replicas for serving a dataset to improve throughput and availability. The key intuition here is to use this to make our system tail tolerant.
This is a very intuitive idea: the service requests Replica #1 of some leaf node, and if it doesn’t receive a response after waiting for some time, it makes a hedged request to another replica.
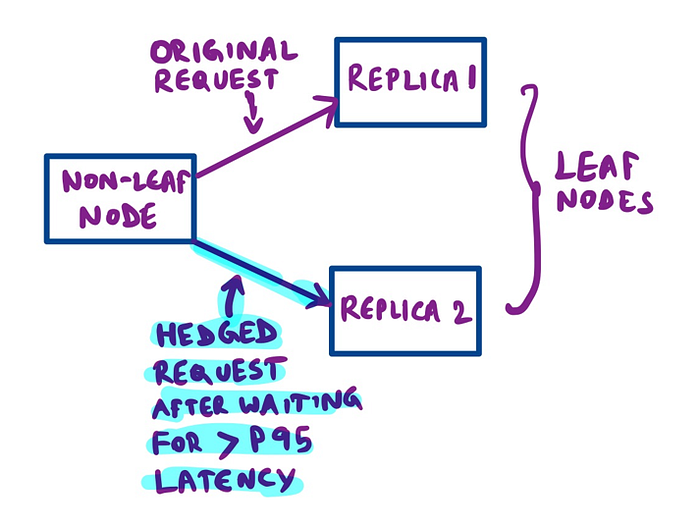
What should be this wait time? The paper suggests waiting until the expected 95th percentile time and then doing the hedged request. The paper provides this data point:
For example, in a Google benchmark that reads the values for 1,000 keys stored in a BigTable table distributed across 100 different servers, sending a hedging request after a 10ms delay reduces the 99.9th-percentile latency to retrieve all 1,000 values from 1,800ms to 74ms while sending just 2% more requests.
2. Tied requests
In the hedged requests, depending on what the wait time was, we benefited from it only for a subset of the requests — can we do more? The intuition behind this idea is that the main reason for the latency variability at a component level is queueing delays.
Hence, this approach involves requesting two replicas at almost the same time — often with a small delay in between them to account for a special case where the server queues at both replicas are empty. Replica 1 should know that the request was also sent to replica 2 and vice versa. Whichever server picks it up first processes it and also sends a lightweight cancellation message to the other replica.
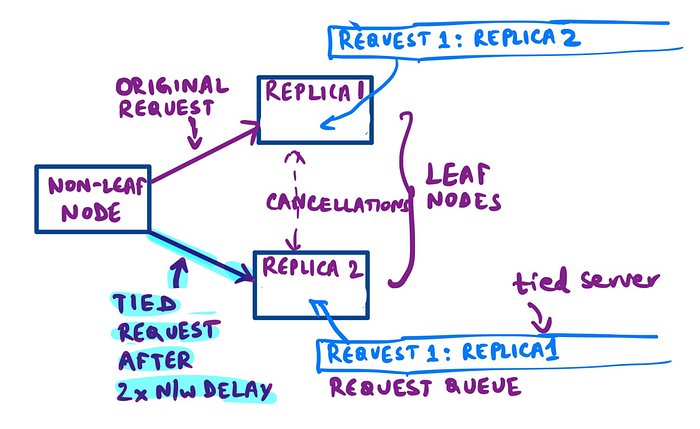
With tied requests, you can see from the table below (green arrows) around ~37% reduction in tail latency. But what’s even more interesting is that the latency profile of a tied request in a shared environment running a heavy sorting job is almost the same as the latency profile without tied requests on an idle cluster (see the blue markings). This is like getting an extra cluster for “free.” It helps have shared environments/workloads and still get more predictable performance!

3. Special considerations for large information-retrieval systems
The paper gives a few heuristics that can be applied in large information-retrieval systems where the paper says:
Speed is more than a performance metric; it is a key quality metric, as quickly returning good results is better than slowly returning the best results.
There are two techniques specific to this category:
Good enough results: In large IR systems, if a sufficient fraction of the leaf nodes have responded, the customer may be better served by returning those “good enough” results than waiting longer for the “best“ results.
This applies in other contexts where there is fanout, e.g. even within a single machine. I was part of the Windows 10 Search team about seven years back, and we did something similar there — when you typed a character in the search box, there were several search providers (apps, documents, web, email, etc.) that contributed to the results, and you wanted to balance relevance with fast, fluid results.
Canary requests: Can a bad request have the potential to take down your entire fleet? Maybe you have some newly deployed code that doesn’t handle certain types of queries well. To address this, the paper recommends “Canary request.” When a new request comes in, you send it to only one or two leaf nodes first. You fan it out in the regular manner only if those one or two are successful. The paper shows this has negligible impact and makes the system more reliable and performant.
Another Class of Patterns for Becoming Tail-Tolerant: “Across Requests”
The paper describes this as a class of techniques to reduce latency variability caused by coarser-grained phenomena. These can take time to take effect: anywhere from tens of seconds to minutes. These techniques will reduce the latency variability for future requests.
1. Using micro-partitions
Instead of associating one partition per machine, you break up a partition into multiple micro-partitions. This common pattern in most large-scale systems is also referred to as logical partitions. This serves two main benefits:
- Balancing loads is easier: It can be done more easily. In our travel agency analogy, this would mean that instead of a single large dataset associated with each backend member, you break it up into, say, 20 smaller datasets. This way, the load can be balanced at a more granular level between the different backend members.
- Faster recovery: If a machine is down and its load has to be redistributed to other machines, the load balancing can be done more granularly. In our travel agent analogy, if one member is out sick, their load can be distributed evenly among the remaining members.
2. Selective replication
What happens when you have a hot micro-partition? The paper talks about how you can selectively replicate it to more replicas: load balancers can now direct traffic to any replicas. This will help make the system more tail-tolerant.
3. Latency-induced probation
What happens when you have a slow server? Put it on probation until it behaves better. Counterintuitively, though we are reducing the overall system's capacity, it can help improve the latency of the overall system. Usually, the conditions that cause the latency variability are temporary, so the paper talks about the need for mechanisms to bring it back when those have been mitigated.
Wrapping Up
Eliminating all possible sources of latency in a large-scale system is not feasible. But borrowing from the fault-tolerance analogy, we must make such systems latency-tail tolerant. Using the two classes of software techniques above, achieving a “predictably responsive whole out of less predictable parts” can make large-scale systems more fluid and responsive.
These techniques are applicable for operations that do not mutate the system’s state: the paper explains why it is easier to tolerate latency variability for operations that mutate state.
Thanks for reading! If you have any comments, please feel free to let me know. To learn more, please check out the Tail At Scale paper!
References
- Tail At Scale paper by Jeffrey Dean and Luiz André Barroso of Google.
- Tail Latency Might Matter More Than You Think — Marc’s Blog (brooker.co.za) has some great animations (that I came across after my initial publishing of this post) that show the effects of tail latency and cover it in the context of “serial chains” as well.

