Optimizing Parallel Reduction in Metal for Apple M1
Exploring how an optimal implementation should approach the memory bandwidth of the architecture
Parallel reduction is a data-parallel primitive commonly used to reduce an array of elements into a single result. Specifically, the reduction operator sum applied to an array of elements [3, 6, 0, 8] yields 3 + 6 + 0 + 8 = 17. This operation is frequently an integral step in more complex problems. For example, in our scientific application Lumo, which is used to visualize molecular orbitals, we use parallel reduction as a part of isosurface construction to count the number of voxels that the isovalue intersects. Of course, the applications of reduction operations beyond scientific problems are extensive, with the MapReduce programming model is arguably the most well-known paradigm for big data processing.
While parallel reduction is trivial to implement on GPUs, it is a challenge to fully optimize. Mark Harris at NVIDIA published Optimizing Parallel Reduction in CUDA, which is an incredibly useful starting point to understand the pitfalls in naive implementations. With the addition of templates to kernel functions in Metal Shading Language 2.3, these optimizations can now be directly implemented in Metal to yield working computational kernels.
The diversity of architectures targeted by Metal on macOS is perhaps the bigger optimization challenge. For example, MacOS devices employ embedded GPUs from Intel and Apple and discrete GPUs from NVIDIA and AMD. These architectures differ wildly in microprocessor design, memory/cache accession and bandwidth, threadgroup scheduling, and even execution width.
Moreover, many common GPU optimizations in computational kernels translated from CUDA rely on technically undefined behavior in Metal, which no longer yields valid kernels on M1. Even though M1 builds on the A-series GPUs, intuition in the community beyond it being an awesome chip is low because many facets of the M1 architecture are (and will likely remain) undocumented. Its sheer speed hides many suboptimal kernel implementations.
Given that Apple Silicon is the future of MacOS, we will work through the optimization of parallel reduction in Metal on M1 in this article. Parallel reduction is a low arithmetic intensity operation, and thus an optimal implementation should approach the memory bandwidth of the architecture. Optimizations beyond this limit do not speed up the operation but are worthwhile as more efficient kernels use less energy. Thus, memory bandwidth limited is our primary optimization goal, with the least computational complexity as our secondary goal. The optimization problem can be decoupled into three levels:
- Load algorithm. The first level of reduction occurs per thread during the load from global memory. But how should the memory be accessed?Blocked vs striped reads across threads? 4B vs 16B reads per thread?
- Local algorithm. The second level of reduction is at the threadgroup level. Is it better to expose more parallelism or be more work efficient?
- Global algorithm. The third level of reduction is merging the reduction values of the threadgroups. Does global synchronization happen at the kernel submission boundary (i.e., a multilevel strategy) or within a kernel (via an atomic fetch-add operation)?
The two major adjustable parameters in the optimization sweep are i) threads per threadgroup, and ii) values per thread. The former depends on the register and shared memory usage to maximize occupancy on the GPU and the latter relates to algorithm cascading to maximize the cost efficiency based on Brent’s theorem. Rather than take a theoretical approach, we will brute force optimize these parameters and analyze the results.
Memory Bandwidth Baseline
The memory bandwidth for the M1 has not been officially reported by Apple, to my knowledge. The theoretical upper limit is 68.25 GB/s based on a 128-bit bus and LPDDR4X-4266-class memory. Anandtech extensively benchmarked the M1 and reported that the actual bandwidth is 60–62 GB/s, and that, remarkably, a single “performance” (Firestorm) core can almost saturate the memory bus at 59 GB/s.
Given the unified memory architecture, this might be a reasonable guess at the GPU memory bandwidth as well. Indeed, a simple memory copy kernel achieves ~55 GB/s at all threadgroup sizes tested for blocked reads up to eight values per thread, after which performance drops off rapidly. A simplified version of the kernel follows:
// Fancier versions only yield very small improvements
kernel void SimpleMemCopy(device T* output_data,
device const T* input_data,
uint global_id [[thread_position_in_grid]]) {
output_data[global_id] = input_data[global_id];
}This is impressive for an embedded GPU. Intel Tiger Lake has a theoretical memory bandwidth of 59.7 GB/s but a measured single-core bandwidth of 29.25 GB/s if that's a good estimate. M1 is much slower than modern discrete GPUs like the NVIDIA V100 that can achieve 900 GB/s, but cost $10K. Thus, our performance target for reduction is ~55 GB/s.
Load Reduce Optimization
Individual threads perform an initial sequential reduction to increase the work per thread while reading their values from device (global) memory. These reads can be blocked or striped, as shown in the figure below:
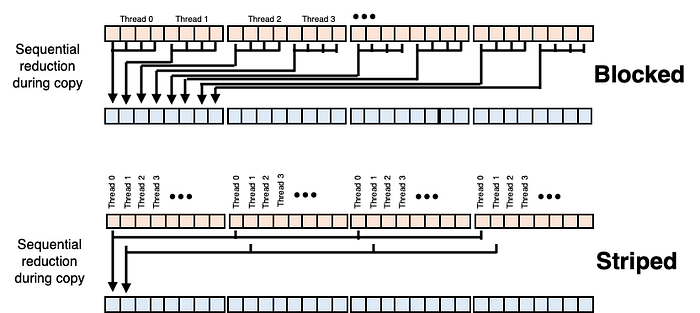
We implement the load as a template function so that we can use it with various types and operations and maximize the probability that the compiler can vectorize the loop. To enable the reuse of our reduce program with various operations (sum, product, max, min, etc.), we implement a memoryless struct and overload the () operator as follows:
struct Sum {
template <typename T, typename U>
inline T operator()(thread const T& a, thread const U& b) const {
return a + b;
}
template <typename T, typename U>
inline T operator()(threadgroup const T& a,
threadgroup const U& b) const {
return a + b;
}
};We implement two versions of our load function, one with bounds checking and one without. In kernels that are not evenly divisible into tiles (where a single tile = threads per threadgroup × values per thread), it is usually more efficient to do bounds checking and padding with a null value during the load than to dispatch a single follow-up kernel to handle the remainder. This is because the select instruction on M1 is optimal, and so there is essentially no execution divergence within the execution unit. The implementations are as follows:
// this is a blocked read into register without bounds checking
template<typename T, ushort GRAIN_SIZE, typename OPERATION>
static void LoadLocalReduceFromGlobal(thread T &value,
const device T* input_data,
const ushort lid) {
OPERATION Op;
value = input_data[lid * GRAIN_SIZE];
for (ushort i = 1; i < GRAIN_SIZE; i++){
value = Op(value,input_data[lid * GRAIN_SIZE + i]);
}
}
// this is a blocked read into register with bounds checking
template<typename T, ushort GRAIN_SIZE, typename OPERATION>
static void LoadLocalReduceFromGlobal(thread T &value,
const device T* input_data,
const ushort lid,
const uint n,
const T substitution_value) {
OPERATION Op;
value = (local_id * GRAIN_SIZE < n) ?
input_data[lid * GRAIN_SIZE] : default_value;
for (ushort i = 1; i < GRAIN_SIZE; i++){
value = Op(value, (lid * GRAIN_SIZE + i < n) ?
input_data[lid * GRAIN_SIZE + i] :
substitution_value);
}
}The GRAIN_SIZE parameter is the number of values per thread, so the number of iterations of the loop is static and fixed at compile time. Moreover, this strategy will implement fast loading in other kernels with minimal modification. Striped rather than blocked reads (i.e., indexing into input_data as input_data[local_id + BLOCK_SIZE * I]) decreases bandwidth by a full 1 GB/s. In the calling function, when performing a sum operation, the natural choice for thesubstitution_value argument would be 0, meaning that for incomplete tiles, the load statement is equivalent to value += 0 for the undefined elements. The caller of these functions would call via the following:
uint base_id = group_id * BLOCK_SIZE * GRAIN_SIZE;
LoadBlockedLocalFromGlobal<T, GRAIN_SIZE, OPERATION>(value,
&input_data[base_id], local_id, n - base_id, 0);where, as usual, BLOCK_SIZE is the number of threads per threadgroup and GRAIN_SIZE is the number of values per thread.
Threadgroup Reduces Optimization
At this point in our kernel, each thread will have a thread-local (register) variable, possibly named value that reduces the values loaded from the device’s global memory by that thread. While we could write these partial sum results directly to the output, it is more efficient to reduce within the threadgroup so that only a single thread within the threadgroup needs to write to output.
There are several algorithmic strategies to perform this reduction, but all require the threads within the threadgroup to communicate with each other. Thus, the threadgroup’s shared memory will be required, unless threads per threadgroup equal the execution width of the device (which varies by GPU architecture but is 32 on M1). Since we are focusing on M1, we will explicitly expect the SIMD execution width to be 32 in our threadgroup reductions. However, this is something to be aware of if optimizing for other devices or in the very unlikely event that it changes in future M-series chips.
Shared memory reduction
Our first reduction strategy is a simple fold-in threadgroup (shared) memory. A simplified pictorial representation of the algorithm is found below. This algorithm requires N-dim shared memory where N = threads per threadgroup. The algorithm is work efficient, requiring N-1 operations in total, which is the same as the sequential algorithm. However, because each step (S) requires half the number of threads N/(2^S), meaning the other threads in the threadgroup are idle, the algorithm is not cost-efficient. This is mitigated in part by the reduction during load described above because it increases the amount of work per thread, but also by slight modifications to the algorithm that are not shown in the simplified figure to allow execution groups (simdgroups) to exit early.
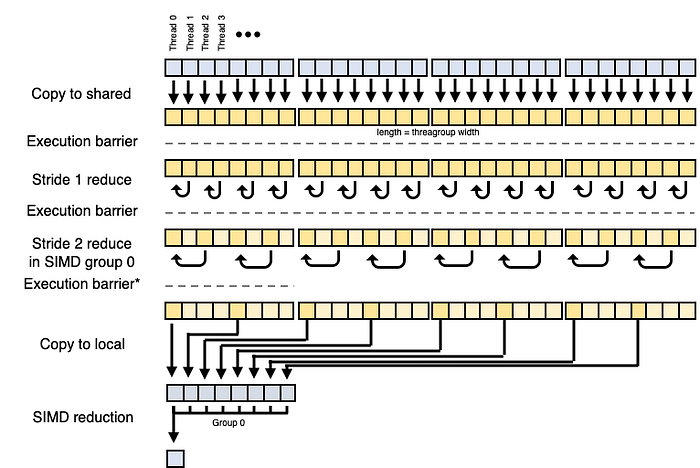
Specifically, the more optimal version of this algorithm, which is somewhat more complex to see visually, sequentially folds the values rather than doing interleaved folding (i.e., shared[x] += shared[x + BLOCK_SIZE] rather than shared[x] += shared[x + stride]). This further enables the local thread index lid to be used to index into shared and allows the final reduction to occur within a single execution unit (simdgroup). Historically the last simdgroup would continue the pattern of folding and halving the number of threads. Because this occurred in a single simdgroup, the keyword, volatile, eliminates the need for barriers as follows:
void SimdgroupSumInPlaceUnsafe(volatile threadgroup T* shared,
int lid) {
shared[lid] += shared[lid + 32];
shared[lid] += shared[lid + 16];
shared[lid] += shared[lid + 8];
shared[lid] += shared[lid + 4];
shared[lid] += shared[lid + 2];
shared[lid] += shared[lid + 1];
}It works on all architectures I have tried but is technically undefined behavior. The defined (correct) version explicitly uses execution barriers as follows:
void SimdgroupSumInPlace(threadgroup T* shared, int lid){
shared[tid] += shared[lid + 32];
simdgroup_barrier(mem_flags::mem_threadgroup);
shared[tid] += shared[lid + 16];
simdgroup_barrier(mem_flags::mem_threadgroup);
shared[tid] += shared[lid + 8];
simdgroup_barrier(mem_flags::mem_threadgroup);
shared[tid] += shared[lid + 4];
simdgroup_barrier(mem_flags::mem_threadgroup);
shared[tid] += shared[lid + 2];
simdgroup_barrier(mem_flags::mem_threadgroup);
shared[tid] += shared[lid + 1];
}At least these are simdgroup rather than threadgroup barriers, but consequently, on M1, it is always going to be the case that using thread cooperative intrinsics (i.e., T value = simd_sum(shared[lid])) will be the same or faster than both the volatile undefined or defined simdgroup_barrier() version. In our kernel, we have rewritten simd_sum using shuffle intrinsics so that we can support any binary reduction operator. Note that if you need this to work on A-series chips or other compute family devices, you should revert back to the in-place simdgroup reduce method. The reduce code is as follows:
`// This kernel is a work efficent but cost inefficient reduction in
// shared memory that can target all architectures.
// See "Optimizing Parallel Reduction in CUDA" by Mark Harris:
// developer.download.nvidia.com/assets/cuda/files/reduction.pdf
template <ushort BLOCK_SIZE, typename OPERATION,
bool BROADCAST = false, typename T> static T
ThreadgroupReduceSharedMemAlgorithm(T value, threadgroup T* shared,
const ushort lid) {
// copy values to shared memory
shared[lid] = value;
threadgroup_barrier(mem_flags::mem_threadgroup);
OPERATION Op;
// reduction in shared memory
if (BLOCK_SIZE >= 1024) {
if (lid < 512) {
shared[lid] = Op(shared[lid], shared[lid + 512]);
}
threadgroup_barrier(mem_flags::mem_threadgroup);
}
if (BLOCK_SIZE >= 512) {
if (lid < 256) {
shared[lid] = Op(shared[lid], shared[lid + 256]);
}
threadgroup_barrier(mem_flags::mem_threadgroup);
}
if (BLOCK_SIZE >= 256) {
if (lid < 128) {
shared[lid] = Op(shared[lid], shared[lid + 128]);
}
threadgroup_barrier(mem_flags::mem_threadgroup);
}
if (BLOCK_SIZE >= 128) {
if (lid < 64) {
shared[lid] = Op(shared[lid], shared[lid + 64]);
}
threadgroup_barrier(mem_flags::mem_threadgroup);
}
// final reduction in shared warp
if (lid < 32) {
if (BLOCK_SIZE >= 64) {
shared[lid] = Op(shared[lid],shared[lid + 32]);
simdgroup_barrier(mem_flags::mem_threadgroup);
}
value = shared[lid];
value = Op(value,simd_shuffle_down(value, 16));
value = Op(value,simd_shuffle_down(value, 8));
value = Op(value,simd_shuffle_down(value, 4));
value = Op(value,simd_shuffle_down(value, 2));
value = Op(value,simd_shuffle_down(value, 1));
}
// value only written to first thread, unless requested
if (BROADCAST){
if (lid == 0) shared[lid] = value;
threadgroup_barrier(mem_flags::mem_threadgroup);
return shared[0];
} else {
return value;
}
}This threadgroup algorithm assumes an execution width of 32 and uses simdgroup cooperative shuffle intrinsic, so does not employ execution barriers in the final reduction. Since BLOCK_SIZE is known at compile time, the if (BLOCK_SIZE >= X) statements evaluate and are optimized away leading to an efficient unrolled implementation for any threadgroup size up to 1,024 threads. Finally, a template parameterBROADCAST is also given so that, if needed, the threadgroup reduction value can be returned to all threads rather than just the first thread at the cost of another threadgroup barrier.
Raking reduction
The inefficient cost complexity of the algorithm above can be mitigated by sacrificing some parallelism. Specifically, we can sum the values in shared memory with just the first execution unit (simdgroup). This algorithmic strategy is called “raking.” This algorithm also works efficiently and requires the same N-dim threadgroup (shared) memory where N = threads per threadgroup.
The choice of how many values (M) each thread in the raking group reduces is threads_per_threadgroup / execution_width. Recall execution width on M1 is 32, and so if the threadgroup size is 256, then each thread in simdgroup 0 (i.e., thread index < 32) rakes eight values. This does mean that the threads per threadgroup should be a multiple of the execution width, which normally should be the case for optimal performance anyway.
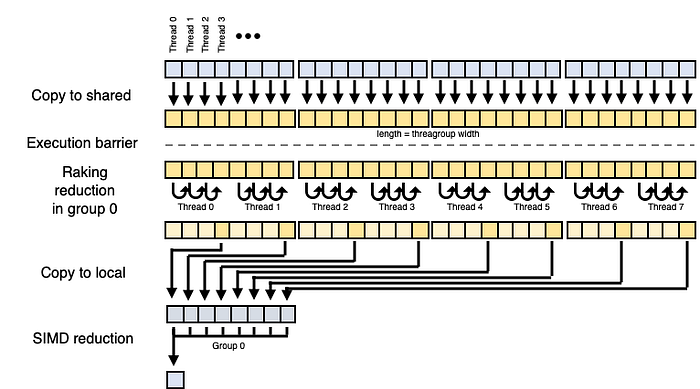
Now, the active threads are saturated with work for the sequential reduction of the M values per thread, which drives the cost down to O(N). This is the most efficient algorithm from a cost perspective and, given a large enough number of threads will maximize throughput on the GPU. To put that in perspective, the M1 GPU can run 24,576 concurrent threads. At an execution width of 32 threads active per simdgroup, this translates to 768 threadgroups.
Thus, with a low arithmetic intensity operation like reduce, this algorithm is unlikely to achieve 100% occupancy on M1 and thus will give lower turnaround times unless the data is enormous (10s of millions to billions of values), but the concept is important for other parallel primitives like prefix scan. The raking code is as follows:
// This kernel is a work efficent rake in shared memory that can
// target all architectures.
// Kernel is inspired by CUB library by NVIDIA
template <ushort BLOCK_SIZE, typename OPERATION,
bool BROADCAST = false, typename T> static T
ThreadgroupReduceRakingAlgorithm(T value, threadgroup T* shared,
const ushort lid) {
OPERATION Op;
// copy values to shared memory
shared[lid] = value;
threadgroup_barrier(mem_flags::mem_threadgroup);
// first warp only in this algorithm
if (lid < 32){
// interleaved addressing to reduce values into 0...31
for (ushort i = 1; i < BLOCK_SIZE / 32; i++) {
shared[lid] += shared[lid + 32 * i];
}
// final reduction phase
value = shared[lid];
value = Op(value,simd_shuffle_down(value, 16));
value = Op(value,simd_shuffle_down(value, 8));
value = Op(value,simd_shuffle_down(value, 4));
value = Op(value,simd_shuffle_down(value, 2));
value = Op(value,simd_shuffle_down(value, 1));
}
// value only written to first thread, unless requested
if (BROADCAST){
if (lid == 0) shared[lid] = value;
threadgroup_barrier(mem_flags::mem_threadgroup);
return shared[0];
} else {
return value;
}
}Cooperative reduction
Our final option is to expose more parallelism by eliminating execution barriers, which is accomplished by sacrificing step efficiency. In this algorithm, each execution unit (simdgroup) reduces its value cooperatively and then stores its result into a block of shared memory, where execution mirrors the above kernels for the final reduction.
Unlike the shared memory reduction algorithm, where the number of threads were halved for each step of reduction, N / (2^S) or O(log N), and that with intelligent indexing could allow simdgroups to exit the function early, the same mitigation is not possible because simdgroup based cooperative algorithms require N threads for N elements. This makes the overall cost O(N²) instead of O(N log N) in the shared memory algorithm.
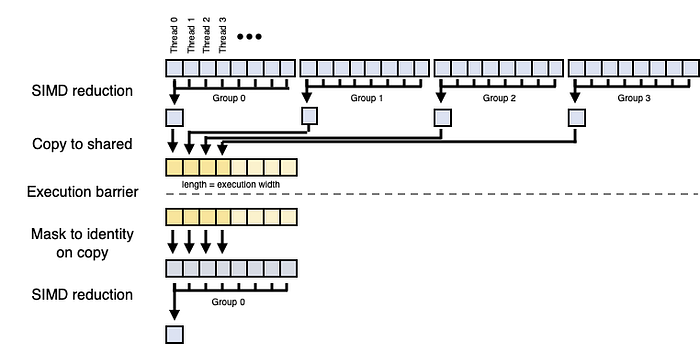
Nevertheless, this might be a good tradeoff when the occupancy of threads is low and certainly in situations bound by the availability of threadgroup (shared) memory, as this algorithm only requires enough shared memory to hold an execution width worth of elements rather than a threadgroup size worth. Here is the code:
// This is a highly parallel but not work efficient algorithm,
// which sometimes yields faster turnaround times
// this kernel requires EXECUTION_SIZE shared memory
template <ushort BLOCK_SIZE, typename OPERATION,
bool BROADCAST = false, typename T> static T
ThreadgroupReduceCooperativeAlgorithm(T value,
threadgroup T* shared,
const ushort lid) {
OPERATION Op;
// first level of reduction in simdgroup
value = Op(value,simd_shuffle_down(value, 16));
value = Op(value,simd_shuffle_down(value, 8));
value = Op(value,simd_shuffle_down(value, 4));
value = Op(value,simd_shuffle_down(value, 2));
value = Op(value,simd_shuffle_down(value, 1));
// exit early if our block size is 32
if (BLOCK_SIZE == 32) {
if (BROADCAST) value = simd_broadcast_first(value);
return value;
}
// first simd lane writes to shared
if (lid % 32 == 0) { // lid % 32 simd_lane_id
shared[lid / 32] = value; // lid / 32 = simd_group_id
}
threadgroup_barrier(mem_flags::mem_threadgroup);
// final reduction in first simdgroup
if (lid < 32) {
// mask the values on copy
value = (lid < BLOCK_SIZE / 32) ? shared[lid] : Op.identity();
// now reduce
value = Op(value,simd_shuffle_down(value, 16));
value = Op(value,simd_shuffle_down(value, 8));
value = Op(value,simd_shuffle_down(value, 4));
value = Op(value,simd_shuffle_down(value, 2));
value = Op(value,simd_shuffle_down(value, 1));
if (BROADCAST) shared[lid] = value;
}
if (BROADCAST) threadgroup_barrier(mem_flags::mem_threadgroup);
return BROADCAST ? shared[0] : value;
}Global Reduce Optimization
Metal, like CUDA and OpenCL, has no global synchronization primitives, so the kernel submission boundary functions as a global synchronization point for threadgroups. Consequently, this usually implies that when the number of values to reduce is too large to do in a single threadgroup, a multilevel strategy is employed where threadgroups are dispatched and reduce their respective values into a partial reduction array.
A second kernel dispatch occurs to reduce the partial reduction values, and so on, until the operation is complete. While the instruction overhead is low because kernel dispatch is relatively inexpensive, it does mean additional device (global) memory is required (N / values) per level. Moreover, it also means that another round trip to memory is required.
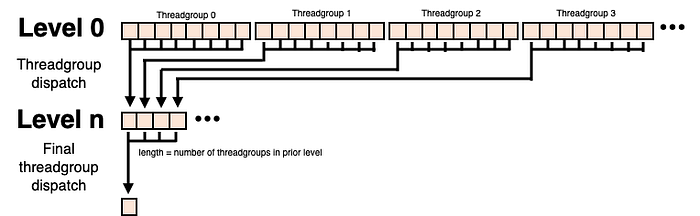
Since we have reduced it to a single value, only the first thread of the threadgroup writes the value to the device’s global memory. The code is very simple:
// write result for this threadgroup to global memory
if (local_id == 0) {
output_data[group_id] = value;
}Alternatively, while no global threadgroup synchronization primitives exist, global atomics for 32-bit signed and unsigned integers are available. These operations are very fast and will easily beat the multilevel strategy when applicable:
// write result for this threadgroup to global memory
if (local_id == 0) {
atomic_fetch_add_explicit(output_data, value,
memory_order_relaxed);
}Thus, for all signed or unsigned integer types 32-bit or less (char, short, and int), reduction using this specialization is appropriate. The multilevel strategy must be used for floating-point types or when the reduction value overflows the 32-bit type. Our final two kernels, the default multi-level reduction kernel and the atomic specialization, are as follows:
// Multi-level reduction kernel
template<ushort BLOCK_SIZE, ushort GRAIN_SIZE,
typename OPERATION = Sum, typename T, typename U,
typename V> kernel void
ReduceKernel(device V* output_data,
device const T* input_data,
constant uint& n,
threadgroup U* scratch,
uint group_id [[ threadgroup_position_in_grid ]],
ushort local_id [[ thread_index_in_threadgroup ]]) {
uint base_id = group_id * BLOCK_SIZE * GRAIN_SIZE;
// reduce during the load from global
U value;
if (DISABLE_BOUNDS_CHECK) {
LoadLocalReduceFromGlobal<GRAIN_SIZE,OPERATION>(value,
&input_data[base_id], local_id);
} else {
OPERATION Op;
LoadLocalReduceFromGlobal<GRAIN_SIZE,OPERATION>(value,
&input_data[base_id], local_id,
n - base_id, Op.identity());
}
// reduce the values from each thread in the threadgroup
value = ThreadgroupReduce<BLOCK_SIZE,OPERATION,U>(value,
scratch,
local_id);
// write result for this threadgroup to global memory
if (local_id == 0)
output_data[group_id] = value;
}
// Atomic reduction kernel
template<ushort BLOCK_SIZE, ushort GRAIN_SIZE,
typename OPERATION = Sum, typename T, typename U,
typename V> kernel void
AtomicReduceKernel(device V* output_data,
device const T* input_data,
constant uint& n,
threadgroup U* scratch,
uint group_id [[ threadgroup_position_in_grid ]],
ushort local_id [[ thread_index_in_threadgroup ]]) {
uint base_id = group_id * BLOCK_SIZE * GRAIN_SIZE;
// reduce during the load from global
U value;
if (DISABLE_BOUNDS_CHECK) {
LoadLocalReduceFromGlobal<GRAIN_SIZE,OPERATION>(value,
&input_data[base_id], local_id);
} else {
OPERATION Op;
LoadLocalReduceFromGlobal<GRAIN_SIZE,OPERATION>(value,
&input_data[base_id], local_id,
n - base_id, Op.identity());
}
// reduce the values from each thread in the threadgroup
value = ThreadgroupReduce<BLOCK_SIZE,OPERATION,U>(value,
scratch,
local_id);
// write result for this threadgroup to global memory
if (local_id == 0)
atomic_fetch_add_explicit(output_data,
value,
memory_order_relaxed);
}Metal Shading Language 2.3 brings the ability to use templates with kernel functions. This makes it trivial to generate specialized functions as follows:
// Explicit specializations of `ReduceKernel<T,U,V>` with
// [T=input, U=intermediary, V=output]
#if defined(THREADS_PER_THREADGROUP) && defined(VALUES_PER_THREAD)
template [[host_name("reduce_sum_uint32")]] kernel void ReduceKernel<THREADS_PER_THREADGROUP,VALUES_PER_THREAD,Sum,uint,uint,uint>(device uint*, device const uint*,constant uint&, threadgroup uint*, uint,ushort);
template [[host_name("reduce_sum_uint32_atomic")]] kernel void AtomicReduceKernel<THREADS_PER_THREADGROUP,VALUES_PER_THREAD,Sum,uint,uint,atomic_uint>(device atomic_uint*, device const uint*,constant uint&,threadgroup uint*,uint,ushort);
#else
template [[host_name("reduce_sum_uint32_256threads_4way")]] kernel void ReduceKernel<256,4,Sum,uint,uint,uint>(device uint*, device const uint*,constant uint&,threadgroup uint*,uint,ushort);
template [[host_name("reduce_sum_uint32_256threads_4way_atomic")]] kernel void AtomicReduceKernel<256,4,Sum,uint,uint,atomic_uint>(device atomic_uint*,device const uint*,constant uint&,threadgroup uint*,uint,ushort);
#endifAlthough it's convenient to have template support directly in the language, it's also equally valuable to use function constants as well to manipulate control flow when the MTLComputePipelineState is created. This makes it easy to specialize kernels for different architectures at run time, which makes your metal libraries much smaller. Our kernels rely specifically on the following:
// these constants control the code paths at pipeline creationconstant int LOCAL_ALGORITHM [[function_constant(0)]];
constant int GLOBAL_ALGORITHM [[function_constant(1)]];
constant bool DISABLE_BOUNDS_CHECK [[function_constant(2)]];
constant bool USE_SHUFFLE [[function_constant(3)]];
which are set in the host code.
Parameter Sweep
Now having functioning local and global algorithms, we need to determine the optimal threadgroup parameters. For this test, we wanted to ensure that we had enough values in the data to saturate the device, which was achieved easily at 128M uint32_t samples (so 512 MB buffer size). The three local algorithms without bounds checking were tested over threadgroup sizes [32, 64, 128, 256, 1024] and values per thread of [1, 2, 4, 8, 16, 32].

All algorithms are performed at the memory bandwidth limit (~58 GB/s) for two and four values per thread. Threadgroup sizes of 256 and 512 were statistically higher but just fractionally compared to other threadgroup sizes but within error of each other. Consequently, we will be using 256 threads per threadgroup and two values per thread for our next benchmark.
Comparative CPU Performance
We have now optimized parallel reduction in Metal. It is worth mentioning that because reduction is low arithmetic intensity and amenable to vectorization, the CPU cores of M1 can also accomplish this task at or close to the memory bandwidth limit. The Accelerate framework provided by Apple contains the vDSP library that is highly tuned on every architecture (including M1) and can compute the sum of a float array using the function:
void vDSP_sve(const float* bytes, vDSP_Stride stride, float* result, vDSP_Length n)
An integer version of this function is not available (but a double version is available), but efficient vectorized code for other types can be generated by using the following:
// calculates the sum of values in a vector of int
void simd_svei(const int* bytes, int* result, size_t n){
if (n == 0) return 0.0;
simd_int16* vector = (simd_int16*)bytes;
// aggregate by simd addition
size_t length = n / 16;
simd_int16 aggregate = vector[0];
for (size_t i = 1; i < length; i++){
aggregate += vector[i];
}
// simd reduction
*result = simd_reduce_add(aggregate);
// do the remainder
for (size_t i = length * 16; i < length; i++){
*result += bytes[i];
}
}These results are impressive when compared to the vDSP library code and the GPU reduction results.
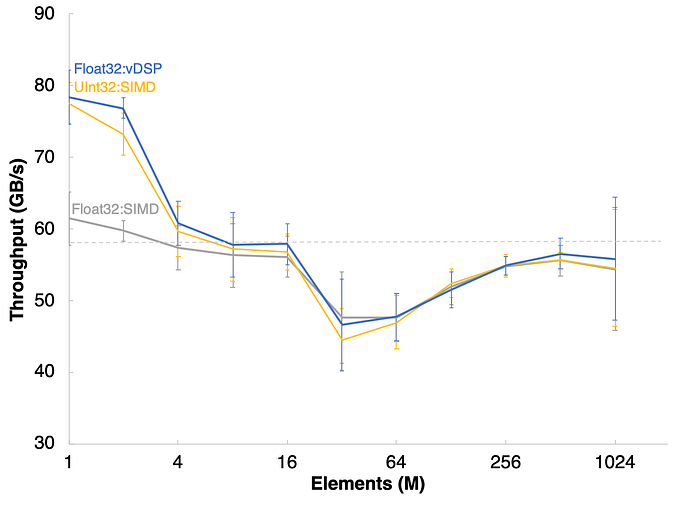
While throughput is a useful check to understand the performance characteristics of a given algorithm, the real metrics are time to complete a task and energy usage.
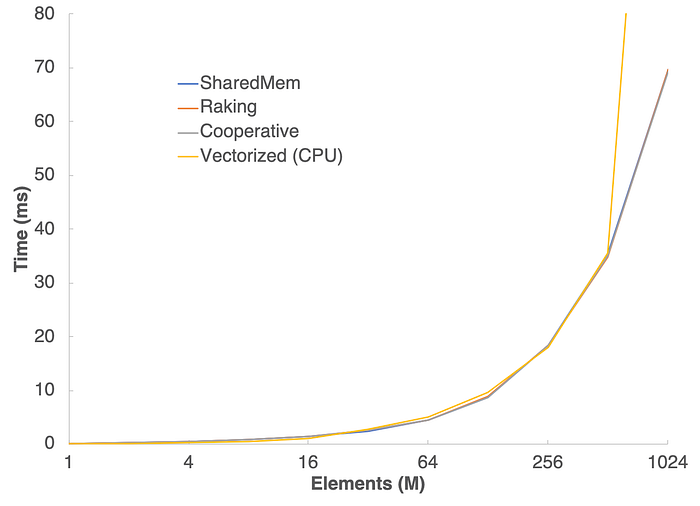
This is the expected result for a memory-bound computation after you realize that a single performance core on the M1 can saturate the memory controller, which is impressive. Hopefully, in your own code, if you need a threadgroup reduction as part of a larger computational problem, you can choose which tradeoff is most appropriate — more parallelism vs overall cost and pick the appropriate local algorithm.
Given these results, it seems unlikely that there would ever really be a need to fire up Metal for a one-off vector summation, as the M1 performance cores are more than up to the challenge, especially considering the low overhead of the CPU code. However, the GPU is likely much more energy efficient, and so if the reduction is an integral part of a larger computational problem, the GPU pathway is likely the way to go.
In passing, the unified memory architecture of the M1 means there is no data transfer penalty even if CPU operations like reduce are interspersed within larger computational problems performed on the GPU. We would anticipate that more complex operations (like parallel prefix scan) that have significantly higher arithmetic intensity and do not vectorize as easily will not be able to be parallelized to run at the memory bandwidth limit on the CPU and, consequently, will generate a sizable performance gap between CPU and GPU. I will write about it next time.
Thanks for reading!
Edited March 16, 2021: I slightly changed the code below to benchmark it on my old 2014 Mac Mini. The benchmarks above are unchanged.

