Navigating the Minefield of RocksDB Configuration Options
Unleashing the full potential of your RocksDB with the right configuration
Embedded DBs have become commonplace in a lot of new distributed systems. They offer a way to store a lot of data on a local disk, thereby providing good performance compared to a database located on a different server. They are also lightweight, so they don’t put a lot of pressure on the main application running on the same server.
Facebook (now Meta) created RocksDB, which is the crown jewel among the embedded DBs. It is used in popular libs such as Apache Flink, MyRocks SQL engine, and more.
RocksDB has a lot of information on its website, but it is hard to find all the configuration options. As a new user, it was difficult for me to understand which configurations were important to set, what they meant, and where to change them.
This is what I plan to tackle in this article. All the options discussed here are applicable for Block-based table formatand may not apply to the Plain or Blob table format. It is also not an exhaustive list of options but instead the most popular and useful selection.
Use Your Fuel Wisely!
Memory optimization is crucial for any database, and RocksDB is no exception. By maximizing the efficiency of your memory usage, you can improve the speed of both reads and writes in your database. Memory is used for two key structures in RocksDB: the cache and the memtables.
Block cache
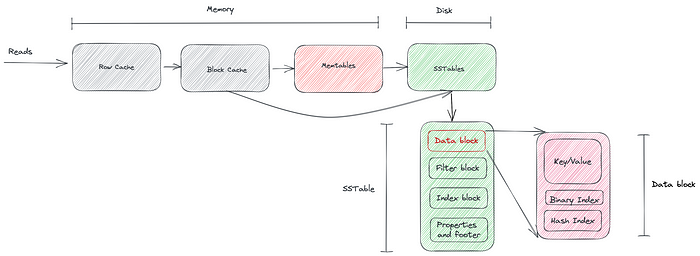
RocksDB comes with various types and levels of cache for improving read speeds. The most common one is the Block cache. It is enabled by default with a max size of 8MB. As the name indicates, the block cache stores the SSTable blocks. They can be data blocks, index blocks, filter blocks, or something else. Most of the time, you will want to increase this cache size to improve speed.
RocksDB has two cache options: LRUCache, which is the default, and ClockCache. ClockCache is faster because it doesn't need locks, but it doesn't provide the same guarantees as LRUCache. It was also marked as experimental until November 2022.
Row cache
This cache is used for storing actual data for a key. The cache’s documentation is almost non-existent, but it provides fast data access in case you do a lot of point lookups. RocksDB first looks in the row cache and then in the block cache for the data. Like block cache, you can use either LRUCache or ClockCache as the actual implementation for row cache.
Cache filters — Other than the data blocks, you can also ask RocksDB to cache index and filter blocks. These blocks need to be accessed almost every time to need to look up a key in the data block. Caching these blocks improves the read latencies while trading off memory. The following options can be used:
cache_index_and_filter_blocks— Set it totrueto enable caching these blocks.cache_index_and_filter_blocks_with_high_priority— Set it totrueso that these blocks are cached in the high-priority region of the LRU cache. These blocks are evicted much later than the low-priority region in case the cache is full.pin_l0_filter_and_index_blocks_in_cache— L0 level requires reading all the files since they have overlapping key ranges. Enabling this always keeps the L0 filter and index blocks in the cache
Memtable
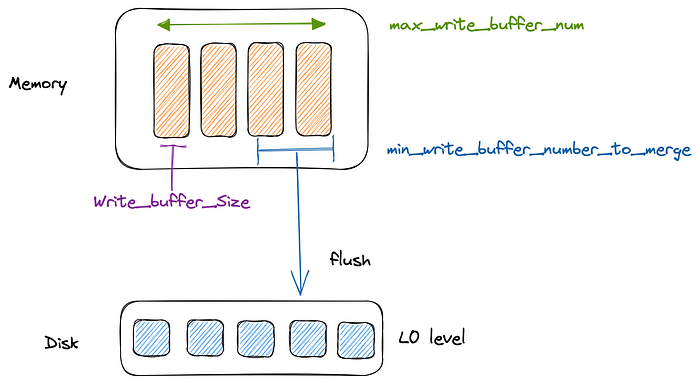
RocksDB writes go first to Memtables, a data structure that resides in the memory. These tables are then flushed to the L0 level in the DB. Since memory is a precious resource, you need to control the size of the memtables in the RocksDB and the frequency of flushes.
This is possible via the following configs:
write_buffer_size— this is the max size of each memtable that RocksDB can create. Beyond this size, a new memtable is created, and the existing one is queued up for flushing to the disk. The default value is 64MB.max_write_buffer_number— these are the max number of memtables that can exist in the memory before a flush is triggered. The default is two so that when the first memtable is flushed, the writes can continue on the second memtable.min_write_buffer_number_to_merge— minimum number of memtables that will be merged before a flush is triggered. The merge operation happens in memory. This can help you reduce disk io for flushes, especially if memtables contain a lot of duplicate keys or deletes. The default is one, so no memtables are merged.db_write_buffer_size— this is the max size of all memtables combined across column families. The default is -1, which means there is no global limit on memtables. If you set it to a value > 0, RocksDB will initialize aWriteBufferManagerthat keeps track of all memtables sizes across column families.
You can grep for flush_reason stats in the RocksDB Log file to check the size of the column family before getting flushes as well as the reason it flushed. For example, you will see values like Write Buffer Fullwhich means it was triggered because of max_write_buffer_number or you will see a value like Write Buffer Manager which is because of db_write_buffer_size.
Memtable formats
There are four supported memtable formats in RocksDB:
SkipListHashSkipListHashLinkListVector
You can go through the official wiki for more detail on these formats. The default is SkipListFactory which performs well for almost every use case. It is the only one that can support concurrent writes. The flushes are also faster for this memtable format.
The second format that you can try is the Vector memtable. It provides good performance if you do a lot of random writes. Some popular frameworks, such as Kafka Streams, use this table format.
Use the Expressway, Not Single-Lane Roads!
IncreaseParallelism — The number of threads RocksDB will use for all background operations. Even if you increase the max_background_jobs but keep parallelism as 1, it won’t lead to a lot of performance increase. Ideally, this option should be kept equal to the number of cores in your machine.
Max_Background_Jobs — These are the number of flushes and compactions that can be scheduled in parallel on your threads. Flushes take higher priority, while compactions take lower priority by default. This is so that a compaction operation doesn’t block any writes to the databases.
CPU usage is also affected by compaction. We will take a look at the compaction options in the next section since they are more I/O intensive than CPU intensive.
Avoid Walls and Slow Corners!
Since RocksDB is a database, it is expected that you’ll be hitting I/O bottlenecks sooner or later. The two most I/O-intensive operations are flush and compaction. Flushes are mostly tuned by adjusting the memtable sizes and numbers. We have already gone through those in the Memtables section.
Compaction
RocksDB performs compactions in the background where multiple SSTables files are merged. It also removes deleted keys from the file. A new SSTable file is created and then put into the same or different LSM level. The following options can be used to tune the whole process:
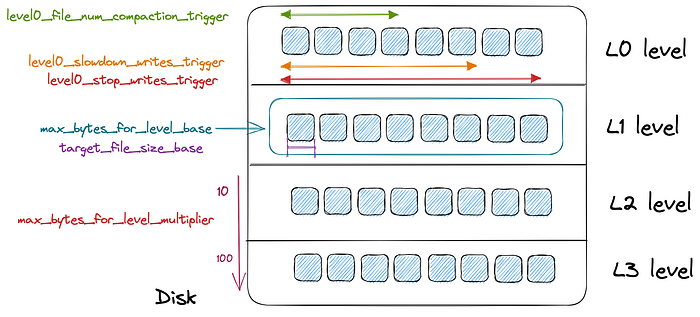
level0_file_num_compaction_trigger — L0 is the first level in RocksDB. It is where all Memtables are flushed. You can control the number of files that should be present in the L0 level before a flush is triggered. Increasing this config means compactions occur much less frequently but need to process a lot of data.
level0_slowdown_writes_trigger — Compactions occur on low-priority threads by default in RocksDB. Compactions may get delayed due to no available threads. In such cases, you may want to slow down writes so compactions don’t have to process extreme amounts of data when they get scheduled. This config is used for that. By default, the limit is 20 files at the L0 level.
level0_stop_writes_trigger — Similar to the previous, but once the number of files at the L0 level reaches this limit, we stop processing writes altogether and may schedule compaction. By default, the limit is 36 files.
target_file_size_base — RocksDB needs an estimate of how large files it should create on each level starting from L1. By default, this file size is 64MB for L1, and then it gets multiplied by target_file_size_multiplier for the next level. By default, the multiplier is 1, so all levels will have similar-sized files.
max_bytes_for_level_base — Max amount of data that can be present in L1-Level. By default, this is 256 MB. For levels greater than L1, this base size is multiplied by max_bytes_for_level_multiplier. So L2 can contain 256 * 10 = 2GB of data, L3 can contain 256 * 10 ** 2 = 20GB of data, and so on.
subcompactions — Compactions that occur for L0 → Ln files can’t run in parallel. The only way to speed them up is to partition the data into appropriate key ranges and then run sub-compactions on each of those partitions. By default, it is 1, which means the sub-compactions are disabled. You can refer to the official wiki for more scenarios in which sub-compactions can help.
disable_auto_compactions — Disables the compactions altogether. You should use it for Bulk loads when a lot of data is written to RocksDB. Post the bulk load, and you can trigger manual compaction, so the number of files gets reduced.
Use the Fastest Route!
RocksDB uses an LSM tree for managing data. LSM trees are quite good for write-heavy workloads but struggle under read-heavy workloads. The DB has to go through a lot of files to get a particular key. Besides enabling Cache, RocksDB offers multiple ways to improve read speeds by reducing lookups. Here’s those methods:
Bloom filters — RocksDB allows SSTable level bloom filters so you can skip reading indexes if a key is not in a particular file. You can set the number of bits to control the accuracy of a bloom filter.
whole_key_filtering — If you do a lot of point lookups, generally, using this setting can give you better results. All the filters, such as the bloom filter, will use all the bytes of the key rather than only a few prefix bytes. This option only affects the SSTables.
Hash index — RocksDB uses a binary search index by default to look up blocks and then search for keys inside a block. You can, however, switch to the hash index. This allows for faster lookups but uses more space. You can use the following configs to enable and tune the hash index.
data_block_index_type—kDataBlockBinaryAndHash. This adds a hash index at the end of the data block. Without it, only binary search will be used to find a key inside a data block.data_block_hash_table_util_ratio— This is theload_factorfor this hashtable, i.e., (number_of_entries / number_of_buckets). Setting it to less than1means there are more buckets than the number of entries reducing the number of reads for point lookups. Setting it to >1means each bucket can contain multiple elements, but the space used by the hash index will be lower.kHashSearch— This modifies the Index block to use hash search instead of binary search to lookup data blocks. This differs from the above config as it is used to find data blocks in a file. ThekDataBlockBinaryAndHashis used to find keys/restart intervals inside a data block.
memtable_prefix_bloom_size_ratio — By default, the bloom filters are created at file levels. If you enable this option, a bloom filter is also created in the memtable for queries that go beyond the memtable to disk. The config determines the ratio of the memtable (i.e., write_buffer_size) that should be used for this bloom filter. Max value allowed is 0.25, i.e., 25%.
memtable_whole_key_filtering — If set to true, the bloom filter created using the previous config will contain complete key bytes instead of just prefixes. This is useful for point lookups. This option is different from whole_key_filtering, which affects only the SSTable files.
prefix_extractor — You can also tell RocksDB to use only the first few bytes of your keys in the indices instead of using the whole key. This helps in reducing space used for indices and filters. It also optimizes range queries. The most commonly used one is the FixedLen prefix extractor, where you can specify the number of bits it should use from the key.
Conclusion
The config options mentioned here are not exhaustive. You can scourge through the official wiki OR lookup comments in one of the options C++ file linked at the bottom. RocksDB offers certain helper methods, which you should use to set good enough defaults before you tune the options yourself. Examples of such methods include the following:
options.OptimizeForPointLookup— To improve read latenciesoptions.PrepareForBulkLoad— To reduce compaction and rate-limiting while loading a lot of data in the DBoptions.OptimizeLevelStyleCompaction— To improve compaction speeds and minimize the total number of compactions
Also, don’t forget to set your table format version to the latest. By default, it is 4 for backward compatibility, but the latest version is 5. By making this change, you’ll be able to take advantage of all the SSTable improvements in the latest RocksDB releases.
You can use the following references to learn more about RocksDB:
- Options C++ Code which contains most of the preset options
- Memtable Wiki
- Block Cache Wiki
Want to Connect?
You can find me on LinkedIn, Twitter, or send an email to
kharekartik@gmail.com to share feedback.
