Multi-threaded Application With Simple Apache Kafka Consumers
With code examples in Kotlin
The first time any new-to-Kafka engineer tries to do anything more complex than a simple read-quick process-write, they inevitably need to work around the fact that the KafkaConsumer is not thread-safe (see doc).
The way Kafka is architectured, it naturally forces you to scale horizontally by adding more consumers in a group. In Kafka, all records in a topic are grouped in partitions, which can be written to and read from independently without compromising the quality of the data.
So, if we want more processing power we need to have more partitions and at least as many consumers in a group subscribed to that topic, where each consumer is a separate thread. (The number of consumers can be greater or equal to the number of partitions, any excess consumers will just stand by in case one of the others breaks.)

This is is not the multi-threading we will discuss though. The thread-per-consumer model is the easy bit. It is, however, based on the assumption that most use-cases will involve a simple and quick processing step after the records are consumed. In real life, sometimes, we need to do more than appending a field or two to the messages, we might need to do some I/O operations, complex computing, call a third party API, or coordinate with other bits of the application.
Then, we’ll need to build something custom to work around the limitations of the library. Like any other engineering problem the first approach that comes to mind is not what we want to end up with but let’s start with it and follow the natural progression.
Approach 1 — just use flags (Duh..)
Let’s say we have a consumer that needs to be notified when to close. Of course, we add a simple flag and check it in a loop, right?
...
private final closed = new AtomicBoolean(false);
...// this runs in a separate thread than the main
try {
consumer.subscribe(Arrays.asList("topic"));
while (!closed.get()) {
val records = consumer.poll(Duration.ofSeconds(1));
// processing..
}
} catch (e: Exception) {
// Ignore exception if closing
if (!closed.get()) throw e;
} finally {
consumer.close();
}
Now, let’s assume we work with an application where the processing needs to finish successfully before committing so we have turned off the auto-commit and we are manually controlling it.
Also, to top that off we need the data from one topic to be processed using bits and pieces from another one or send that off to a third party API to transform and we need to wait for the result back.
So, with that heavy task on our hands, we go ahead and… add more flags, naturally.
...
private final closed = new AtomicBoolean(false);
private final readyToCommit = new AtomicBoolean(false);
...try {
consumer.subscribe(Arrays.asList("topic"));
while (!closed.get()) {
val records = consumer.poll(Duration.ofSeconds(1));
// start processing in another thread - call API, stitch data from this topic with another etc..
while (!readyToCommit.get()) {
// idle loop?, maybe add Thread.sleep() or delay()
}
}
} catch (e: Exception) {
// Ignore exception if closing
if (!closed.get()) throw e;
} finally {
consumer.close();
}
That doesn’t look nice, does it? What if we have more points of contact with other threads? What if there is an event that would require a pause, writing a state or intermittent stats to a file, or maybe even closing the consumer but without stopping the thread to allow it to rejoin later with another event? That would mean so many more flags, so much more room for error.
Think we can all agree using plain booleans to navigate this is not optimal and scalable. Let’s move on to the next option.
Approach 2 — turn the flags into a state machine
How would that be better? Well, if done right, this would give you a single point of control, access, and also failure. It would make the code more readable, error handling a bit easier, and debugging a bit more bearable (multi-threading never is).
We’ll consider the following states:
enum class State {
SUBSCRIBING,
CONSUMING
PAUSING,
PAUSED,
RESUMING,
CLOSING
CLOSED,
TERMINATING,
IN_ERROR; fun isHealthy(): Boolean {
return this != IN_ERROR
} fun shouldRun(): Boolean {
return this != TERMINATING
}
}
It’s important to define clear and tight rules as to what transitions are valid, what might occur in a multi-threaded case but are acceptable, and what is a sign of the issue i.e what is the normal flow, what would be considered a warning, and what is supposed to raise an alert.
For the above states we could agree on the following flow:
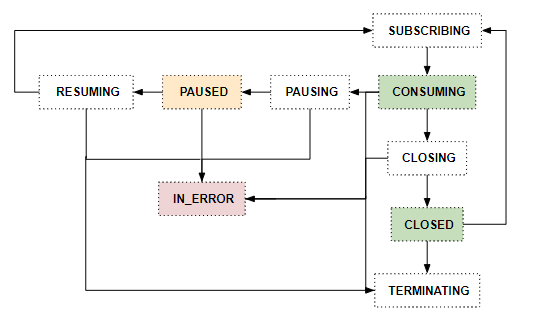
This could be translated to a set of rules in the StateMachine itself to something like:
class StateMachine {
companion object {
private val rules = mapOf(
SUBSCRIBING to Predicate<State> { it == RESUMING || it == CLOSED },
CONSUMING to Predicate<State> { it == SUBSCRIBING },
PAUSING to Predicate<State> { it == CONSUMING },
PAUSED to Predicate<State> { it == PAUSING },
RESUMING to Predicate<State> { it == PAUSED },
CLOSING to Predicate<State> { it == CONSUMING },
CLOSED to Predicate<State> { it == CLOSING },
TERMINATING to Predicate<State> { it == SUBSCRIBING ||
it == CONSUMING || it == PAUSING || it == PAUSED || it == RESUMING || it == CLOSING || it == CLOSED || it == IN_ERROR }
IN_ERROR to Predicate<State> { it == SUBSCRIBING ||
it == CONSUMING || it == PAUSING || it == PAUSED || it == RESUMING || it == CLOSING || it == CLOSED }
) fun transitionRuleFor(state: State) {
return rules[state]||
}
} private val state = AtomicReference(State.CLOSED) fun transitionTo(newState: State){
state.getAndUpdate{
if(transitionRuleFor(newState).test(oldState)) {
newState
} else {
// handle invalid transitions...
}
}
} }
Using the above, the consumer thread’s while loop could be modified as follows:
...
val state = AtomicReference<StateMachine>(StateMachine())
...while (state.get().shouldRun()) {
when(state.get()) {
SUBSCRIBING -> subscribe()
CONSUMING -> processRecords()
PAUSING -> pause()
PAUSED -> doNothing() //well almost, will discuss later
RESUMING -> resume()
CLOSING -> close()
CLOSED -> doNothing() //maybe add delays if right for the app
IN_ERROR - > logAndAlert() // any other error handling and either break or attempt a recovery
}
}// handle successful termination like app TERM on deploy or else
The individual methods called in the when expression should deal with the possible exceptions and the transition to the next state.
That piece of code should live in a class wrapping the actual KafkaConsumer instance and launched as a separate coroutine. It would work equally well for a group with 1 or more consumers.
Approach 3 — use actors.. on top of the StateMachine
Approach 2 is enough if the consumer class only gets notified about events from one other thread or a manager sends notifications to multiple consumer classes with a send and forgets strategy.
However, if either multiple threads can serve as sources of notifications that need to be processed sequentially or the consumers need to send feedback to a manager then we need to roll up the sleeves and use something more sophisticated. Depending on whether we are dealing with the first or the second case we might need to have that implemented just on the manager side or on the consumer one as well.
For this, in addition to the State class, we need to create a hierarchy of message classes that will be sent over the channel. We could have a ControlMessage class used by the manager to control the workflow of the consumer classes and FeedbackMessage class used by the consumer classes to notify the manager that the requested action is done or an error has occurred.
sealed class Message {
sealed class ControlMessage: Message() {
class SubscribeMessage(topics: List<String>): ControlMessage()
object CloseMessage: ControlMessage()
object PauseMessage: ControlMessage()
object ResumeMessage: ControlMessage()
object TerminateMessage: ControlMessage()
}sealed class FeedbackMessage(consumer: Consumer): Message() {
class SubscribedMessage(c: Consumer): FeedbackMessage(c)
class ClosedMessage(c: Consumer): FeedbackMessage(c)
class PausedMessage(c: Consumer): FeedbackMessage(c)
class ConsumingMessage(c: Consumer): FeedbackMessage(c)
class TerminatedMessage(c: Consumer): FeedbackMessage(c)
class InErrorMessage(c: Consumer, e: Exception): FeedbackMessage(c)
}
}
If we need more than one implementation, as mentioned above, it would be nice to have a factory for the creation of the channel.
class ChannelFactory {
fun createChannel(consumer: Consumer<Message>): SendChannel<Message> {
return object: CoroutineScope {
override val coroutineContext = Dispatchers.Unconfined + Job()
val channel = actor<Message> {
for(message in channel) {
consumer.accept(message)
}
}
}.channel
}
}The message processing in the channels will look like this for the consumer class (and analogues for the manager one but with the FeedbackMessage hierarchy).
val consumer = Consumer<Message> { message ->
when (message) {
is SubscribeMessage -> subscribe(message.topics)
is CloseMessage -> close()
is PauseMessage -> pause()
is ResumeMessage -> resume()
is TerminateMessage -> terminate()
}
}val channel = channelFactory.createChannel(consumer)
The tricky bit here is having it all initialized before sending any messages since the consumer classes need to have access to the channel of the manager to send feedback and the other way around — the manager need to have the access to the channels of the consumer classes.
If you paid attention to the scenario we discussed you might already have a few questions. One of which probably is — how do you prevent the consumers from getting kicked out of the group during the long stretches of time with no commits and with that heartbeats sent to Kafka?
There are three kafka consumer configurations that we need to understand before addressing this:
session.timeout.ms— defines the maximum time a broker would wait before considering a client inactive. After, the client gets removed from the group and a rebalance is triggered. The default is 45s but any value should be betweengroup.min.session.timeout.msandgroup.max.session.timeout.ms, which are configurations on the broker side.heartbeat.inteval.ms—defines how often heartbeats are expected to be sent. The default is 3s but any value should be lower thansession.timeout.msand no higher than 1/3 of it.max.poll.interval.ms—defines the maximum delay between the invocations ofpoll(). If no new records are polled after this amount of time the consumer is considered failed and a rebalancing is triggered in order to reassign the partitions to another member in the group. Default is 5 mins. For consumers using a non-nullgroup.instance.idwhen timeout is reached, partitions will not be immediately reassigned, but only after expiration ofsession.timeout.ms. This mirrors the behaviour of a static consumer which has shutdown.
So, essentially heartbeat has to be sent every heartbeat.interval.ms , otherwise after session.timeout.msthe broker considers the client dead and kicks it out, rebalances, and moves on.
With the Java Library, there is a thread handling this for you in the background, but only if you are polling within the max.poll.interval.ms , i.e. as long as the processing is fast and new records are polled often enough, the heartbeat is nothing to worry about at all.
However, the scenario above assumes long-running, complex processing which might exceed the 5 mins timeout.
There are obvious solutions like optimizing the code or increasing the time in the configuration. However, the first might be impossible or not enough and the latter is quite dangerous since it would prevent us from detecting failures quick enough.
Remember that we also said we need to be sure the processing is dsuccessfully done before committing. So, we need another option.
The good news is, we are already halfway there — we have a PAUSED state and/or PauseMessage. The solution is to pause while doing the long-running processing task in a separate thread. While paused, in the consumer thread, keep polling safely (and with that keep sending heartbeats) and no records will actually be returned. Yes, that adds one more thread but it’s worth it.
What we end up with now for our second, state machine approach is:
...
while (state.get().shouldRun()) {
when(state.get()) {
...
CONSUMING -> pollStartThreadToProcessAndSetToPausing()
PAUSING -> pause()
PAUSED -> keepPollingAndVerifyNothingPolled()
...
}
}
...Alternatively, the records can be buffered until the manager pauses to kick off the long-running processing.
...
while (state.get().shouldRun()) {
when(state.get()) {
...
CONSUMING -> pollAndBufferRawOrTransformedRecords()
PAUSING -> pauseAndStartThreadForProcessing()
PAUSED -> keepPollingAndVerifyNothingPolled()
...
}
}
...If we have the actor layer on top of that, the change for it is easy since the heavy load is done by the state machine section and we only needs to notify the consumer class about the state it needs to move to (note that this only applies to the buffering case).
Well, wasn’t this so much fun? Let me know if you tried it and how easy or hard you found it. What issues did you encounter?
Happy coding!

