Automatic Commit Summaries Using OpenAI’s Language Model
Introducing the GPT summarizer — Generate pull request summaries and commit descriptions
Are you looking for ways to make your workflow more efficient, or tired of manually sifting through long commit logs to understand pull requests?
Introducing the GPT summarizer GitHub action: a powerful tool that leverages OpenAI’s latest and greatest large language model to generate concise and informative summaries of the entire pull request, as well as descriptions of the changes to individual files and individual commits.
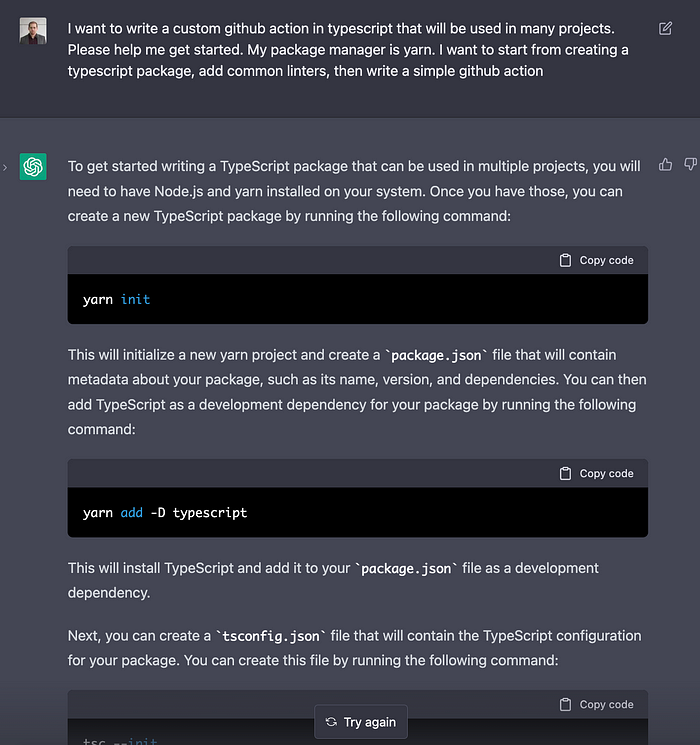
Get it Up and Running in Minutes
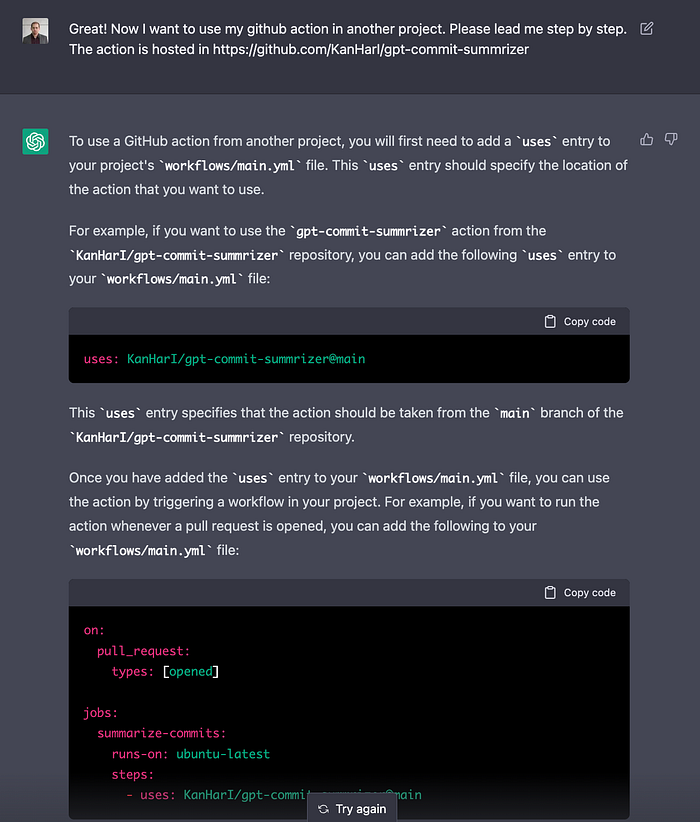
Ready to start using GPT-Commit-Summarizer? Adding the action to your repository is quick and easy — all you need is an OpenAI API token, a secret in your repository, and adding a single file to define the workflow.
Follow the instructions at the Readme, and you can be up and running in minutes. The action supports all programming languages and frameworks - results may vary. Check it out here.
Results on real codebases
All results from real codebases — personal projects, ditto.fit, and connectedpapers.com.



- The PR summary comments serve as a great aid in capturing the main idea of a pull request. These are worded as “PR Summary so far” as they are generated incrementally to avoid cluttering the discussion page with double comments when a commit is added to a pull request.
- The single file diff summaries are generally accurate and provide further assistance during the review process. The GitHub action cleans up after itself, deleting outdated summary comments to prevent spamming the review page.
- If a particular file change confuses you, you can always check the summary of the commit in which it occurred, often finding a useful explanation.
Behind the scenes

In the future, there will come a day when a model will exist that can assess a full pull request in the context of the entire codebase and give a summary. However, today is not that day.
Presently, the text-davinci-003 model (The one powering ChatGPT) utilized in the Summarizer project is restricted to 4096 tokens, roughly two hundred lines of code.
This means that the number of code changes that can be fed into the model is much lower than the number of changes in a typical pull request. Additionally, the model needs to see the code changes in the context of a few lines above and below them to be able to make sense of them, resulting in the input exceeding its limits in any realistic workflow.
To solve this problem, GPT-Commit-Summarizer breaks down the pull request into smaller diffs — of individual file diffs and commits within it. These are then summarized individually. All of these summaries are then combined into a single query to generate a summary of the entire pull request.
A new kind of software engineering
Software engineers will quickly realize this is very similar to the kind of thinking you use when you design a solution to a problem. Breaking down a problem into smaller, manageable parts, understanding the dependencies between tasks, and then getting a unified result.
The similarities to classical software engineering does not end there — take a look at the start of the query for summarizing the git commits:
You are an expert programmer, and you are trying to summarize a git diff.
Reminders about the git diff format:
For every file, there are a few metadata lines, like (for example):
```
diff --git a/lib/index.js b/lib/index.js
index aadf691..bfef603 100644
--- a/lib/index.js
+++ b/lib/index.js
```
This means that `lib/index.js` was modified in this commit. Note that this is only an example.
Then there is a specifier of the lines that were modified.
A line starting with `+` means it was added.
A line that starting with `-` means that line was deleted.
A line that starts with neither `+` nor `-` is code given for context and better understanding.
It is not part of the diff.
[...]
EXAMPLE SUMMARY COMMENTS:
```
* Raised the amount of returned recordings from `10` to `100` [packages/server/recordings_api.ts], [packages/server/constants.ts]
* Fixed a typo in the github action name [.github/workflows/gpt-commit-summarizer.yml]
* Moved the `octokit` initialization to a separate file [src/octokit.ts], [src/index.ts]
* Added an OpenAI API for completions [packages/utils/apis/openai.ts]
* Lowered numeric tolerance for test files
```
Most commits will have less comments than this examples list.
The last comment does not include the file names,
because there were more than two relevant files in the hypothetical commit.
Do not include parts of the example in your summary.
It is given only as an example of appropriate comments.This… Does not feel like writing English. I know this feeling. This is programming.
This new kind of programming, where you write instructions for a language model to generate text, using English as the programming language, is emerging as a powerful tool in the software engineering toolbox.
I have little doubt that “Call large language model” will soon become a common discussion idea in software architecture and planning meetings — for some tasks, specifying them in English and calling an API is all you need.
Writing code with GPT
When I first began writing the GitHub action, I had no prior knowledge of how to write such actions or any familiarity with the OpenAI API.
However, with the help of the model, I was able to quickly and efficiently write many parts of the code, without wasting precious time searching for the correct function in obscure library documentation.
Even for code refactors, the model proved to be an effective tool. All in all, I am certain that utilizing language models will become an essential tool for all software developers, regardless of their field.
The most important tips I learned about being productive with this tool are:
- Provide clear instructions about what you want it to do.
- If your code fails to build or has any errors — tell it, and paste the error message, asking the model to rewrite it. I found that it could usually fix errors and simple bugs.
- Whenever you need to access an API or use a library — ask the model “How can I do X in library Y?” and it will often provide the answer.
- Utilizing a typed language (I used TypeScript) proves to be an incredibly useful tool for this process. The model often fails to produce the correct type signatures. Sometimes this was a minor syntactical issue, but a lot of time it also highlighted real problems — that the model then fixed, when presented with the type error.
- You must already know how to program in order to use this tool. It sometimes makes silly mistakes, and you need to provide guidance when it comes to refactoring code or making changes.
- Use the playground, and not ChatGPT. This allows the following very efficient workflow: Whenever you are not satisfied with the output, identify the first point where the model deviated from your vision, write one or two words (or about a line of code), delete the rest — and let the model continue from there (As you can see from the screenshots, this realization came to me late in the process… And I must admit that ChatGPT is more photogenic).
- Creating small commits and using git proved to be an extremely valuable practice. Occasionally, the model makes mistakes when refactoring code — commit often, and if it does anything wrong, reset to the most recent working commit.
I know I am not the first to say this, but I highly recommend using GPT. Not just for programming tasks, but for a wide variety of activities — I found it to be extremely helpful when writing this blogpost.
Known limitations
For very large PRs, the current solution often still runs over the size limit of the model, resulting in some failed summaries. The action can handle it gracefully — for example if a file diff is very big, it will fail to summarize it, but it can still summarize all other file diffs and all commits taking part in the PR, resulting in an acceptable total PR summary.
Additionally, sometimes (quite rarely in my tests) the model misunderstands something, writing comments that are simply wrong. A bit more common is not writing about some important part of a diff. Therefore, use your judgment and never trust the results blindly.
Thanks to Soof Golan for contributing to the codebase and for writing add-gpt-summarizer.
The author, Itay Knaan-Harpaz is currently the CTO of ditto.fit and a co-founder of connectedpapers.com.

