You're reading for free via Wenqi Glantz's Friend Link. Become a member to access the best of Medium.
Member-only story
Integrating ChatGPT and Whisper APIs Into Spring Boot Microservice
A closer look at the new OpenAI APIs

On March 1, 2023, OpenAI announced that developers can now integrate ChatGPT and Whisper models into their applications and products through OpenAI API. Great news for developers! This announcement opens up a whole new world of innovation by bringing AI into our day-to-day application development.
In this story, let’s take a closer look at the OpenAI API, and integrate two of them, ChatGPT and Whisper API, into a Spring Boot microservice.
OpenAI API
OpenAI is one of the leading providers of tools and APIs for Artificial Intelligence and Machine Learning. It has trained cutting-edge language models that are excellent at understanding and generating text. OpenAI API provides access to these models and can be used to solve virtually any task that involves processing language. It can do tasks including but not limited to the following:
- Content generation
- Summarization
- Classification, categorization, and sentiment analysis
- Data extraction
- Translation
- Transcription
- Image generation
We can interact with the API through HTTP requests from any language. In this story, we will be using Java in a Spring Boot microservice.
Let’s build a Spring Boot microservice to integrate with the chat completion API and the audio transcription via Whisper API.
chatgpt-whisper-spring-boot Microservice
Let’s call our microservice chatgpt-whisper-spring-boot. From https://start.spring.io/, we can quickly stand up a shell for this app. I am adding these dependencies:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
<version>4.0.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>Spring Cloud OpenFeign
For third party REST API integration, there are multiple options to consume APIs. My personal favorite is Feign Reactive. Unfortunately as of this writing, Feign Reactive still has open issue with Spring Boot 3 support. Let’s turn to Spring Cloud OpenFeign instead.
I like OpenFeign’s declarative nature. Let’s get right to it, open your application.yml, and add the following key configuration points:
openai-service:
api-key: #########
gpt-model: gpt-3.5-turbo
audio-model: whisper-1
http-client:
read-timeout: 3000
connect-timeout: 3000
urls:
base-url: https://api.openai.com/v1
chat-url: /chat/completions
create-transcription-url: /audio/transcriptionsapi-key: OpenAI API uses API keys for authentication. Navigate to https://platform.openai.com/account/api-keys to generate your API key if you don’t have one already. Ideally the API key should be stored in a secrets manager tool such as AWS secrets manager, but that’s out of scope for this story.
gpt-model: gpt-3.5-turbo, the most capable GPT-3.5 model and optimized for chat at 1/10th the cost of text-davinci-003, which can do any language task with better quality, longer output, and consistent instruction.
audio-model: whisper-1, a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification from audio files in approximately 100 different languages from around the world.
urls: per OpenAI API documentation, all API URLs start with https://api.openai.com/v1. Let’s define it as base-url. For chat function, chat-url is defined as /chat/completions. For audio transcription, create-transcription-url is defined as /audio/transcriptions.
Be aware, there are two chat completion related API, one is completions, /completions; the other chat completion, /chat/completions. The difference mainly lies in the models they use. /completions uses the flagship model text-davinci-003, which is 10x more expensive than gpt-3.5-turbo model ($0.002 per 1000 tokens), the one used by /chat/completions. Let’s stay with gpt-3.5-turbo model by using /chat/completions.
Feign Client
Now that configuration is complete, let’s move on to write our declarative Feign client, two methods we need: chat and createTranscription, calling their respective OpenAI API endpoint URLs. You can obviously name these methods whatever you want, for simplicity sake, let’s stay with chat and createTranscription.
@FeignClient(
name = "openai-service",
url = "${openai-service.urls.base-url}",
configuration = OpenAIClientConfig.class
)
public interface OpenAIClient {
@PostMapping(value = "${openai-service.urls.chat-url}", headers = {"Content-Type=application/json"})
ChatGPTResponse chat(@RequestBody ChatGPTRequest chatGPTRequest);
@PostMapping(value = "${openai-service.urls.create-transcription-url}", headers = {"Content-Type=multipart/form-data"})
WhisperTranscriptionResponse createTranscription(@ModelAttribute WhisperTranscriptionRequest whisperTranscriptionRequest);
}Models
By closely following the API documentation, we come up with the request/response classes. See below sample request and response classes for chat completions using gpt-3.5-turbo model. Note, request/response for completions using text-davinci-003 is slightly different, refer to API documentation for details.
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class ChatGPTRequest implements Serializable {
private String model;
private List<Message> messages;
}@Data
public class ChatGPTResponse implements Serializable {
private String id;
private String object;
private String model;
private LocalDate created;
private List<Choice> choices;
private Usage usage;
}Sample request/response for audio transcription using Whisper model:
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class TranscriptionRequest implements Serializable {
private MultipartFile file;
}@Data
public class WhisperTranscriptionResponse implements Serializable {
private String text;
}Service
Here is the service layer class OpenAIClientService, constructing the model and call Feign client to trigger the calls to OpenAI API.
@Service
@RequiredArgsConstructor
public class OpenAIClientService {
private final OpenAIClient openAIClient;
private final OpenAIClientConfig openAIClientConfig;
private final static String ROLE_USER = "user";
public ChatGPTResponse chat(ChatRequest chatRequest){
Message message = Message.builder()
.role(ROLE_USER)
.content(chatRequest.getQuestion())
.build();
ChatGPTRequest chatGPTRequest = ChatGPTRequest.builder()
.model(openAIClientConfig.getModel())
.messages(Collections.singletonList(message))
.build();
return openAIClient.chat(chatGPTRequest);
}
public WhisperTranscriptionResponse createTranscription(TranscriptionRequest transcriptionRequest){
WhisperTranscriptionRequest whisperTranscriptionRequest = WhisperTranscriptionRequest.builder()
.model(openAIClientConfig.getAudioModel())
.file(transcriptionRequest.getFile())
.build();
return openAIClient.createTranscription(whisperTranscriptionRequest);
}
}Please note that there are multiple optional parameters we can pass in the request body to instruct OpenAI API in addition to the required parameters. For example, for /chat/completions, we can pass in temperature parameter, which tells OpenAI API what sampling temperature to use, between 0 and 2. Higher values will make the output more random and risky, while lower values will make it more focused and deterministic. The default temperature value is 1 if we don’t specify it. Refer to OpenAI API documentation for all possible parameters we can pass in the request body.
REST Controller
Finally, let’s look at the REST controller OpenAIClientController, two endpoints:
chat(/api/v1/chat): POST call, consumes message in JSON format, takes a question, and outputs response content.createTranscription(/api/v1/transcription): POST call, consumes multipart/form-data as we will be uploading audio file such asm4a, and the API will transcribe the audio file into text.
@RestController
@RequiredArgsConstructor
@RequestMapping(value = "/api/v1")
public class OpenAIClientController {
private final OpenAIClientService openAIClientService;
@PostMapping(value = "/chat", consumes = MediaType.APPLICATION_JSON_VALUE)
public ChatGPTResponse chat(@RequestBody ChatRequest chatRequest){
return openAIClientService.chat(chatRequest);
}
@PostMapping(value = "/transcription", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public WhisperTranscriptionResponse createTranscription(@ModelAttribute TranscriptionRequest transcriptionRequest){
return openAIClientService.createTranscription(transcriptionRequest);
}
}Authentication
OpenAI API calls need to pass in a request header “Authorization” with your API key. Let’s declare a RequestInterceptor bean to handle it, see sample code snippet from OpenAIClientConfig class:
@Bean
public RequestInterceptor apiKeyInterceptor() {
return request -> request.header("Authorization", "Bearer " + apiKey);
}Run the Microservice
Let’s start this microservice by running the following command:
mvn spring-boot:runVerify in Postman
Once our app is up and running, we can now verify in Postman the two new endpoints we just created.
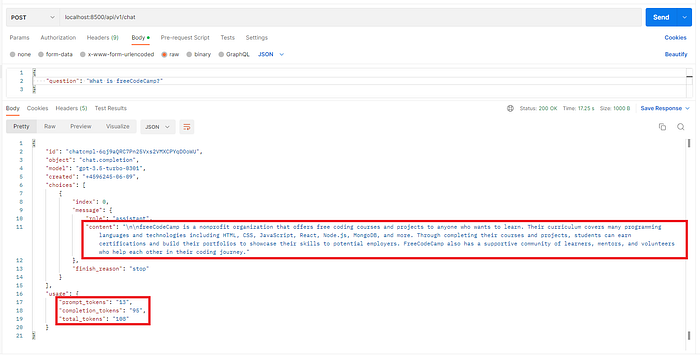
Here is the screenshot for the sample request/response for /chat endpoint:
And here is the request/response for /transcription endpoint:
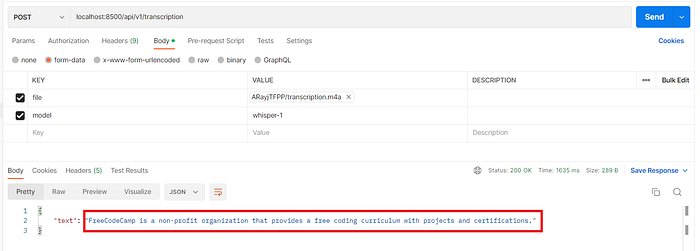
Pretty neat! The Whisper API did a great job transcribing a m4a audio file I recorded on my laptop into English text. I am happy with the result!
Audio Translation with Whisper API
In addition to audio transcription, Whisper API also offers audio translation endpoint /audio/translations. I tested this feature as well. However, I found out that even though it says it can translate audio into English, I recorded a Chinese phrase and called the /audio/translations endpoint in my app, only to find out that the response was still in Chinese. I tested that endpoint in Japanese as well, and it got translated beautifully into English. I have reached out to one of the OpenAI team members on Twitter, and he acknowledged this is indeed a bug and they will look into it.
A Word on Token and Pricing
As mentioned above, gpt-3.5-turbo has been optimized for chat at 1/10th the cost of text-davinci-003. $0.002 per 1000 tokens appears to be pretty affordable. What does a token mean? One token generally corresponds to ~4 characters of text for common English text. This translates to roughly ¾ of a word (so 1000 tokens ~= 750 words).
From my screenshot of request/response from Postman above, you can see that my question “what is freeCodeCamp?” and its answer in the response adds up to 108 tokens. See the “usage” section in the response JSON, it details the prompt_tokens (question) of 13, the completion_tokens (answer) of 95, and the total_tokens of 108.
With audio transcription or translation using Whisper model, file uploads are currently limited to 25 MB and the following input file types are supported: mp3, mp4, mpeg, mpga, m4a, wav, and webm. Whisper model’s pricing is currently set at $0.006 / minute.
When we sign up to experiment with OpenAI API, we get a free credit of $5 that can be used during the first 3 months to try out their API. After the free credit is used up, they offer to pay as you go model. You can navigate to https://platform.openai.com/account/usage to find out the token usage for your account.
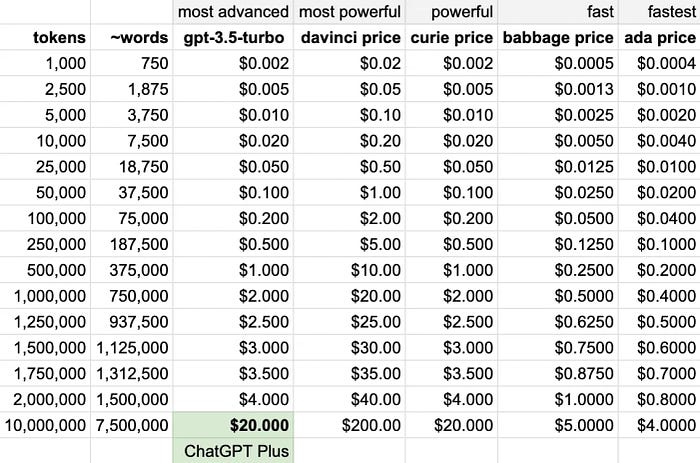
Here is the price comparison among the popular models:
Summary
Like any third party REST API, integrating OpenAI API into Spring Boot microservices is pretty straightforward. We looked into the features OpenAI API brings via the ChatGPT API and Whisper API. It’s exciting that we can now incorporate AI into our Spring Boot microservices, the possibilities are boundless! The most exciting part is that this is merely the beginning! How do you plan to apply AI into your applications?
I hope you find this article helpful. The source code for this article can be found in my GitHub Repository.
Happy coding!