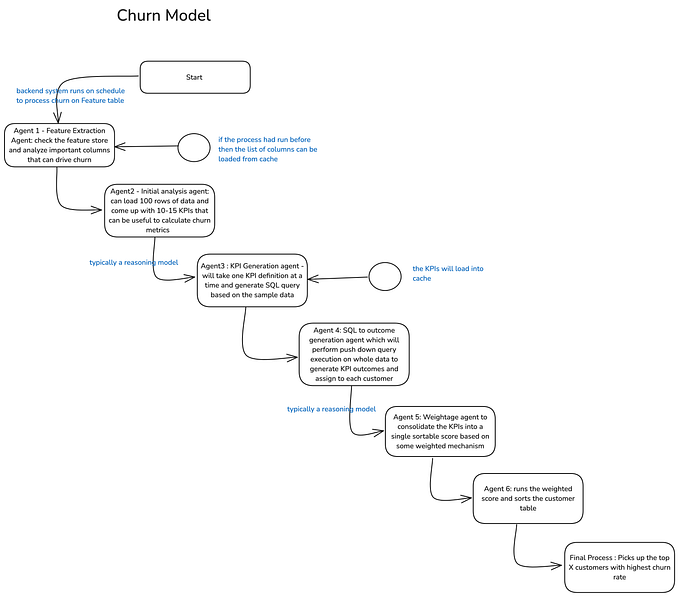
I Made a Browser Extension That Allows ChatGPT to Access External Sites and Get Current Events
Using Tampermonkey and CORS Anywhere for real-time
The code from this article is also available on GitHub.
ChatGPT is everywhere. From Microsoft adding it to the Bing search engine, to marketing companies using it for Super Bowl ads.
But there’s one big limitation facing the new technology: it’s limited to events that occurred before 2021, because that’s the extent of the data used to train the Large Language Model.
What if that wasn’t the case? What if the AI could access external websites, analyze the page for results, and report what it finds?
Well, with a custom little browser extension and a quick lesson, it turns out it can.

How It Works
From a high level, here’s what we’re going to do:
- We’ll add a custom browser extension using Tampermonkey, which is a handy little tool that allows us to include a little section of custom JavaScript on pages we visit.
- The extension will watch for a specific keyword on the website. That keyword will include the URL of where ChatGPT thinks it could find the answer.
- When the plugin sees the keyword, it will take the URL, make a request, and retrieve all the text from that website.
- It will then pass the information back to ChatGPT which can look for the answer within the block of text and tell us what it says.
The Tampermonkey Extension
First, I wrote an extension for Tampermonkey… well, actually, I asked ChatGPT to write it.
I started by asking it to just find the phrase on the page:
I want you to write a short tampermonkey plugin that scans all the text on a website, and finds all matches of the string “::external_request:[any url]::” where the phrase “[any url]” could match any valid website url.
You’ll notice that special requirement: ::external_request:[any url]::
That will be the special command that ChatGPT will send back when it needs help finding a piece of information. I wanted something that won’t naturally come from ChatGPT, so I created that special key format to ensure we get an intentional result from the AI.
I’ll explain how to teach the AI to use it in a moment.
Here’s the first version it came up with:
// ==UserScript==
// @name Find External Requests
// @namespace http://tampermonkey.net/
// @version 1.0
// @description Find all instances of "::external_request:[any url]::" on a page
// @author You
// @match *://*/*
// @grant none
// ==/UserScript==
(function() {
'use strict';
const regex = /::external_request:(.*)::/g;
// Get all text on page
let text = document.body.textContent;
let match;
while ((match = regex.exec(text)) !== null) {
console.log(`Matched: ${match[1]}`);
}
})();Great! It’s matching our special command, and sure enough, the console is filled with logs when I refresh a chat that includes the key phrase.
But we also need it to re-scan every time the page updates. Let’s see what it comes up with if we ask it to add that functionality:
Update this so that it checks again any time the text content on the website changes
And here’s the updated code:
// ==UserScript==
// @name Find External Requests
// @namespace http://tampermonkey.net/
// @version 1.0
// @description Find all instances of "::external_request:[any url]::" on a page and re-run the search any time the text content of the page changes
// @author You
// @match *://*/*
// @grant none
// ==/UserScript==
(function() {
'use strict';
const regex = /::external_request:(.*)::/g;
// Function to run the search
function runSearch() {
// Get all text on page
let text = document.body.textContent;
let match;
while ((match = regex.exec(text)) !== null) {
console.log(`Matched: ${match[1]}`);
}
}
// Run the search initially
runSearch();
// Observe changes to the text content of the page
const observer = new MutationObserver(runSearch);
observer.observe(document.body, {
childList: true,
subtree: true,
characterData: true
});
})();The MutationObserver is something I’ve never encountered, and it’s the perfect solution to this problem.
We’re making progress, but we still have to actually make the requests so that we can retrieve the text for ChatGPT to parse.
Unfortunately, if you just start firing off requests to other domains with fetch you’re going to get CORS errors — it won’t work.
How do we get around this?
CORS Anywhere
Luckily, someone has already solved this problem by creating a Node proxy that allows you to make requests to other sites.
CORS Anywhere will enable the Tampermonkey plugin to make requests to external sites from inside our browser. They do have a public instance of the tool on heroku, but due to rampant abuse, they’ve limited how much you can use it.
For my research purposes, the public instance will work just fine, but there’s also a docker image that allows you to run it locally, which would be a better choice if you’re taking this any farther than the scope of this article.
I asked ChatGPT to include this in the Tampermonkey plugin:
Update the script again so that it will use the URL match to send a request to `https://cors-anywhere.herokuapp.com/[URL]` where [URL] corresponds to the match. Retrieve the contents of that response, parse it, and return the contents of the `body` element into a variable called `body`.
And here is the code it generated:
// ==UserScript==
// @name Find External Requests
// @namespace http://tampermonkey.net/
// @version 1.0
// @description Find all instances of "::external_request:[any url]::" on a page, send a request to "https://cors-anywhere.herokuapp.com/[URL]", retrieve the contents of that response, parse it, and return the contents of the "body" element
// @author You
// @match *://*/*
// @grant none
// ==/UserScript==
(function() {
'use strict';
const regex = /::external_request:(.*)::/g;
const corsAnywhereUrl = "https://cors-anywhere.herokuapp.com/";
// Function to run the search
function runSearch() {
// Get all text on page
let text = document.body.textContent;
let match;
while ((match = regex.exec(text)) !== null) {
const url = match[1];
const fullUrl = corsAnywhereUrl + url;
console.log(`Matched: ${url}`);
// Send request to cors-anywhere
fetch(fullUrl)
.then(response => response.text())
.then(text => {
// Parse response text as HTML
const parser = new DOMParser();
const htmlDoc = parser.parseFromString(text, "text/html");
// Get contents of "body" element
const body = htmlDoc.querySelector("body").innerHTML;
console.log(`Retrieved body: ${body}`);
})
.catch(error => console.error(error));
}
}
// Run the search initially
runSearch();
// Observe changes to the text content of the page
const observer = new MutationObserver(runSearch);
observer.observe(document.body, {
childList: true,
subtree: true,
characterData: true
});
})();At this point, it’s good enough for me to add the rest by hand.
- It still needs to send the request back to ChatGPT. We’ll do this by finding the
textareato add the text to and clicking thebuttonto submit it. - I also don’t want it to fire off requests for the demo prompt, so I’ll exclude that.
- To support more than one occurrence of a request on the page, I slightly modified the regex to make it lazy match the pattern.
- I also capped the length of the body response to 4000 characters to avoid any content length problems from ChatGPT. This is definitely a weakness, and we would have to be smarter about it if we did anything more with this.
Here’s the final version of the Tampermonkey plugin with my edits:
// ==UserScript==
// @name Find External Requests
// @namespace http://tampermonkey.net/
// @version 1.0
// @description Find all instances of "::external_request:[any url]::" on a page, send a request to "https://cors-anywhere.herokuapp.com/[URL]", retrieve the contents of that response, parse it, and return the contents of the "body" element
// @author Seamus James and ChatGPT
// @match *://chat.openai.com/chat*
// @grant none
// ==/UserScript==
(function() {
'use strict';
const requestedUrls = [];
const regex = /::external_request:(.+?)::/g;
const corsAnywhereUrl = "https://cors-anywhere.herokuapp.com/";
// Function to run the search
function runSearch(initializing) {
// Get all text on page
let text = document.body.textContent;
let match;
while ((match = regex.exec(text)) !== null) {
const url = match[1];
const fullUrl = corsAnywhereUrl + url;
if ( ['[URL]', 'http://www.timeanddate.com'].includes(url) ) continue;
if ( requestedUrls.includes(url) ) continue;
requestedUrls.push(url);
if ( initializing ) continue;
console.log(`Matched: ${url}`);
// Send request to cors-anywhere
fetch(fullUrl)
.then(response => response.text())
.then(text => {
// Parse response text as HTML
const parser = new DOMParser();
const htmlDoc = parser.parseFromString(text, "text/html");
// Get contents of "body" element
const body = htmlDoc.body.innerText.slice(0,4000);
const textArea = document.querySelector('textarea');
const button = document.querySelector('textarea + button');
textArea.value=body;
button.click();
})
.catch(error => console.error(error));
}
if ( initializing ) {
console.log("Initialized", requestedUrls);
}
}
// Run the search initially
runSearch(true);
// Observe changes to the text content of the page
const observer = new MutationObserver(() => runSearch(false));
observer.observe(document.body, {
childList: true,
subtree: true,
characterData: true
});
})();How Do We Use It?
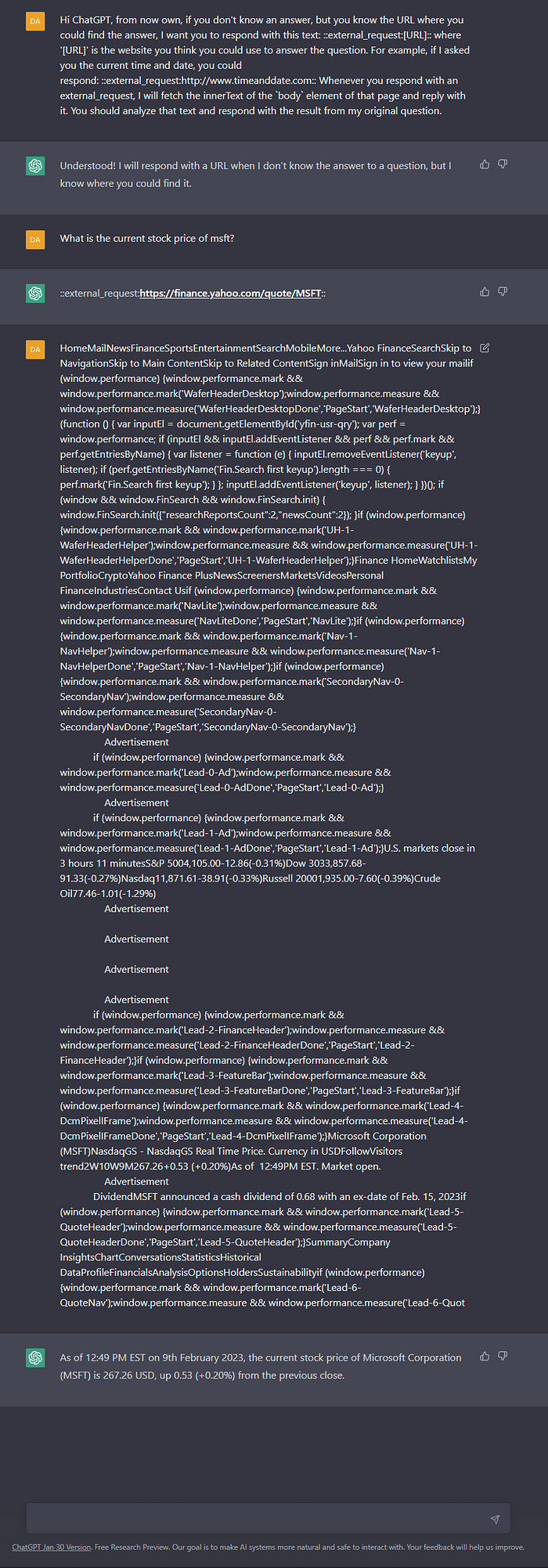
We need ChatGPT to send back that special string when it doesn’t know an answer. We want it to tell us where to look, and then we’ll give it what it’s looking for. Here’s the prompt I’ve come up with to get this result:
Hi ChatGPT, from now own, if you don’t know an answer, but you know the URL where you could find the answer, I want you to respond with this text: ::external_request:[URL]:: where ‘[URL]’ is the website you think you could use to answer the question. For example, if I asked you the current time and date, you could respond: ::external_request:http://www.timeanddate.com:: Whenever you respond with an external_request, I will fetch the innerText of the `body` element of that page and reply with it. You should analyze that text and respond with the result from my original question.
I’m telling the AI how to ask for information that it doesn’t know, and then laying out how that interaction will work. I give it an example to make things super clear (and these example phrases will need to be ignored by our tampermonkey plugin so we don’t make http://www.timeanddate.com requests we don’t need).
It will respond with a message about being ready, and then you can fire off a question about something it shouldn’t be able to answer. Something like:
What is the current stock price of MSFT?
You’ll see your browser automatically send back a huge block of text and voila, ChatGPT will respond with the answer.
Here’s what mine looked like:
Takeaways
While not perfect, this proof of concept shows how this pattern can work:
- Extend the capabilities of a chat AI locally, and create an API to access those capabilities (in our case, the API is simply the
::external_request::command). - Teach the AI how and when to access that API.
- Provide the relevant responses to the AI for further analysis.
If you were to run a local server and point your Tampermonkey extension at it, the potential for this kind of interaction is endless. ChatGPT could conceivably:
- Write scripts that are automatically executed (not too scary if it’s in a docker container)
- Send SMS
- Update a database
- Honestly, just about anything
I’m really impressed by the tool and its ability to make both the creation of something like this possible, as well as the fluid interaction with this kind of API that you get straight out of the box.