How We Built O2: Distributed Search Engine Based on Apache Lucene
A story about the evolution of Ozon marketplace search architecture

In this article, I will talk about the Ozon search architecture. The key part of the story is O2 (oxygen) — the search engine we built on top of Apache Lucene. We used some of the techniques from ElasticSearch and Solr but added a lot of things that make O2 the best match for our workloads. If you ever thought of building a search engine or your work is related to search technologies— then this is the right story to read.
P.S. There is an original article on habr.com, if you don’t mind reading the pre-history from 1998 to 2020. It covers our journey with MSSQL FTS, Sphinx and ElasticSearch. Here I start from 2020 and talk only about O2.
A brief intro on how search typically works
No matter what your product is, the search architecture most likely will have these features:
- Indexing system, responsible for collecting the attributes of the indexed entities (web pages, products, resumes, etc) from different data storage. The outcome is an index, which can be searched efficiently.
- Search backend, responsible for handling queries. It may be just a search engine (like Elasticsearch) that is queried directly from the application backend or it may be a collection of services if your product is big and mature. Search request processing usually consists of query parsing, searching, and ranking.
- Ranking backend, responsible for search results reordering. Again, it may be hidden inside a search engine (like ElasticSearch) or may be built as a top-level service that performs some complex business logic.
The ranking is a very important part of search applications. It may be not a top priority if you run a local food delivery app and your typical search query returns just 5 items. But for some big players like search engines, job boards or e-commerce platforms, ranking the search results is a million-dollar problem.
When your typical query returns 100K results or even more, you have a hard time trying to run complex sorting algorithms under the tight time limit constraints. Bad response time can hurt you even more than bad search relevancy, so be ready for a journey full of challenges and trade-offs.
The typical trick for the ranking problem is to use several ranking formulas. Let’s say your query returned 500K items. First, you pick your most naive but lightweight algorithm and sort all the results you found. Then you pick the best items (as much as you can handle, let’s say 20K) from the first phase and sort them with your next algorithm — which is more clever, but more time-consuming. You can repeat this process as many times as you want, but in practice 2 or 3 sorting algorithms are enough. The last phase is usually a neural network that was trained to solve ranking problems.
That’s all you need to know, for now, let’s move on!
Why do you even need to build your own search engine, man? Just use ElasticSearch and have fun
Ozon had different search architectures during its lifetime. The last one was based on an Elasticsearch cluster with dozens of nodes, shards, replicas and all of the stuff you’d expect from a high load search engine. We were more or less happy with how things were going until we saw the growing backlog of tasks that required modifications in the internal ES parts. These tasks took a lot of time, because you had to write business logic, then patch ES and sometimes even redeploy the cluster.
Eventually, it became clear that we spend more time on infrastructure work than on writing business logic. We also saw some inefficiencies in how ranking, searching, and indexing were implemented, so at some point in time it was clear that we can do better.
We set several goals before the development started:
- Separate searching and ranking phases in order to develop and scale them independently
- Get full control over the ranking process
- Get full control over the index building and index replication
- Get access to low-level optimizations of search algorithms
We basically had two options: to write everything from scratch (the Google/Facebook/Microsoft way) or to use some stable libraries as a foundation. The first option gave us the unlimited potential for customization, but we had to “speed run” over the twenty-year history of the search technologies evolution. The second option tied us to all the specifics and inefficiencies of the libraries we chose but saved us from the mistakes that were already made and fixed by the community. After a short debate, we chose the second option: let’s build a search engine based on Apache Lucene.
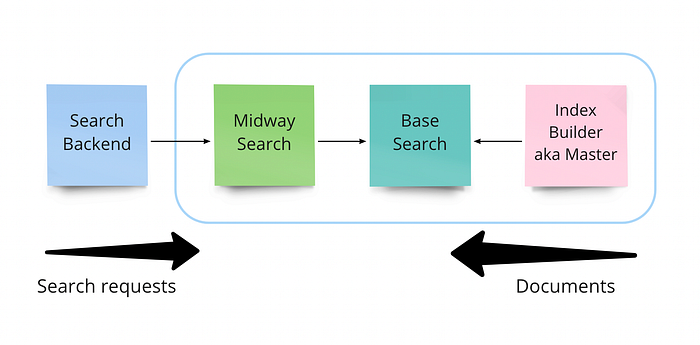
Our search engine consists of three key parts:
- The index builder or “master” is responsible for building the Lucene index. It gets JSON-like documents as an input and releases index segments as an output. Lucene segment is an immutable chunk of index that contains some documents and can be searched.
- “Base search” is a layer responsible for search request execution. Each node of this layer downloads the local copy of a search index on a startup. Besides the searching and filtering phases, base search is responsible for L1 ranking — using the lightweight formula of text relevancy (tf-idf, bm25) and simple heuristics. Base search supports horizontal scaling.
- “Middle search” or “midway” is a layer responsible for request routing and L2 ranking of the search results. We wanted to include the support for index sharding in our design, that’s why we needed a layer above the base search. Midway should be able to route the search requests to shards and to transform the partial responses into a final result. Midway is also a runtime for ML ranking. Same as the base search, it supports horizontal scaling.
The first stable and functional version of O2 was released after 6 months of intensive work. We set up a small cluster with a real search index and routed a copy of 1% of production traffic into it. By doing this we got the ability to estimate the search quality. A few more months were spent improving the text relevancy algorithms using offline testing, fixing all major performance issues, and to implement the high availability.
In July 2021 we gradually transferred our traffic from Elasticsearch to O2. The release was incredibly successful: the response time was cut almost twice and we gained x1.5 throughput at the same time.
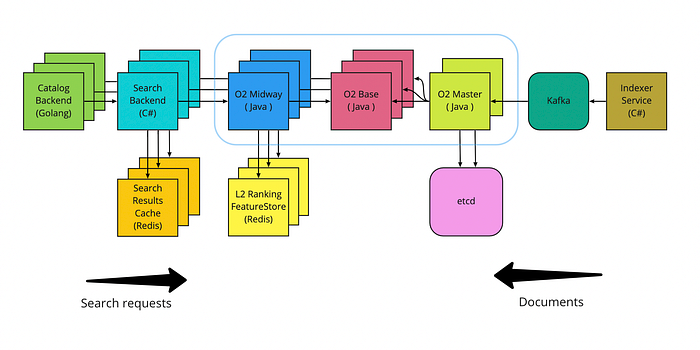
Let’s review the changes since the previous version based on Elasticsearch and talk about why O2 performs better for our workloads.
Load balancing
In a previous architecture, search backends talked to Elasticsearch via Nginx load balancer, which also worked as a caching layer for the search requests. Clients used the domain name, which was resolved to several Nginx IP addresses using the DNS. If the Nginx server failed, we could launch another one and reassign an IP address to it. Everything happened transparently to the clients.
In O2 we switched to the client-side balancing — a technique, where clients keep a list of available IP addresses for every service they communicate with. To implement this, you need a Service Registry, a component that will know which services exist and how they can be reached. At Ozon we have a platform solution for this problem — a service called Warden acts as a Service Registry. Warden is integrated with Kubernetes: it knows the IP addresses for every service in the environment because it listens to all the deployment updates.
Client-side balancing allowed us to remove the Nginx layer and to connect Search Backend and O2-midway directly. This improved the latency and gave us the ability to use features like subsetting and to implement custom load balancing algorithms. For example, now we are testing p2c algorithm based on EWMA response time.
Separation of search phases
Two layers of search, o2-base, and o2-midway, are implemented and deployed as different services.
The lower level, o2-base, is deployed as a Kubernetes StatefulSet — a resource type that allows the linking pod to persistent storage. In our case, it’s a hard drive that stores the search index. Without a StatefulSet, each restart of the pod would cause a new download for a hundred-gigabyte search index. That will either cause extremely long startup delays or a high network utilization, due to a big number of nodes in our cluster.
After the node startup, a noticeable part of the search index is loaded into RAM (operating system page cache). Index read operations are made over mmap, which significantly reduces the overhead of a data transfer between a disk and an application. That’s the prerequisite for low latency of the search requests. Response time in o2-base is mostly dependent on the posting lists traversal, text relevancy scores computation, and data extraction from the DocValues fields. The overview of the common index data structures (like posting lists and doc values) is out of the scope of this article.
The middle layer, o2-midway, is a stateless Kubernetes service. All the search requests pass through this service: first, they are routed to o2-base service to collect the best matching N thousand products and then the result set is reordered using machine learning (L2 ranking). The ML model takes the features of the products as an input. The exact list of ML features is under the NDA, but it won’t be a crime to tell that we use all the common sense product attributes, like price, ratings, or the delivery time. This data needs to be precalculated for each product and stored in fast storage. The search ranking model also requires paired statistics of a product and a search query. After all we have hundreds of millions of key-value pairs, where the key is a product_id or a pair of search queries and a product_id, and the value is a float array with product statistics. We store this data in a Redis Cluster — it is fast and provides sharding and replication out of the box.
As I noted before, independent layers allow you to scale them independently. For example, if we add a new super cool but super heavy ML algorithm, we can just scale the midway layer without touching the base layer.
Eventual consistency
Search engines based on the inverted index usually struggle to provide fast index updates. The minimum part of the index is the Lucene segment, so there is no way to update a single document in place. The only option for an index update is to commit a new index segment containing all new and updated documents (old versions of updated documents will be marked with tombstones and ignored during further searches). Each new segment affects the search latency in a bad way because you have to do more computations.
Lucene segments can be merged using a technique similar to the merge sort. You can use it to reduce the number of segments in the index. If the speed at which you reduce the number of segments by merging them is not less than the speed at which the new segments arrive — then you’ll be fine. Otherwise, you are in trouble because the index will degrade until you build a new one.
In order to keep the latency low, you can perform the index commits less often. To achieve that, the index builder has to accumulate more documents in a new segment before the commit, thus delaying the delivery of this new segment to the base search nodes. This is a trade-off between the latency and the index updates delay. Twitter engineers solved this exact problem in their search engine called EarlyBird (the Lucene fork) by implementing the in-memory search in the not-yet committed segments. Our team will repeat this feat someday.
The nodes of the base search download the search index updates at a different speed. Because of that, they can have a different state at a specific moment in time. You can get different search results for the same query requested twice or you can see some inconsistencies during the pagination.
In practice, our users experience neither of these, because we use caches that make search results more stable. We meaningly avoided the sticky sessions to keep the system simple and resilient.
Performance improvements
Owning the source code gives you the possibility to make the improvements on whatever level you want. The first performance improvement in O2 was the way how segments are processed during the search request execution. Elasticsearch performs a sequential scan over the segments (at least it did that before the version 6.6). We have replaced sequential processing with parallel processing: segments are grouped into chunks and submitted to a thread pool. The grouping is made by a greedy algorithm with a goal to have a similar number of documents in each chunk. This is important because in a parallel processing you wait for the slowest subtask to be finished.
This trick allowed us to trade-off throughput (we spend more resources due to the multi-threading overhead) for latency (the final result can be calculated faster). This trade-off is a good one: throughput loss can be restored just by adding more hardware, but it’s almost impossible to improve the latency with the same trick. Elasticsearch suggests to solve this problem by growing the number of shards and replicas, but that will require more compute resources comparing to the parallel processing inside a single server.
Challenges of the post-release period
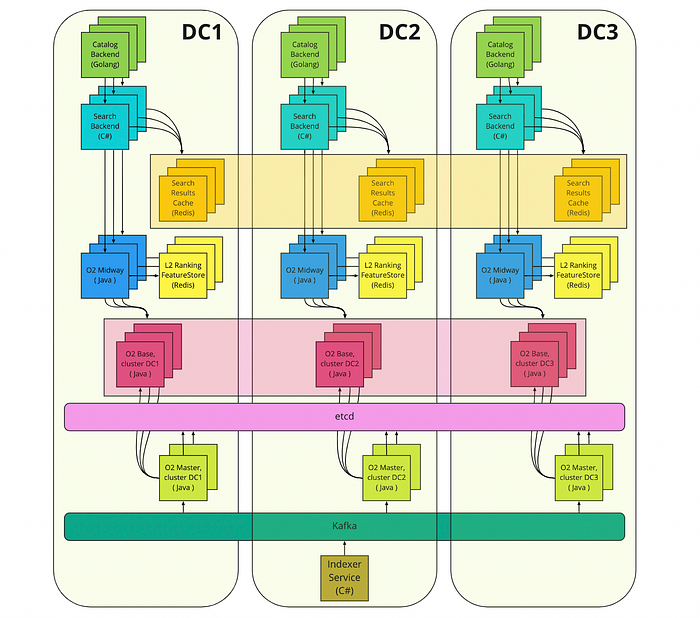
More data centers
At the beginning of 2021, Ozon started to migrate to a Multi DC architecture. Most of the work was done by the platform developers and infrastructure engineers: setting up the new datacenters, adapting basic services (Kafka, etcd, Hadoop, Ceph, PostgreSQL, Redis) and CI/CD.
The easiest part was left for the owners of the stateless services: just set the replica count to a multiple of three and update your service build to the latest CI/CD pipeline version. The search team had a few problems to be solved since the O2 adoption overlapped with the Multi DC migration. We also had a stateful o2-base service which required special treatment.
We decided to run three independent medium-sized O2 clusters instead of a single super big cluster. To be honest, we couldn’t even choose the single cluster option: the first version of O2 had a limit on the number of o2-base nodes connected to o2-master. The bottleneck was the o2-master network channel: it was fully utilized when o2-base nodes downloaded the index. I’ll give more details about that in the next chapter.
Three independent O2 clusters were implemented as different Kubernetes deployments: o2-base-dc1, o2-base-dc2, o2-base-dc3, each one with its own o2-master instance. This configuration created a new problem with traffic routing because for a single o2-midway service we now had three o2-base services. The default platform load-balancing solution did not support this custom scenario, so we had to implement our own solution based on Ribbon. The instance of o2-midway first chose o2-base cluster with a probability proportional to the cluster size and then chose one of the nodes in a cluster (with p2c based algorithms I mentioned before).
Looking ahead, I can say that the three-clusters configuration has fully justified itself. It gives the possibility to pull off the traffic and turn down the single cluster in case of an incident. Also, you can update the clusters independently, one by one, which is a very helpful feature for risky releases.
The Multi DC architecture has these interesting properties:
- Stateless services talk to each other only inside a single data center. This is achieved with the help of the aforementioned Warden service — by default it provides only local IP addresses for the client-side balancing.
- Search result caches are spread among three datacenters without replication. This gives us more storage space. In case of a data center failure, we will lose 1/3 of our cache data which basically means that we will lose 1/3 of our cache hit rate. This is acceptable because our backends have the capacity to sustain the workload even without caches.
- Each data center has its own storage for ML features. We can not afford to loose 1/3 of this data, because it will noticeably affect the search quality. So the only option is the data duplication.
- Load balancing between o2-midway and o2-base services has two steps: first choosing a datacenter, then choosing a server.
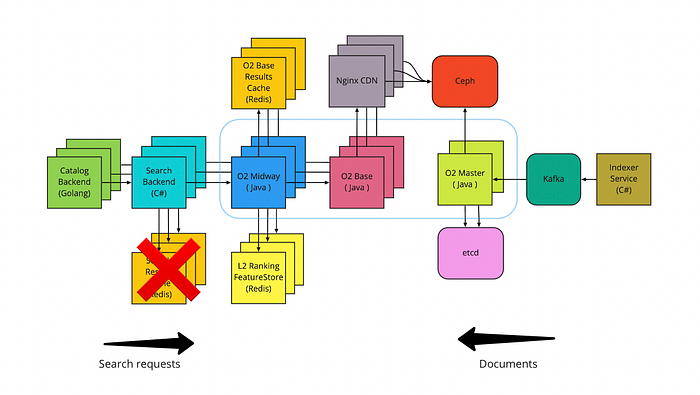
Rescuing the o2-master network bandwidth
In the previous chapter, I mentioned a problem with o2-master network bandwidth: it limited the maximum number of o2-base nodes that can concurrently download new index segments from o2-master without delays. For example, if o2-master spawns a new 10GB segment every 5 minutes, then a 10Gbps channel will be fully utilized by 37 nodes (quick check: you need 8 seconds to download a 10GB segment via the 10Gbps channel, which means you can perform the download (5*60/8)=37.5 times in a 5-minute interval). In practice, the effective speed would be smaller because networks can fail. We decreased the network inefficiency caused by o2-base nodes contention by adding a distributed semaphore between the o2-base nodes and o2-master, but it was clear that this problem needs a fundamental solution.
We had to separate index building and index distribution activities, since the former required a singleton approach and the latter required horizontal scaling. We changed the logic so that o2-master started to upload the indices in S3 storage (we use Ceph) and o2-base nodes started to download indices from S3. This approach had a similar disadvantage and fortunately, we foresaw it: gateways to Ceph (in our case Rados Gateways) would be overloaded. This problem is usually solved with CDNs, so we didn’t have to reinvent the wheel. We set up a layer of Nginx servers between the o2-base nodes and o2-master. Base nodes started to request the index files from the Nginx CDN, which first checked for a local copy, and only if a file was missing, Nginx made a single request for this file to Ceph. The latter is achieved with the proxy cache lock setting that acts as a mutex for a file download. We need 8 Nginx servers to handle traffic from 100 base nodes, which is more or less fine. We wanted to try network card bonding to boost the throughput even further, but NOC engineers decided that it's not worthy to support this solution.

The last thing we optimized in index distribution was the data compression. We implemented on-flight zstd compression (a streaming algorithm that does not require a temporal data copy) in o2-master and on-flight decompression in o2-base, so Ceph now stores only the compressed files. This halved the size of the transmitted data and the transmission time.
Now we work on a p2p index replication since it’s the most efficient way in terms of time and network load.
Personalized Ranking
We invest a lot of time and effort in ML ranking. Migration to O2 gave us a lot of new possibilities for feature engineering and the most important one is the runtime computed features. These are the ML features that can not be precalculated, e.g. the fact that the customer saw the particular product in the past. You can only store the set of the product IDs that customers saw in the past, but not the feature itself — you’ll have to compute it at runtime for the products you need to rank.
One of the first things we started to develop was personalized ranking. You may ask how this thing is even related to the O2 search engine architecture? The answer is — personalized ranking affects your ability to cache the search results. Before, we could cache the search results for the “microwave” query for users in Moscow and reuse these results for further requests. But now things changed. We now use the knowledge that Bob prefers “Toschiba” and Alice prefers “Panasonic” in our ranking. We can not just save the search response for Bob and reuse it for Alice.
We did not want to give up on caching completely, so we decided to move the caching layer under the ranking layer (o2-midway). Now we cache only the raw results from the base search and execute ML ranking for every search response. We made latency a little bit worse for sure, but instead we gained the search quality because of the personalized ranking. I already told you that good ranking is a million-dollar problem, so this trade-off was a great deal!
Further Thoughts
This was a pretty long journey though I focused only on the architecture questions. Working on search covers lots of other interesting topics: product and UX, ML ranking, NLP, suggests and spellchecking. We gather lots of on metrics and run many AB experiments to find growth points. Hope to cover some of these topics in future.

