How We Benefited From Webhooks in a Specific Use Case Scenario
A quick webhook use case to address an architectural issue
Last week, I’ve been facing a challenging scenario that had certain complex implications for the current architecture we have, thus making me work under many restrictions. Here’s my attempt to describe it in a clear manner, and to show how webhooks proved to be suitable to achieve a working solution.
The Problem
There’s a monolithic web app that uses certain entities (business domain entities) to perform business operations on them. This web app is being currently decomposed into microservices, moving from a monolithic architecture into a microservice-oriented one. For that to happen, there are many different microservices that address specific business domains.
There’s a specific use case that requires processing a batch of entities. Processing each entity could take either just a few milliseconds or up to 15 minutes. An entity’s state may be altered after processing it, but each specific entity’s processing results aren’t immediately needed, so processing a batch of entities could be done asynchronously.
By the way, the processing of a certain entity occurs in a specific microservice. To process entity “A,” a request to the microservice using “A” as a parameter should be sent. Consequently, to process a batch of N entities, the microservice should be requested N times.
To better depict the scenario, think of the batch of entities as a result of querying a database, and of the microservice as a specific business domain operation. Some helpful examples are:
- Upgrade the salary of the first 100 employees that have been working in the company for more than 10 years by applying a 5% bonus to their current salary.
- For each product of a given customer, find the products that are the most likely to be related, by comparing their names. Then update the
related_productstable with the matches. - For each user in a social media platform, find other users that may share the same interests using some kind of interest matching algorithm. Then update the
users_suggested_friendstable with the matches. The suggestions may be shown to the user once he’s online again.
First approach: Fire and forget mechanism
Since the microservice (MS) that processes each entity can be made asynchronous, a fire and forget approach seemed to be good at first. Given a batch of entities, the web app should traverse it all and send a request to the MS for each one, without waiting for any response from the MS. That way, the MS would be responsible for asynchronously managing the processing of each entity.

The MS doesn’t have any kind of caching mechanism or temporary storage in which it could store all the incoming entities, delaying their processing. Having said that, each arriving entity triggered a new execution thread in the MS, completely intended to process that specific entity.
As you can imagine, this approach was pretty simple, but it entailed terrible performance issues, experiencing very high CPU and memory usage rates and bottlenecks in the use of resources.
Second approach: synchronous blocking mechanism
By the time we looked at the problem, we thought that the web app was unable to know when a specific entity’s processing had finished, in order to request the MS to process the next one. This following approach tried to propose a solution for that by adopting a totally synchronous approach: each request made to the MS would return an HTTP response once the processing thread finishes.
This pattern involves having the web app wait until the processing of an entity finishes before requesting the next one to be processed. It turns the architecture into a mono-thread one. It reduces CPU, memory, and resource utilization rates to a minimum, and the web app now becomes aware of when the MS has finished processing an entity.

However, I mentioned earlier that an entity’s processing could take 15 minutes or more. It wasn’t definitely a good idea to keep an HTTP connection open for that long.
Third and working approach using a webhook
Having failed with all the previous approaches, we started to think in detail about a new workaround. Here’s a list of the expected non-functional requirements we thought it should cover:
- The web app should send processing requests to the MS, without having to wait for it to finish. The web app should have full control over the requests rate.
- The MS should be able to communicate with the web app when it finishes processing an entity.
- The MS should remain stateless. It shouldn’t save any entities collection.
A colleague suggested using a webhook to asynchronously loop over the entities batch by temporarily passing the control from the web app to the MS itself. We immediately realized what a great idea it was.
A webhook, hook, or callback is a specific endpoint that acts as an entry point to an event listener. It is no more than an endpoint that should be called every time a specific set of conditions have been met or a specific event has been triggered. In this case, the event would be that of “entity X processing finished,” and the hook would be called by the MS.
The web app would store the entities batch (e.g. using a caching mechanism), and it would trigger only the first entity’s processing request. Henceforth, every time the MS calls the webhook, the web app would know that an entity’s processing would have finished. Supposing that the entity’s ID is sent in the hook request, the web app would remove the incoming entity off the batch, and send a processing request for the next one.
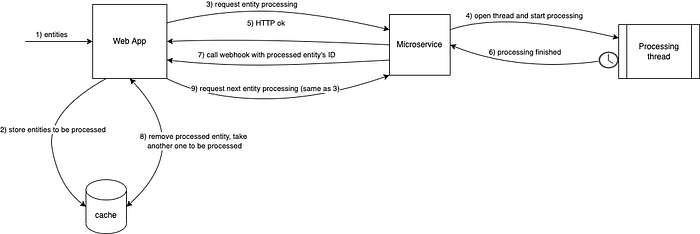
Below are some considerations to have in mind when working with this interesting pattern:
- This pattern guarantees that there’s only one entity being processed at any time, though it can be easily modified to have N simultaneous working threads if we wanted to.
- We started looping through the entities only on the app’s side (only the app had full control over the loop). It didn’t work as we expected, and we ended up using a mixed control approach: now there’s a first moment when the app has full control, and a second one when the MS is responsible for deciding when the loop should continue. It’s a more complex pattern, and the looping decisions involve two distributed components.
- There has to be an entry point to the loop: a moment and a place where the
entitiesbatch is filled and stored in the web app, and when the first processing request is sent. This could be done in an asynchronous process (like a job or a script), or it can be triggered in the main app’s thread. - If the MS fails or doesn’t call the hook properly, then the
entitiesbatch will remain fully on the web app side, and the loop will never finish. Hence, this architecture must consider a fault tolerance or recovering mechanism. - If a new
entities batch is set to be processed when there’s already one being processed, what should happen? Should the new batch override the existing one? Should the new batchentitiesbe added to the already existing ones, so as to mix them all in only one batch? Should it exit logging a message that there was already an entity batch?
Personally, I think this pattern can be very flexible and easy to adapt to more complex similar scenarios with more than two distributed components that depend on each other. I like the way we adapted it to our own needs, and I hope you now have another useful resource in your developer tool case, for scenarios like this.
Thank you for reading and stay connected for more!