How To Apply Advanced Part of Speech Tagging to your ML Models with GPT and Other LLMs
Incorporate advanced part of speech tagging as summarized categoricals with Huggingface and OpenAI’s large language models
Overview
The power of large language models, such as OpenAI’s GPT-4 or Google’s BERT and RoBERTa, has revolutionized the field of natural language processing (NLP) in recent years. These models excel at understanding context, generating human-like text, and performing various NLP tasks with state-of-the-art accuracy.
One of the lesser-understood ways to harness their potential is to incorporate these models’ ability to extract part-of-speech (POS) tags into your machine-learning pipelines. In this blog post, I’ll walk through how to leverage large language models for POS tagging and demonstrate how to include these tags in your machine-learning model as additional features. This approach is likely to both improve your model’s accuracy and improve its interpretability.
Why Part-of-Speech Tagging Matters
Part-of-speech tagging is the process of identifying and categorizing each word in a given text as a specific part of speech, such as nouns, verbs, adjectives, adverbs, etc. This information can be invaluable when building NLP models, as it helps capture the syntactic structure and the relationships between words in a sentence and your outcome of interest.
By incorporating part-of-speech information into your machine-learning pipeline, you can provide your model with richer contextual information and enhance its understanding of the text. This can lead to improved performance, especially in tasks like sentiment analysis, text classification, and entity recognition.
Step 1: Selecting an LLM
Traditional approaches to part-of-speech tagging, such as hidden Markov models (HMMs) and conditional random fields (CRFs), have recently been overshadowed by the emergence of deep learning architectures like recurrent neural networks (RNNs) and, more recently, transformer-based models. These newer architectures have more reliably produced SOTA performance on benchmark datasets.
So let’s start by selecting one of these transformer models that has been fine-tuned for POS extraction tasks. Some of the more popular examples include spaCy, FLAIR, and Twitter-Stanza.
I’m going to work with the TweebankNLP/bertweet-tb2_ewt-pos-tagging model that you can download from Huggingface here. This is a state-of-the-art Twitter POS tagging model that has been trained on EWT training data. The EWT corpus contains about 250,000 words and over 16,000 sentences, taken from five genres of web media: weblogs, newsgroups, emails, reviews, and Yahoo! answers.
Here’s an example of the type of output we can expect:
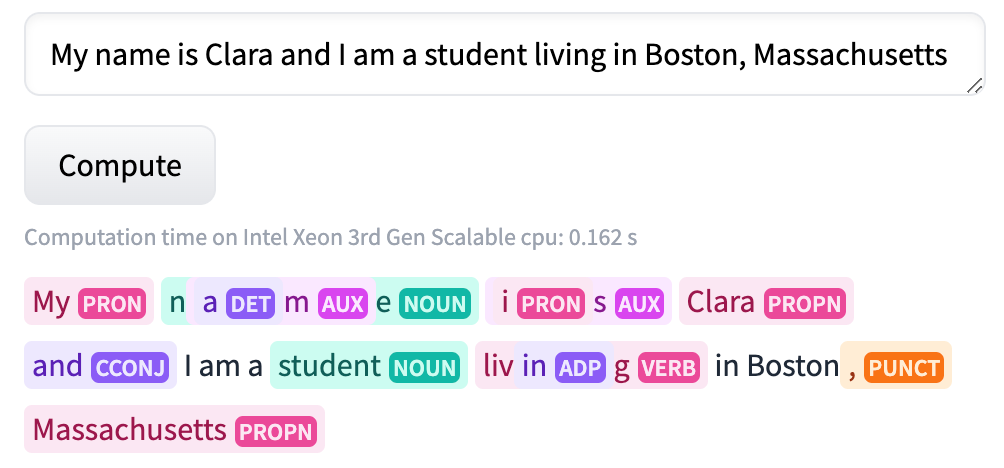
You can see that the model associates each token from our input text with a particular part-of-speech. For example, the word “My” is tagged as a pronoun. Here’s a list of all the parts-of-speech and their abbreviations:

The rest of this article will explain how to supply this syntactic information to your ML models as an additional feature.
Step 2: Tagging parts-of-speech
We decided on which LLM to use, now it’s time to choose a dataset. For our example, I’m going to use Airbnb’s reviews.
Here’s a snapshot of the dataset:
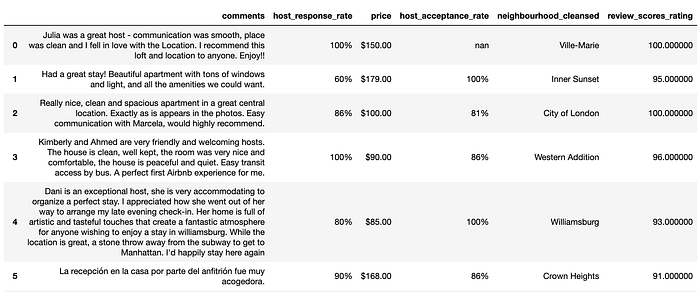
Our target is reviews_scores_rating, which is a score between 0 and 100. We have a handful of numeric, categorical, and free-form text data that we can use as features.
For our POS tagging, we’re just going to focus on the comments field. These are comments that guests left as part of their review after their stays.
We’re going to pass every comment in our dataset through our LLM and output a list of parts-of-speech tags for each token. After we retrieve the tags, we’re going to create a dictionary of counts.
import pandas as pd
import torch
from transformers import AutoTokenizer, AutoModelForTokenClassification, pipeline
import datarobot as dr
import json
name = "TweebankNLP/bertweet-tb2_ewt-pos-tagging"
tokenizer = AutoTokenizer.from_pretrained(name)
model = AutoModelForTokenClassification.from_pretrained(name)
generator = pipeline(model)
filepath = ''
df = pd.read_csv(filepath)
def get_pos(tags):
pos_tags = {}
for tag in tags:
t = tag['entity']
if t in pos_tags.keys():
pos_tags[t] += 1
else:
pos_tags[t] = 1
return json.dumps(pos_tags)
def get_summarized_categorical(text):
tags = generator(text)
summarized_pos = get_pos(tags)
return summarized_pos
df['pos_tokens'] = (
airbnb_sample['comments']
.fillna('Nothing')
.apply(lambda x: get_summarized_categorical(x))
)Here’s what our final output looks like alongside the original comments field appended:

While there are many ways to incorporate these tags into your dataset, this dictionary approach is your best bet for a few reasons.
First, you don’t lose any information. Other techniques, for example, involve replacing the actual word or token with the part-of-speech.
Second, this dictionary format can easily be transformed into a bag-of-words style format where we add a new feature for each unique key and set its value as the count.
Fortunately, the DataRobot ML platform can automatically handle this data type for us. In DataRobot parlance, these dictionaries are called summarized categoricals.
This variable type is used for features that host a collection of categories (for example, the count of a product by category or department). I like to think of it as a dictionary of occurrences. To make this idea more concrete, let’s look at a summary table inside DataRobot:
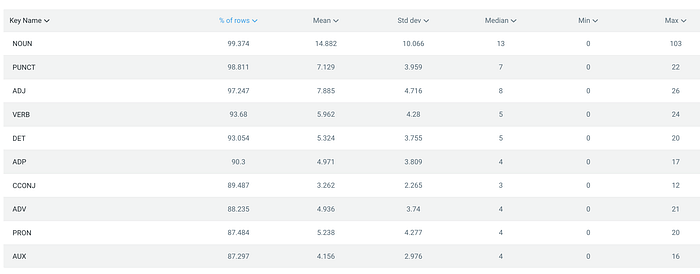
This table shows each unique part-of-speech along with how often they appear in each comment (% of rows) and various other summary statistics such as the mean, standard deviation, median, min, and max.
You can see that nouns appear in nearly every single comment (99.4%), whereas auxiliaries (AUX) only appear in 87% of comments. For those like me who had never heard of an auxiliary, they are a helping elements like will, have, has, had, may, might, can, and could that add meaning to the basic meaning of the main verb in a clause.
This is great high-level information, but what if we double clicked into a particular part-of-speech? Let’s take a look at punctuation (PUNCT):
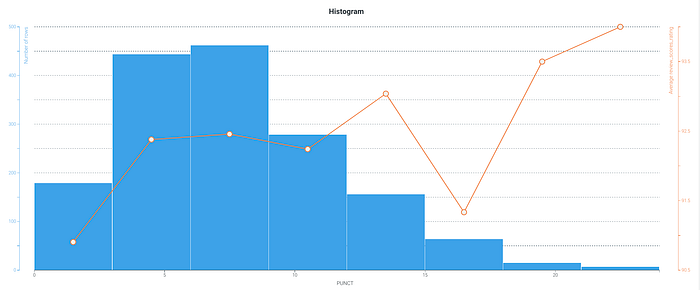
We can now see a histogram of punctuation count (blue bars) with our average review score overlaid (orange line). Interestingly, on average we see that the more punctuation in a comment, the higher our review score.
What if we take a look at adpositions:
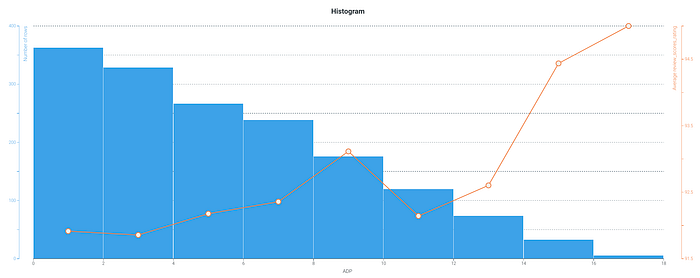
Similarly to punctuation, we can see that as the number of adpositions in a comment increases, our average review score tends to increase as well.
Rather than look into each distinct part-of-speech one at a time, we can look across all of them at once in a word cloud. This visual allows us to see how frequently each part-of-speech occurs in our comment text (depicted by the size of the words) and how correlated the counts are with our Airbnb review scores (depicted by the colors where redder coloring indicates higher correlations and bluer coloring indicates lower correlations).

Looking at the word cloud we can see that more particles and proper nouns tend to increase our predicted Airbnb review scores, whereas more numbers and interjections tend to decrease our predicted scores.
What’s even more interesting is that we can test whether this additional feature improved our model accuracy. Let’s start by taking a look at a feature impact plot:
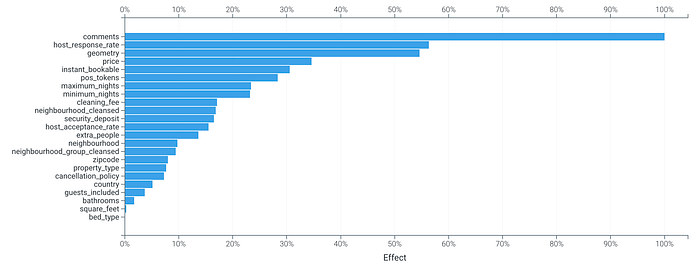
We can see that our new pos_tokens feature has a normalized impact of nearly 30% and is one of the more important features.
We can also compare the RMSE of this model to the RMSE of the same model retrained on a feature list that doesn’t include pos_tokens. In this case, when you exclude pos_tokens, our model accuracy drops by over 5%!
That’s it for this post. Keep an eye out for Part II where I cover advanced named entity recognitino. In the meantime, go here to see the code. Thanks for reading!

