Optimize Your Chatbot’s Conversational Intelligence Using GPT-3
Give your chatbot the power of semantic search with OpenAI

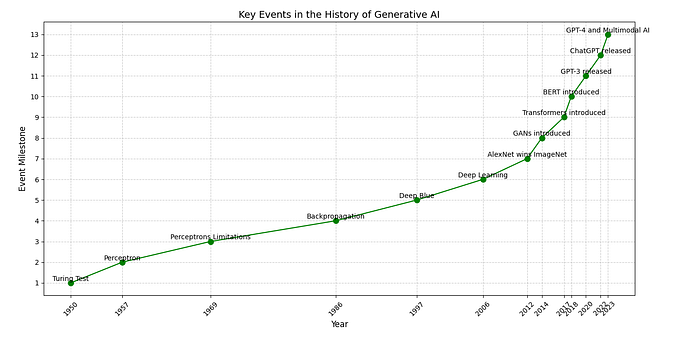
A couple of weeks ago, OpenAI unveiled its latest creation— ChatGPT which has taken the whole world by storm, owing to its robust Natural Language Understanding capabilities and capacity to answer any question or task thrown at it — seamlessly in a conversational manner. The sheer depth and scope of knowledge it seems to possess are astounding, and its continued development is sure to have a significant impact on the future of conversational AI.
However, it’s far from perfect. It has its own limitations and as the authors have pointed out:
- ChatGPT is still susceptible to hallucination and confabulation, sometimes writing plausible-sounding but incorrect or nonsensical answers.
- The model frequently uses excessive verbiage and repetitive phrases, such as constantly reminding the user that it is a language model trained by OpenAI. These problems stem from biases present in the training data.
- Its knowledge base is static, and the latest news and information needs to be updated and retrained, requiring lots of additional computing. Since the model finished training in early 2022, its training data only includes information up until 2021.
So in this article, I’ll show you how to overcome some of these challenges and extend the knowledge base of these GPT models or any chatbot application.
We can achieve that by integrating the chatbot with your domain-specific knowledge base embeddings, using Semantic search.
Acknowledgment
This post would not be possible without the amazing webinar by OpenAI & Pinecone titled — Beyond Semantic Search. Much of the explanatory images and code and are from their public repo, so shout out to Pinecone & OpenAI for freely sharing their helpful knowledge & expertise!
Embeddings? Semantic…what?
I know what you’re thinking but bear with me while I try to simply explain these complex topics. Semantic (or Neural) search is a data-search methodology used in Machine Learning and NLP, widely used in the fields of Recommender Systems and Information Retrieval.
But what are semantics, anyway? Well, it refers to the philosophical study of meaning itself (a topic for another time lol).
It essentially is a technique that allows you to search text with meaning, rather than just keyword matching.
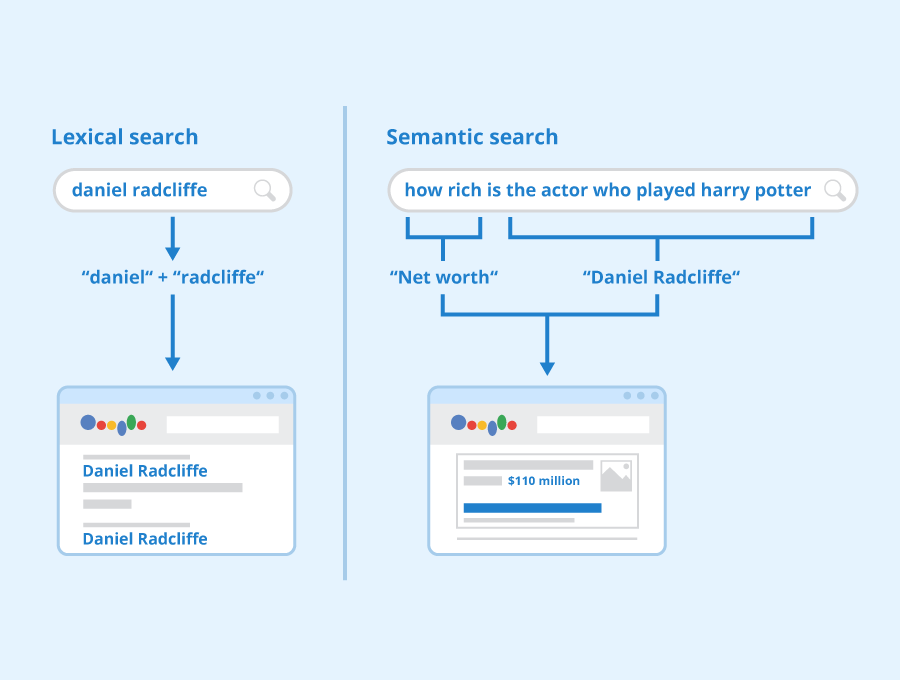
Semantic Search allows a way for computers to understand the meaning and context of words and phrases, in order to provide more accurate and relevant results to a user’s query.
In fact, it lays down the foundation and groundwork for the entirety of the Internet itself. Search engines today are built on semantic search and ever since 2013, Google has been gradually developing into a 100% semantic search engine.
If similarity search is at the heart of the success of a $1.65T company — the world’s fifth most valuable company in the world, there’s a good chance it’s worth learning more about — James Briggs
But how does it work? How can a machine understand ‘meaning’, a concept we humans ourselves have a hard time wrapping our minds around? That’s where embeddings come in!
Embeddings simply put, are representations of text as a list of real-valued numbers, known as vectors. It is a mathematical representation of text in a semantic space, basically, a way to map natural language into numbers that computers can understand. In general, the goal of using embeddings is to create a representation that captures the inherent structure of the data, while also allowing for easy manipulation and analysis by machine learning algorithms.
Embeddings were first introduced to represent words and were called Word Embeddings (word2vec). The technique has since evolved to represent whole sentences, topics, documents, and other units of language.
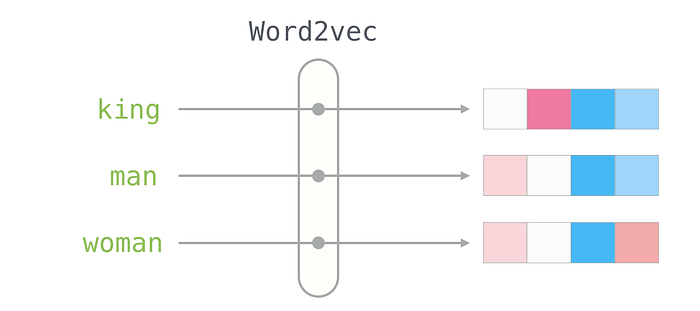
The semantic space is called “semantic” because it captures the meaning of the words or phrases, and it is called a “space” because the vectors are arranged in a multi-dimensional coordinate system, where semantically similar words/phrases are located closer to each other within the Euclidean space.
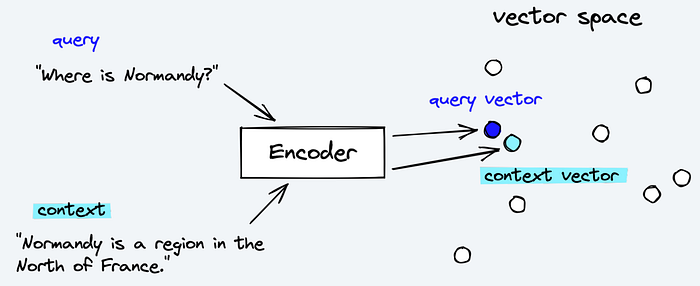
By representing words or phrases as vectors in this space, computers can interestingly perform mathematical operations such as addition and subtraction, to compare and manipulate their meanings. This can enable more accurate and efficient natural language processing, leading to improved performance in various language-based tasks.
To illustrate how computers extract semantic information by doing math on text, we can use the famous ‘King-Queen’ example in NLP:
[king] — [man] + [woman] ~= [queen]
What this means is that, if you subtract the embedding of the word ‘man’ from that of the word ‘king’ and add the embedding of the word ‘woman’ to it, the result will be an embedding that is very similar to the word ‘queen.’ This is possible because the semantic space captures the meanings and relationships between words, allowing mathematical operations to be performed on their embeddings to manipulate and compare their meanings.
Why should you care?
In this era of Artificial Intelligence, integrating semantic search technology into your Chatbot is crucial for providing effective and accurate responses to user inquiries. Semantic search is an incredibly powerful technique that allows computers to understand the meaning and context of spoken or written language, enabling them to provide more relevant and helpful results to user queries.
Moreover, you can use your existing knowledge base as the ground source of truth for your virtual agent. On my projects page, I’ve described how RingCentral’s Chatbot leverages semantic search as its default-fallback intent and the results are outstanding! By incorporating semantic search into your Chatbot, you can improve its performance and make it more user-friendly, helping it better serve the needs of your customers.
I hope this gave an intuitive idea and perspective on what embeddings are and how it’s used in semantic search. Now that we’ve gotten that out of the way, onto building our Intelligent Semantic Search Chatbot!
Getting Started
Apart from Dall-E and GPT-3, did you know OpenAI also provides an Embeddings API? In fact, they just released an updated version of their embeddings endpoint!
Let’s explore it by learning how to leverage semantic search in our Conversational Assistant.
The main objective of this guide is to demonstrate how Embeddings can be used to expand the knowledge of your bot. There are currently 2 main ways to extend your knowledge base to the GPT models:
- Finetuning — which I’ve explained in my previous post. Straight-forward approach, but you possess no control over the model response apart from the initial prompt engineering.
- Embeddings — a better approach to extend the model’s domain-specific knowledge, allowing more flexibility and control over the generated model output.
The Dataset
To demonstrate this, we’ll be creating a helpful Ecommerce Chat Assistant. The first step towards that is to prepare the data that will be used as the bot’s knowledge base.
For this task, I chose the Amazon India Product Dataset by PromptCloud to emulate the domain-specific knowledge base that our agent will draw from. Download the CSV file and upload it to your Google Drive so we can explore the data in our Colab notebook.
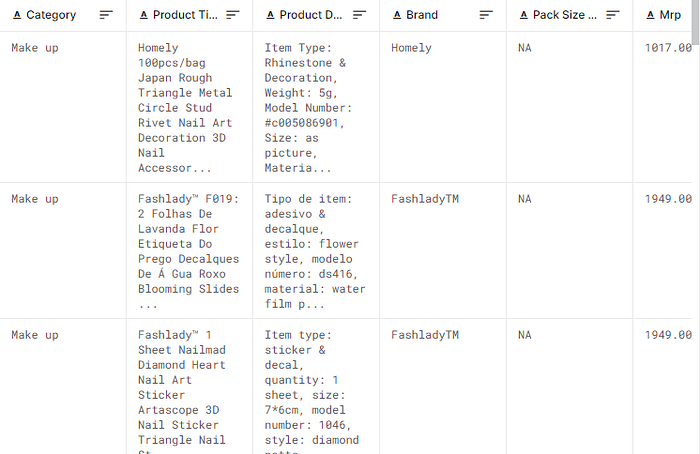
Looking at the data, we see that it has various product columns but we are most interested in Product Title, Product Description, Category, Brand, Price & Availability.
We can use these columns as our text data source to create our embeddings. But before that, we need to concatenate the required columns so that we have all our text in one place, and add it to a new column named “text.”
data['text'] = "Category: " + data.Category + "; Product Title: " + data["Product Title"] + "; Product Description: " + data["Product Description"] + "; Brand: " + data.Brand + "; Price: " + data.Price + "; Stock Availability: " + data["Stock Availibility"]This is the data format that is required for the OpenAI embeddings. Now we can proceed to create them.
Creating the Embeddings
To choose the size of your embeddings, it depends on the specific needs of your use case.
Larger and more sophisticated models that cost more, will be able to generate a semantic space with a higher degree of granularity, allowing for a more precise and nuanced representation of the meanings and relationships between texts.
For this demo, I used the latest ‘ada’ model which has 1536 dimensions for its vector embeddings. We can use the openai Python package to create the embeddings, all you need is your OpenAI API Key.
openai.api_key = "<API_KEY>"
size = 'ada'
from openai.embeddings_utils import get_embedding
data['embeddings'] = data.text.apply(lambda x: get_embedding(x, engine=f'text-embedding-{size}-002'))
data.head()And that's it, we now have our embeddings! Let’s export the dataset including the embeddings and download it as a parquet file. Read more on the benefits of using the parquet file format here.
Choosing a Vector Database
Now that we have our text embeddings, we need to be able to store them before we can make use of them. Enter Vector Databases.
A vector database is a type of database that is optimized for storing and querying vectors. So, how do you choose a vector database?
There are 2 options — use self-hosted open-source vector databases or managed cloud databases. Hackernoon has a great post on navigating the vector database landscape. But they missed out on an important contender — Redis. Yes, Redis has its own vector database offering and you might want to consider it, as your organization is most likely already using Redis.
For this demo, I used Pinecone.io due to its ease of use and ability to quickly get started in a notebook, using just an API key. Head on over to Pinecone to get your free API key, and we can proceed to create and index our vector database.
index_name = 'amzn-semantic-search'
if not index_name in pinecone.list_indexes():
pinecone.create_index(
index_name, dimension=len(df['embeddings'].tolist()[0]),
metric='cosine'
)
index = pinecone.Index(index_name)Note that we are using the ‘cosine-similarity’ as a metric to score similar texts. We can then specify a batch size to upsert our embeddings in batches to our newly created pinecone index.
from tqdm.auto import tqdm
batch_size = 32
for i in tqdm(range(0, len(df), batch_size)):
i_end = min(i+batch_size, len(df))
df_slice = df.iloc[i:i_end]
to_upsert = [
(
row['id'],
row['embeddings'].tolist(),
{
'Category': row['Category'],
'Price': row['Price'],
'Brand': row['Brand'],
'Stock Availibility': row['Stock Availibility'],
'Image Urls': row['Image Urls'],
'n_tokens': row['n_tokens']
}
) for _, row in df_slice.iterrows()
]
index.upsert(vectors=to_upsert)Also note that along with the embeddings, we can include additional metadata in our rows, in order to enable more robust search & filtering. And congrats, you’ve just indexed your first vector database!
We can now use it to search for whatever we want about the dataset. Querying any text to the vector database will return the most semantically similar rows from the embedded dataset. We can then use the search results as the context for our conversational assistant.
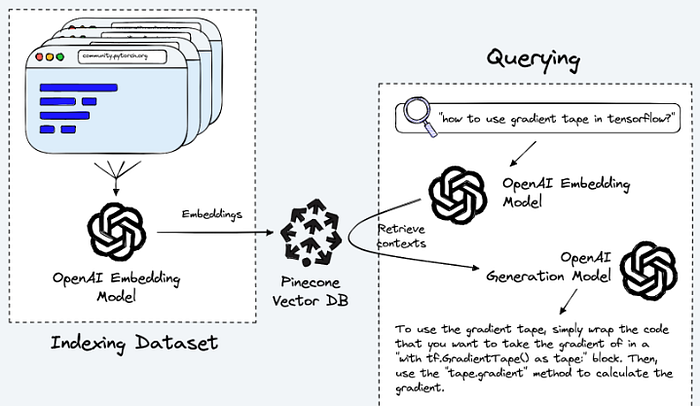
The Eureka Moment!
Generative models like GPT-3 have created a lot of buzz in the AI/ML space, however, their adoption within the Conversational AI domain has still remained relatively limited.
This can be attributed to the skepticism people have towards LLMs and their use in production-ready customer-facing environments, fearing the unpredictable outputs that can be generated by these models.
These concerns are valid, however, the current paradigm of intent-driven development of chatbots is broken. Organizations today simply don’t have the time nor the data to build intelligent chatbots that are actually effective, using intents. The CEO of Botpress posted an insightful article about this subject titled — Will chatbots ever live up to the hype? (The answer is yes)
This isn’t what today’s chatbots deliver. Instead, they are glorified Q&A bots that classify queries and issue a canned response. Recent advances in several areas of AI, however, offer opportunities for producing something better — Sylvain Perron
I’m here to bust the myth and show you how it’s entirely possible to use these large models in a safe way, minimizing as much risk as we can.
The secret lies in the “Context”! Instead of directly using generative models in production, combining them with an embedded knowledge base proves to be the right solution and approach to mitigate the dangers of LLMs.
By defining your existing knowledge base as the ground source of the truth, it is then possible to curate the information the generative model knows as the context, and it will never deviate outside of its provided context! (unless we want it to, of course). We can use the same technique to extend the knowledge of your bot by providing it additional context. This research is by no means new and is called Information Retrieval based Question Answering.
Here’s a sample prompt you can use to ensure that the Conversational Agent only sticks to its provided context. Ask it anything else outside of your knowledge base and it’ll tell you it doesn't have that information—The following is a chat conversation between an AI e-commerce assistant and a user.
Write a paragraph, addressing the user's question and use the context below to obtain relevant information.
If the question absolutely cannot be answered based on the context, say you don't know.
Context: <search results from vector db goes here>
Chat: <chat transcript goes here>
The results:






The results, in my opinion, are fantastic!
It’s not perfect of course, but the Generative model is only provided with the top semantic matches from the user’s query, and it does a great job of making sense of the returned context and coming up with a helpful reply.
You can ask it any product-related info and it will respond appropriately; however asking it questions outside its domain will result in it being unable to answer the request and instead, it will gently try to steer the conversation to its programmed purpose.
Essentially what the GPT Conversational Agent is doing, is instead of directly answering the user’s question itself, our embedded knowledge base acts as an ‘Oracle’ and our model will only use the results from the oracle to generate the output. We basically built a search engine into our chatbot. Pretty cool, huh?
Feel free to play around with the chatbot here — https://amagastyas-amazon-bot.streamlit.app/ and let me know about any interesting/broken responses in the comments below!
Limitations
At its current state, the semantic search framework for chat conversations isn’t perfect and still needs additional research before it can be perfected. Due to the way the contexts are being retrieved, the bot can only carry a conversation about one particular topic at a given time. Asking it a different topic question amidst an ongoing chat, will result in it being confused by the previous context and it will no longer generate accurate results, although it can sound very convincing! The solution I devised is to reset the chat before asking it a new topic question.
The current solution is pretty naive, so if anyone finds a better solution to this challenge, do let me know! The code for the demo application is linked here.
Conclusion
As we have seen, incorporating OpenAI’s neural search or any semantic search technology into your chatbot can vastly improve its ability to find relevant information and provide accurate responses to user queries. Using a knowledge-base as the ground source of information for LLMs ensures safety, as well as gives the bot much-needed knowledge about your domain-specific task. By using pre-trained models or integrating with the OpenAI API, you can leverage the power of machine learning to enhance your chatbot’s search capabilities, as well as overcome some of the existing challenges within Large Language Models.
Implementing neural search technology in your chatbot project is pretty straightforward, and the results can be impressive. So why not give it a try and see how it can improve your chatbot’s performance? You just might be surprised.
Resources and References
- Beyond Semantic Search — https://www.youtube.com/watch?v=HtI9easWtAA
- OpenAI Embeddings — https://openai.com/blog/introducing-text-and-code-embeddings/
- Exploratory Colab Notebook — https://colab.research.google.com/drive/1Vr1JOV57zt5JXQbDwPSfdEk6c4L5Zot6?usp=sharing
- OpenAI & Pinecone integration documentation — https://www.pinecone.io/docs/integrations/openai/
- Pinecone: Semantic search — https://www.pinecone.io/learn/semantic-search/
- The illustrated word2vec by Jay Alammar — https://jalammar.github.io/illustrated-word2vec/
- ML Embeddings crash course — https://developers.google.com/machine-learning/crash-course/embeddings/video-lecture
- Semantic Search: Seobility — https://www.seobility.net/en/wiki/Semantic_Search
- Standford IR-based QA notes — https://web.stanford.edu/~jurafsky/slp3/old_oct19/25.pdf
That’s it from me for now, see you at the next one!
More articles by me —