Building a Layer Two Neural Network From Scratch Using Python
An in-depth tutorial on setting up an AI network
Hello AI fans! I am so excited to share with you how to build a neural network with a hidden layer! Follow along and let’s get started!
Importing Libraries
The only library we need for this tutorial is NumPy.
import numpy as npActivation Function
In the hidden layer, we will use the tanh activation function and in the output layer, I will use the sigmoid function. It is easy to find information on both the sigmoid function and the tanh function graph. I don’t want to bore you with explanations, so I will just implement it.

def sigmoid(x):
return (1 / (1 + np.exp(-x)))Setting Parameters
What are parameters and hyperparameters? Parameters are weights and biases. Hyperparameters effect parameters and are before the learning begins. Setting hyperparameters perfectly correctly at first is not a piece of cake, you’ll need to tinker and tweak your values. The learning rate, number of iterations, and regularization rate, among others, can all be considered as hyperparameters.
Wondering how to set the matrices sizes? The answer just below!

What does all that mean? For example:
(layer 0 so L = 0) number of neurons in input layers = 3
(layer 1 so L = 1) number of neurons in hidden layers = 5
(layer 2 so L = 2) number of neurons in output layers = 1

I hope this all makes sense! Let’s set the parameters:
We define W1, b1, W2, and b2. It doesn’t hurt if you set your biases to zero at first. However, be very careful when initializing weights. Never set the weights to zero at first. Why exactly? Well, if you do, then in Z = Wx + b, Z will always be zero. If you are building a multi-layer neural network, neurons in every layer will behave like there is one neuron. So how do we initialize weights at first? I use he initialization.

# Python implementation
np.random.randn(output_size, hidden_size)*np.sqrt(2/hidden_size)You don’t have to use he initialization, you can also use this:
np.random.randn(output_size, hidden_size)*0.01I’d recommend never setting weights to zero or a big number when initializing parameters.
Forward Propagation
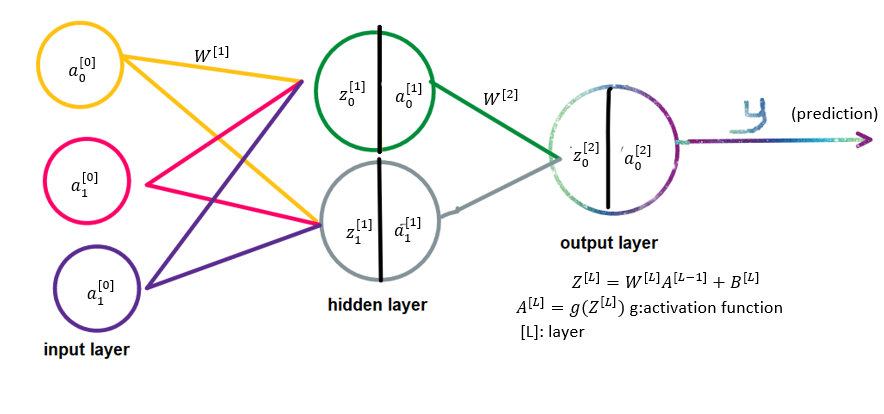
The diagram above should give you a good idea of what forward propagation is. The implementation in Python is:
Why we are storing {‘Z1’: Z1, ‘Z2’: Z2, ‘A1’: A1, ‘y’: y}? Because we will use them when back-propagating.
Cost function
We just looked at forward propagation and obtained a prediction (y). We calculate it using a cost function. The below graph explains:


We update our parameters and find the best parameter that gives us the minimum possible cost. I’m not going to delve into derivatives, but note that on the graph above, if you are on the right sight of the parabola, the derivative (slope) will be positive, so the parameter will decrease and move left approaching the parameter that returns the minimum cost. On the left side, the slope will be negative, so the parameter increases towards the value we want. Let’s look at the cost function we will use:
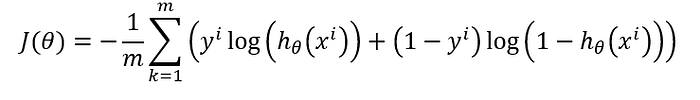
Python code for cost function:
Backpropagation
We’ve found the cost, now let’s go back and find the derivative of our weights and biases. In a future piece, I plan to show you how to derivate them step by step.
What are the params and cache in def backPropagation(X, Y, params, cache)? When we use forward propagation, we store values to use during backpropagation. Params are parameters (weight and biases).
Updating Parameters
Now that we have our derivatives, we can use the equation below:
In that equation, alpha (α) is the learning rate hyperparameter. We need to set it to some value before the learning begins. The term to the right of the learning rate is the derivative. We know alpha and derivatives, let’s update our parameters.
All About Loops
We need to run many interations to find the parameters that return the minimum cost. Let’s loops it!
Hidden_size means the number of neurons in the hidden layer. It looks like a hyperparameter. Because you set it before learning begins! What return params, cost_ tells us. params are the best parameters we found and cost_ is just cost we estimated in every episode.
Let’s Try Our Code!
Use sklearn to create a dataset.
import sklearn.datasets
X, Y = sklearn.datasets.make_moons(n_samples=500, noise=.2)
X, Y = X.T, Y.reshape(1, Y.shape[0])X input, Y actual output.
params, cost_ = fit(X, Y, 0.3, 5, 5000)I set the learning rate to 0.3, the number of neurons in the hidden layer to 5 and the number of iterations to 5000.
Feel free to try with different values.
Let’s draw a graph showing how the cost function changed with every episode:
import matplotlib.pyplot as plt
plt.plot(cost_)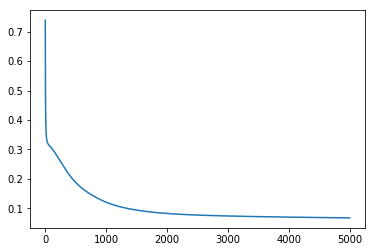
Bingo! We did it!
first_cost = 0.7383781203733911
last_cost = 0.06791109327547613
Full code:
Thank you for reading! I hope this tutorial was helpful!