How to Automate Google Cloud SQL Backups
Using Google Cloud Scheduler, Cloud Functions, Pub/Sub, Cloud Storage, and Cloud IAM
Many — if not most — businesses store an off-site backup of critical client information that can really save them if something goes wrong. Simply backing up data and having an effective backup and disaster recovery plan in place can help mitigate various types of threats.
Cloud providers like Amazon or Google offer automated backup features for AWS RDS and Cloud SQL, respectively.
- Amazon RDS enables an automatic backup retention period that can be configured to up to 35 days.
- Google Cloud SQL retains up to seven automated backups, plus all on-demand backups, for an instance.
Let’s suppose we have the requirement to ensure up to 35 days of backups for Google Cloud SQL instances.
How Can We Achieve This for Google Cloud SQL?
Starting from the fact that Cloud SQL provides a REST API for administering its instances programmatically, we can build our solution on top of that API. As the official Google documentation states:
“The REST API is defined by BackupRuns, Databases, Instances, Flags, Operations, SslCerts, Tiers, and Users resources. Each resource supports methods for accessing and working with it. For example, the Instances resource supports methods such as get, insert, and list. For details of all the resources and their methods, see the Cloud SQL Admin API.”
We can schedule these API calls by using Cloud Scheduler, which will run daily. It will publish an empty message to a Pub/Sub topic and a Cloud Function will receive that message and trigger the Cloud SQL Admin API:
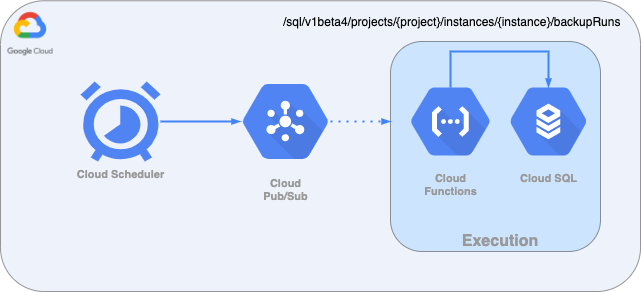
Let’s dive into each of these components.
According to Google’s documentation:
“Cloud Functions can be written in Node.js, Python, Go, and Java, and are executed in language-specific runtimes. The Cloud Functions execution environment varies by our chosen runtime (our solution will use the Node.js 8 Runtime).
In order for Cloud Functions to find the function’s definition, each runtime has structuring requirements for the source code.
For the Node.js runtimes, the function’s source code must be exported from a Node.js module, which Cloud Functions loads using a
require()call. Cloud Functions uses themainfield inpackage.jsonfile to determine which module to load. If themainfield is not specified, Cloud Functions loads the code fromindex.js”
package.json file content:
index.js file content:
The Cloud Function receives data (an empty JSON) from the Pub/Sub topic, decodes the message, and logs it just for debugging purposes.
We’ll notice the presence of two environment variables that are representing the Google Cloud project ID and the Cloud SQL instance name.
One thing that is worth mentioning is the fact that when a request is sent to the Cloud SQL REST API, it must be authorised.
Remember that we want to keep only the 35 days of backup, so we need to delete the older backups. Here, we list the backups (sqlAdmin.backupRuns.list) and delete those that are not eligible (sqlAdmin.backupRuns.delete).
Then we call sqlAdmin.backupRuns.insert in order to create on-demand backups for any instance, whether the instance has automatic backups enabled or not.
Using Terraform to Automate Cloud Function Deployment and Runtime Environment
Here, we have the input variables that our Terraform module will use:
The module definition:
Steps
- The following services need to be enabled for our current project:
services_to_enable = [ "cloudscheduler.googleapis.com", "sqladmin.googleapis.com", "cloudfunctions.googleapis.com" ]2. The Cloud Function has two files in the backup-trigger folder and the following data source generates an archive from its content named backup_trigger.zip:
data "archive_file" "backup_trigger_zip"3. Then the following resource will create the Cloud Storage bucket named cloud-function-bucket:
resource "google_storage_bucket" "cloud_function_bucket"4. It creates a new object and uploads the Cloud Function inside the existing bucket (cloud-function-bucket) in Google Cloud Storage:
resource "google_storage_bucket_object" "backup_trigger_zip"5. This creates a topic (my-database-backup-topic) to which messages are sent by publishers. Our Cloud Function will be triggered each time a message arrives on this topic:
resource "google_pubsub_topic" "function_pub_sub"6. Here comes the interesting part. Cloud Functions will call the Cloud SQL Admin API, and it needs the following permissions:
cloudsql.backupRuns.create
cloudsql.backupRuns.get
cloudsql.backupRuns.list
cloudsql.backupRuns.deleteSo we create an IAM custom role sqlBackupCreator containing all the needed permissions. Cloud Identity and Access Management provide predefined roles that give granular access to specific Google Cloud resources, but they also provide the ability to create customised Cloud IAM roles with one or more permissions and then grant that custom role to users.
We also need to create a service account named backup-trigger-cloud-function-sa and an IAM member with the custom role sqlBackupCreator.
According to Google’s documentation:
“A service account is a special account that can be used by services and applications running on Compute Engine instance to interact with other Google Cloud APIs. Apps can use service account credentials to authorise themselves to a set of APIs and perform actions within the permissions granted to the service account and virtual machine instance.”
This updates the IAM policy to grant a role to the new member:
resource "google_project_iam_member" "backup_trigger"7. This creates the actual Cloud Function that receives two environment variables needed to trigger the backup API:
resource "google_cloudfunctions_function" "backup_trigger_function"8. The last resource will create the Cloud Scheduler, and this will periodically (using crontab format string) push empty messages to the Pub/Sub topic:
resource "google_cloud_scheduler_job" "cloud_function_trigger"The official Google documentation reveals that in order “to use the Cloud Scheduler, the current project must contain an App Engine app that is located in one of the supported regions. If the project does not have an App Engine app, we must create one.”
Wrapping Up
Multi-cloud deployments of databases require considerations such as backups and disaster recovery to protect ourselves from unpredictable events.
On-demand backup is a powerful feature to leverage if we are about to perform a risky operation on our database or when we need to ensure the SLAs for managed backup and disaster recovery services are met.
We also need to be careful with such a feature because on-demand backups are not automatically deleted the way automated backups are. They persist until you delete them or until their instance is deleted. Because they are not automatically deleted, on-demand backups can have a long-term effect on your billing charges if you do not delete them.
Keep on clouding!

