How I Split a Monolith Into Microservices Without Refactoring
My journey to becoming more agile with a just-in-time architectural style

Microservices gained a lot of popularity the last few years and had a lot of impact on my work as a full-stack developer. But in all these years I’ve never lost my faith in monoliths. Microservices bring a lot of additional complexity that in most cases I’ve seen do not outweigh the value they bring. So, I always find myself promoting and defending a monolithic approach. This has resulted in a lot of discussions.
For me, a monolithic and microservice architecture are not that different. When done properly, a monolith consists of modules with strong boundaries. This brings high cohesion and low coupling to the module structure, making the application more maintainable and easier to change. It also enables working with multiple teams on the same application without tripping over each other’s toes. This is an argument I’ve heard many times in favor of microservices.
When designing an application I find it hard to define the right boundaries. No matter if they’re for setting up modules or microservices. There are common decomposition patterns available for microservices that I find just as applicable for a monolith. For most cases a decomposition by business capability is a good starting point. For example, the basic structure for a small online store could look like this.

The idea of a modular monolith is definitely not new, but gains more attention as opposition to microservices. Experts like Sam Newman write a lot on this topic and new technology emerges from these ideas. A good example is the Spring Modulith project for Java applications. For most of the companies I’ve worked for this type of monolith is more than enough.
From my perspective a microservice architecture is just a distributed variant of the monolithic architecture. Distributed systems aren’t simple or cheap, so there must be a very good reason for choosing it. Better application structure, or multi-team support do not count as good arguments for me. What does count are operation related reasons like scalability, reliability and deployability.
Refactoring a modular monolith to microservices should be fairly easy if the module boundaries are strong enough. The modules can be one-by-one refactored independently. After a full refactoring of our small online store the application could look like this.

There are many ways (patterns) to organize a microservice architecture. There is no one-size-fits-all solution, so the right choice always depends on the context. The API gateway pattern as used in the example is great for decoupling the services, addressing security issues and more. It suited me as a great starting point for most cases.
Starting with a monolith and gradually refactoring it to microservices sounds like a great solution, but isn’t very practical in my experience. Refactoring a module into a service still requires a lot of effort. Setting up a new project, end-points, requests, operations, etc.. Once the application train is running, it’s hard to find the resources to put it on another track when customers continuously demand new features. When waiting too long, things start falling apart and the atmosphere turns quickly.
This has set me to think. In the ideal world, a monolith can transition to microservices without any refactoring. Defining what runs where should be a matter of configuration and can change any time. I liked this idea, but how can modules be transformed into services without touching code? At this point in time I was already working on a concept that could help answer this question.
As a full-stack developer I spend a fair amount of time on setting up the communication between frontend and backend which always felt like a lot of overhead. In my article how I speed up full-stack development by not building API’s I wrote about the options for automating the communication between both ends, and how I found a solution in moving the communication from the code to the runtime. With this solution the frontend can import and call backend components directly. The runtime intercepts all backend imports and creates and provides a remote implementation. Like a dependency injector.
Using this solution for the communication between modules solved the automated transition into services. But the runtime was limited to a single frontend and backend segment. So it has been refactored to support an unlimited amount of segments that can be deployed individually or as a group to the frontend or one or more backends. A segment contains one or more components from one or more modules. Its content is defined by configuration. The small online store application can now be set up like this.
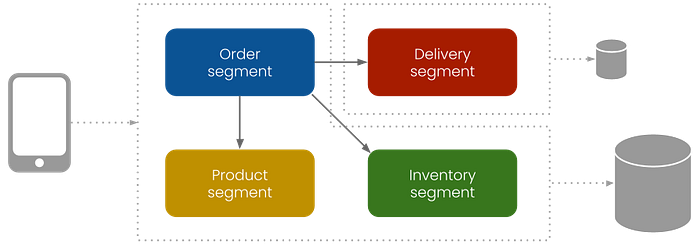
In this example, each module is placed in a separate segment. The delivery segment needs load-balancing (due to the track-and-trace feature) and is deployed to multiple servers. The rest of the segments are grouped and deployed together to a single server.
Alternatively, the modules can be placed into a single segment and moved to separate segments later. Because a segment only lives in configuration, moving a module to another segment has no impact on the code. This way, rearranging an application can be done just-in-time without refactoring.
The runtime has become an open-source project released under the MIT license. It’s named Jitar, which is an abbreviation of Just-In-Time-ArchitectuRe. Due to the full-stack support, it’s implemented as a layer on top of Node.js. So it only suits JavaScript and TypeScript applications. Although I think the same thing can be achieved in Java (and maybe .NET?). More information about Jitar can be found in the documentation and the GitHub repo.
That’s it for now. I know that I’ve skipped a lot of details on how to deal with the data, authorization, etc.. In upcoming articles I want to do a deep dive into them. A big thanks for reading this article and I hope you’ve enjoyed it.
Can you relate to the things I’m saying? I’m always open to feedback and happy to answer any question.

