How Does `ls` Work?
I explored the code behind one of the most useful and “over-engineered” commands in Unix

Why Did I Want To Talk About ls?
I thought exploring a bit of Linux code and how it works internally would be fun. I have felt that my knowledge of operating systems is rather limited, so I thought that diving into the code and trying to understand it would push me to really understand some of the fundamentals, like Kernel, inodes, signals, etc. If you feel the same, continue along!
Quick preface, though, most of the code I may talk about would be written in C. If you don’t know C, that’s fine. You should still be able to understand what’s written as long as you have a basic understanding of concepts like pointers and structs. If you don’t know anything about C or pointers or structs, don’t fret. Continue along, and you should be able to understand most of what I will talk about.
Let’s quickly talk about the code and the directory structure first though. There is a single 5,500+ lines of code file that implements ls , ls.c. The file is part of the GNU coreutils package, which is just the package of common utilities that contains other common utilities like cd, cat, copy, etc.
If you are really inquisitive, here is the source code. If not, then read along to get an abridged version. But before we continue, let’s discuss a few Linux concepts.
Understanding Some Prerequisites
Inodes
Inodes are the metadata about the files. They essentially tell the operating system about the owner of the file, the groupID of the owner, the permissions the file has, the file size, where the file is stored on disk, etc. Most of the output of the ls command comes from inode information!
They are completely independent of the filename, however. So you can rename a file, and it would still have the same inode.
We can use the ls command with the -i option to see the inode number of the file.

We’d talk a bit more about inodes but for now, know that Linux creates these metadata objects that store data about the file, where the file’s data is stored in disk, and that they are uniquely identifiable by an inode number.
Different file types
If you don’t already know, every file has a certain type in Linux. That’s actually what the first bit represents when you run ls -l.
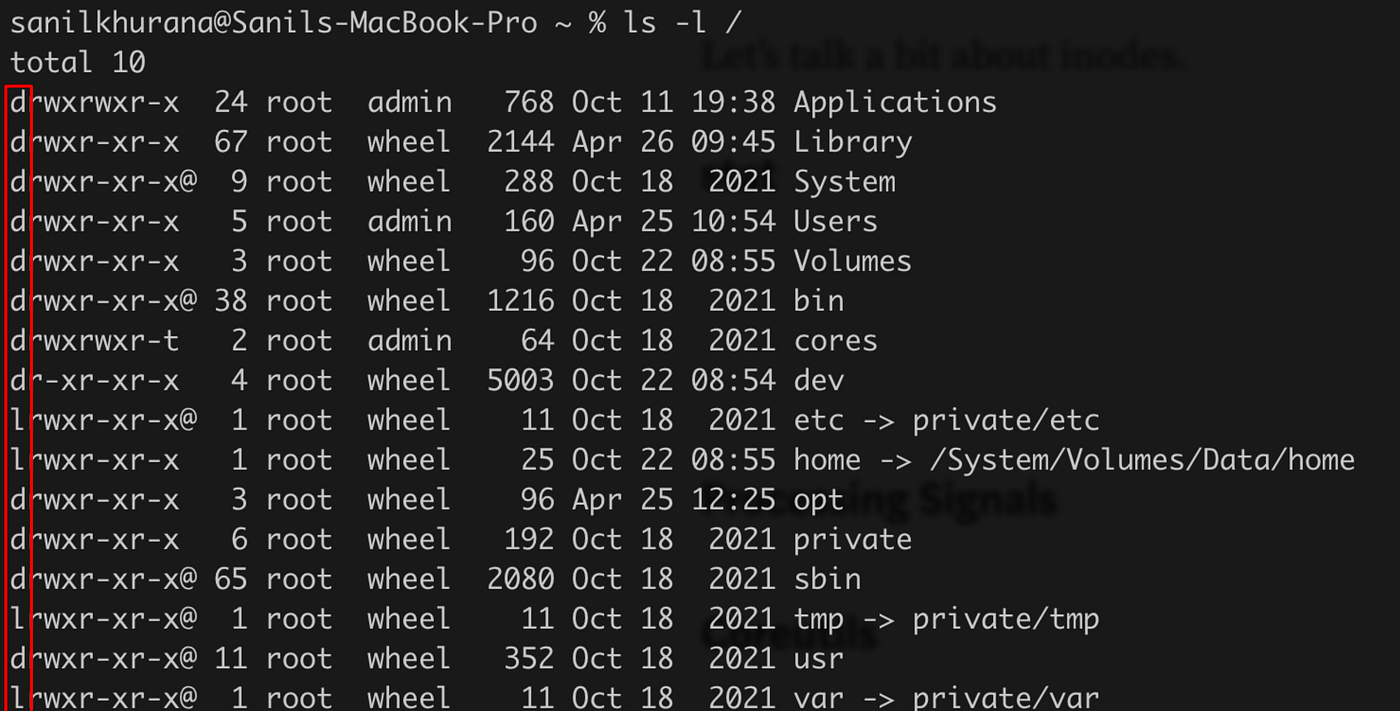
As you may have guessed already, d means directory.
For a regular file like ls, the bit is unset.

Apart from that, there are links, which use the l letter, character special files that use the c letter, and quite a few more file types. I won’t get into all of them right now, but I know that there are quite a few types.
Kernel
I think we all have, at one point or another, read or heard the word “Kernel” in either our education or our career. And I personally have always heard popular yet vague descriptions for it, like “interface between hardware and software.” We have also probably seen diagrams like these:

I believe these are very broad ideas, and at least to me, this didn’t describe the kernel and left more questions in my mind than answers, why do we need the kernel? Can applications directly interact with the hardware? What does the kernel do? What kind of interface does it provide? How much access does it have over memory, CPU, or other pieces of hardware? Are there other layers in between?
So, I spent some time trying to understand the Kernel and what it really is. Here is my shot at explaining it.
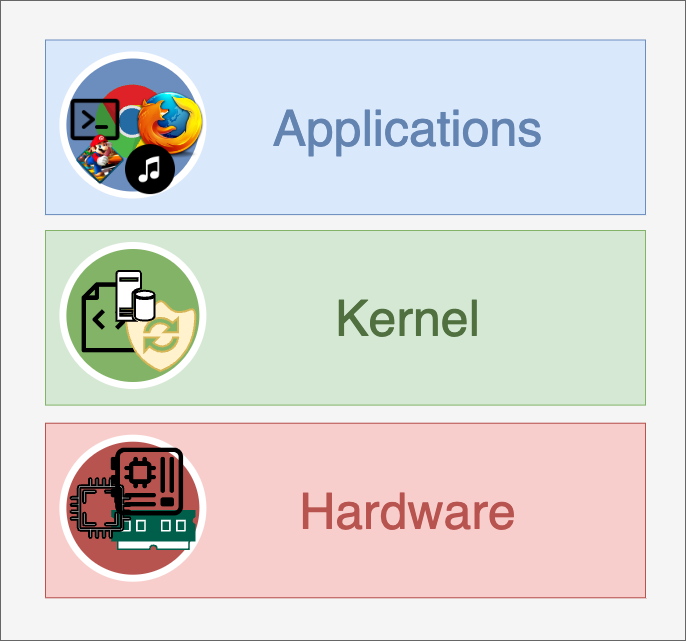
Think of operating systems as three layers. On the top, you have user processes. These are web browsers, applications, your web server, etc.
Underneath this is the Kernel. This contains a lot of code for interactions directly with the hardware, like device drivers, memory management, permissions, etc. So when you execute a command without sudo that requires sudo, and the response says that you can’t do that, that’s the Kernel. Though most of its details are usually hidden from us software engineers.

And below the kernel is the hardware. This is the physical memory, the disk, the CPU, the NIC, etc., in your system.
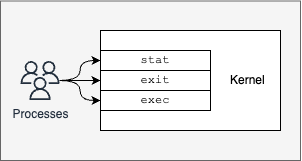
The processes can make system calls to the kernel for operations that involve the hardware.
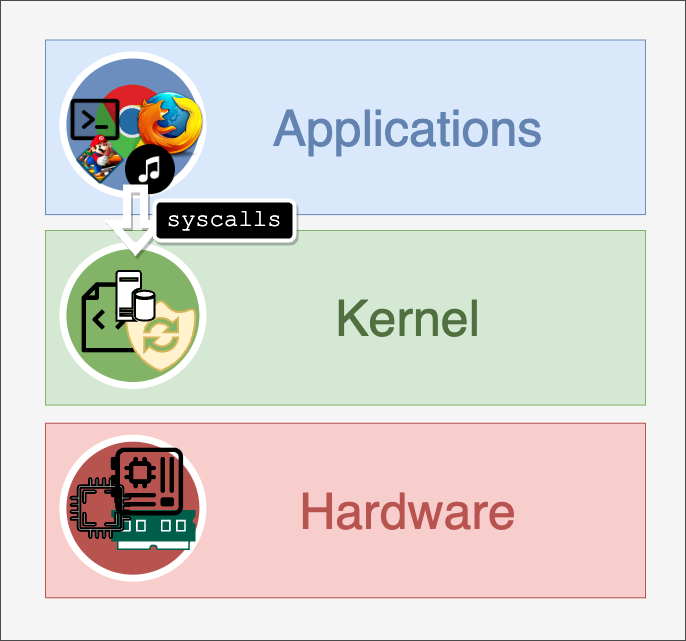
For example, a process must read a file on the disk and make a system call to the kernel. The kernel gets the information about the process, for example, which user executed the process, which user created the executable, etc., and decides what to do.
If it feels that everything is in order, it creates a file descriptor and returns it to the process.
Some of you may say you have never written any code that makes system calls. And that is normal. Most modern programming languages build an interface on top of the kernel to make it easier to do most operations. This layer of abstraction does a lot of work, like error handling, logging, managing file descriptors, managing memory(there is no automatic garbage collection at this level!), etc. For example, this is the source of Python’s open function.
It is possible to bypass the kernel and let the processes talk directly to the hardware, though it’s not generally straightforward or even required for most. I found a few examples of people bypassing the Kernel, but these seemed like really niche use cases.
For example, this post from Cloudflare talks about how they bypassed the Kernel to achieve higher network performance.
BIOS, another popular word we hear, is something that directly interacts with the hardware. BIOS, on the other hand, comes as a part of your motherboard, and its functions are pretty limited. It provides basic input and output to the motherboard and helps in the booting process. Applications wouldn’t interact with the BIOS at all.
I found this talk by Steven Rostedt (who is one of the developers of the Linux kernel) really helpful in understanding these concepts. And I think this diagram from the talk sums it up well:

I’d recommend you check out the talk if you want to dive deeper into this.
System calls
System calls are the interface to the Linux Kernel. Just like our services expose a REST API interface to our users
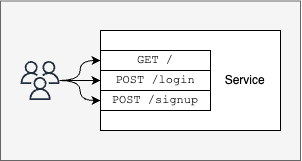
System calls provide an interface to the Linux Kernel.
To learn a bit more about these system calls, let’s write a bit of code! The first question you may ask here is, which language to choose?
The answer is a bit complex, but let’s understand how to do it in C first, and then let’s spend some time thinking about how to perform the same operations in other languages.
For now, let’s experiment with the stat syscall. The call is pretty simple. It takes in a file path and returns a bunch of information about the file. For now, we’ll print a couple of the values returned, i.e., the file's owner and the file's size in bytes.
The output is pretty predictable, as you can see below:
uid = 765
filesize = 11Coming back to our discussion on languages, can we write the same program in Python or NodeJS?
These languages are internally calling the same system calls because you can only use these system calls to interact with the hardware. For example, looking at some pieces of NodeJS code here, you can see how it’s starting the file path. They do quite a bit more work around these system calls to provide an easier interface for developers, but under the hood, they are making the same system calls that the Kernel provides.
Coreutils
GNU coreutils is a common utility package installed in every Linux distro. These provide commands like cat, ls, copy, etc.
Internally these commands make multiple system calls to the Linux kernel along with a lot of formatting, colors, error handling, etc.
What are directories?
Like pretty much everything else in Linux, directories are also files.
But unlike regular files, directories are linked to the files they contain. How that data is stored is abstracted away from us in the Kernel (next post about exploring the source code of the Linux Kernel?!), but we don’t care about how they store this information. We only care about how to retrieve this information.
For that, we have the system call readdir. readdir allows us to read the files in a directory. It’s actually pretty simple, we call readdir, and on every call, it returns us a bunch of information about a single file in the directory. We need to keep calling it in a loop until it returns NULL, at which point it has gone through all the files in the directory.
Let’s go through some simple code to see how it works:
And here’s the output:
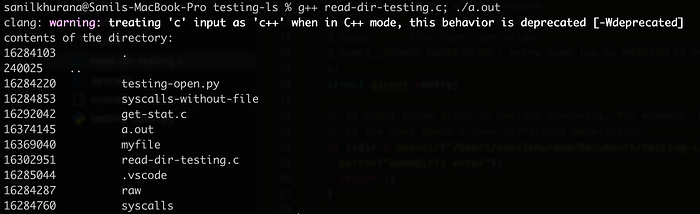
So directories are simply data about the files they store.
stat
stat is a common system call used to get inode information about a file. It returns a lot of information, and let’s go through it one by one to understand how files are represented in Linux.
This is all the data that is returned by the stat system call.
dev_t st_dev;
mode_t st_mode;
nlink_t st_nlink;
uid_t st_uid;
gid_t st_gid;
dev_t st_rdev;
off_t st_size;
blkcnt_t st_blocks;
blksize_t st_blksize;You can use the -x flag in the stat command to see the verbose output.
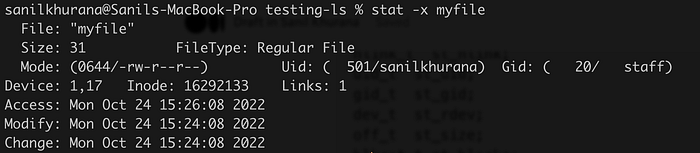
Again, just a reminder, the stat command is not the same as the stat syscall. The stat command is a helpful wrapper written in C(and packaged in GNU coreutils as a command) that calls the stat system call. So this command doesn’t show us the entire output of the stat system call. I wrote some simple code in C to do the stat system call and print its output.
This is the output I got:
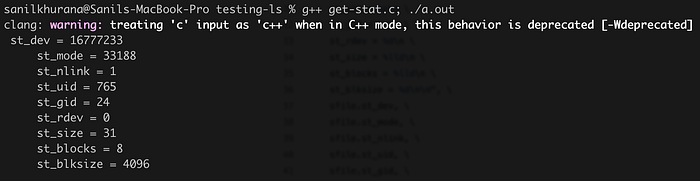
I know this is a lot, but don’t worry, most of this isn’t important. Some fields like st_id(short for user ID), st_guid(short for Group ID), st_size(the file size in bytes) should be pretty obvious already. I just wanted to present an example of how easy it is to make system calls.
Going Through the Code Flow
The code is long. It is 5,500+ lines, and it’s not pretty.
Needless to say, it is impossible to try to cover all of it, so I tried my best to chart the general flow and push all complexities under the blanket.
If you want to actually spend the time to understand the whole code for ls, the only way to do it would be, in my opinion, checking out the code.
If you want the abridged version, check out the flow chart I drew below.
Full disclaimer for those who go through this — this is an extreme oversimplification, but this image should give you a rough idea of how everything works.
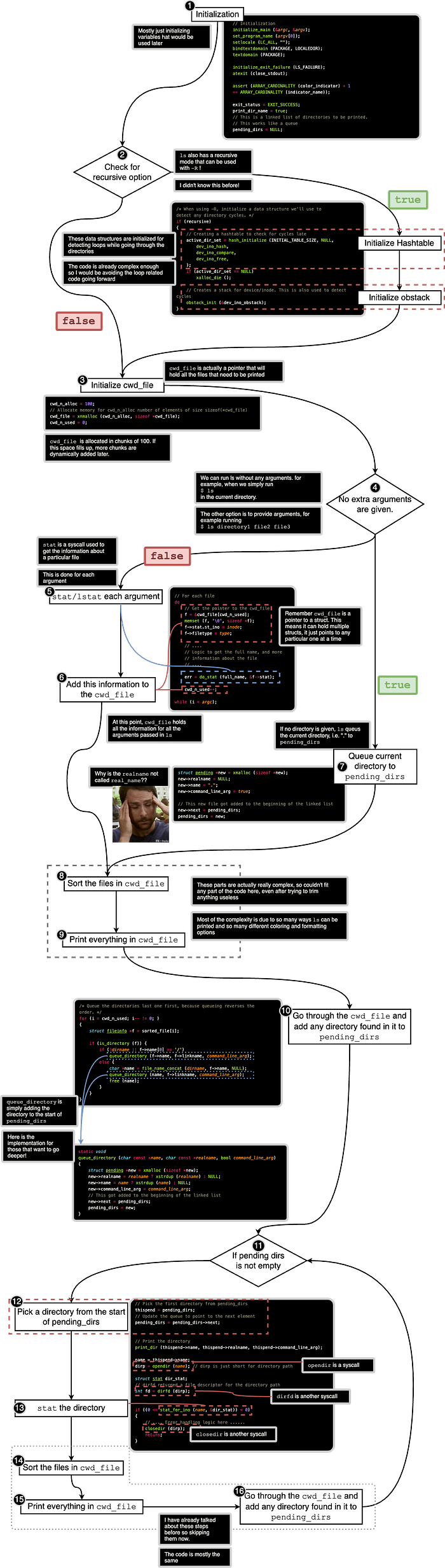
Conclusion
Some of you may have noticed that the article is mostly about understanding Linux and not about ls, and that’s how my learning went. In fact, that was my objective from the start!
Linux and operating systems, in general, are vast. It’s difficult (and boring) to cover them in-depth by reading books and watching lectures without finding an interesting part to explore. So, I picked something that felt really interesting and challenging and followed it to wherever it led me, knowing I’d learn a lot about Linux before I understood ls.
Sidenotes
Overengineered
Before finishing this article, I wanted to show a quote I found on a popular GNU project:
The
lscommand is the most complex (read: over-engineered) utility in coreutils. Rich features, such as format control, color support, pattern filtering, and sorting intertwine with signal handlers, hash tables, obstacks, interface modes, caching, and access control to deliver a versatile tool.— http://www.maizure.org/projects/decoded-gnu-coreutils/ls.html
I really liked this quote because I read this while I was knee-deep in the ls.c source code. If I haven’t mentioned already, it is 5,500+ lines long! And a lot of it is about colors, formatting, filtering, etc. It was nice finding out that I wasn’t the only one who thought the code was a bit long!
Holes in your files?
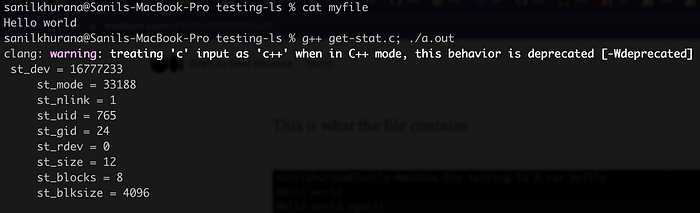
Let’s talk about the C program I wrote to print the stat output. This is the output I got when I ran it:
This is what the file contained:

But there is something weird in the screenshots I attached above. Try to see if you can find the inconsistency.
If you haven’t found it yet, let’s do a small experiment. I’d change the contents of the file, and I’d run my code again.
Running du -h with the old content and the new content also reveals something interesting:
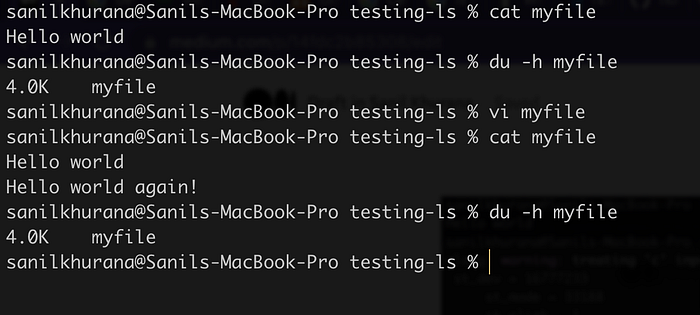
If you haven’t figured it out yet, the file size doesn’t seem to change when running du. Also, the stat command shows a different value for st_size but the value for st_blocks remain the same! st_blocks shows the block count to always remain as 8, which comes out to be 4096 bytes (block size in Linux is always 512 due to historical reasons regardless of the value of st_blksize), so it seems like the bytes the file occupies don’t change!
Why is this happening, though?
Let’s quickly go through what’s happening here. When you want to store data on a hard or solid-state drive, you store data on a “block.” A block is the smallest unit of data storage in the file system. It is essentially an abstraction built on top of the physical hardware. The operating system is essentially reading or writing blocks when it wants to write or read data. So when you want to read a file, the OS finds the blocks where the file exists and picks up the blocks one by one.
File systems like ext4 cannot store multiple files in a single block. But a single file may be stored in multiple blocks. This means that if you create a file with just one character, it still occupies one block. For my system, the block size is 4096 bytes or 4KB. This file always occupies 4KB of space in the disk. Any file I create, even if it contains a single character, would always occupies at least one block. This block is reserved and cannot be used for any other files, hence even the file that contains a single character would still take up 4KB of space on the disk.
This was a fun little side track I got into while exploring something else, but it was interesting and new to me, so I thought I might as well add it here.

