A Visual Guide to Grep
Mastering The Universal Search Tool
The command line is unusually rich and productive.
Its philosophy can’t be explained in a single sentence — It has to be experienced. But at the core is the idea that its power comes more from the interaction between programs than from the programs themselves.
One of the most iconic programs in Unix-like systems is grep. It lets you search for patterns in text, making it a universal tool for many tasks. If you want to master the command line, learning grep is a great start.
Grep is a “filter” program
The most important of the standard Unix programs are the “filters.” They read some input, perform a simple transformation on it, and write some output. They are designed to easily chain together in pipelines (|).

grep stands out as the most versatile of them — Between the simple filters (tail, tr, wc and sort), and the powerful but complex sed and awk.
A quick example
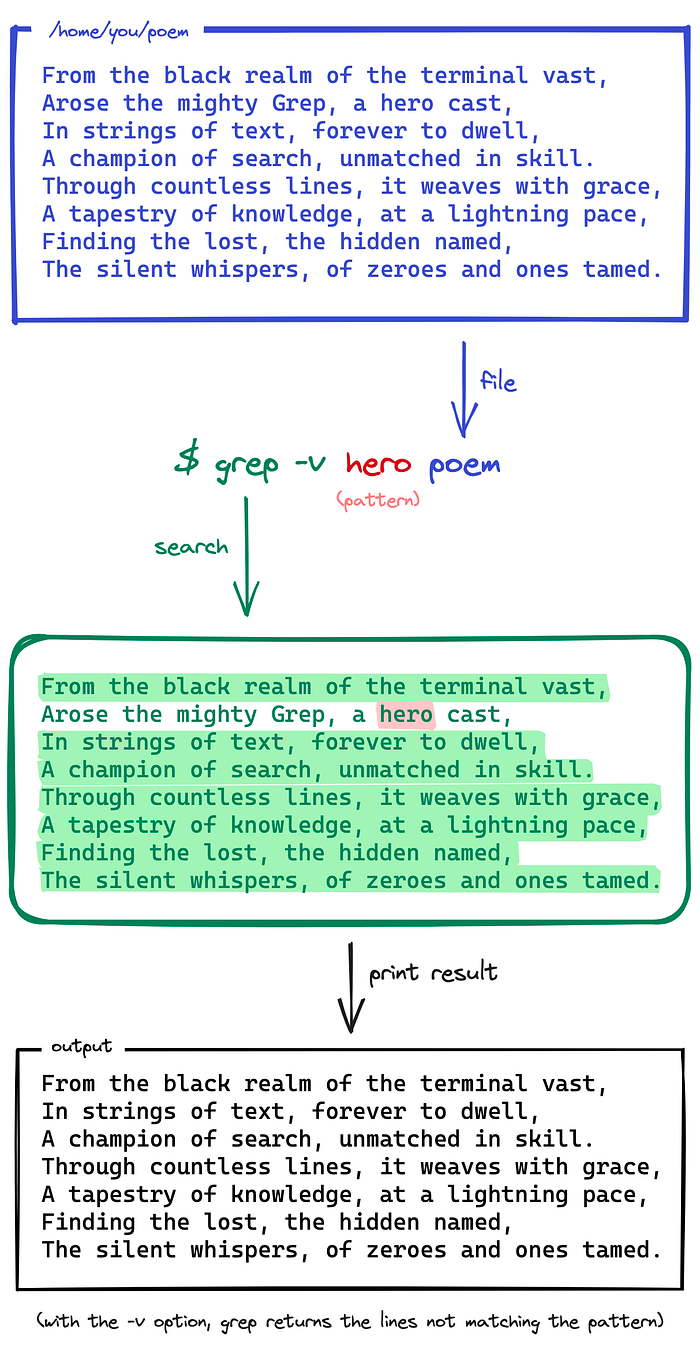
For now, let’s take grep for a spin. Suppose we have a file called “poem”, and we want to look for the word “hero” in the poem. Just type “grep hero poem”:

grep can also look for lines that don’t match the pattern with the -v flag.
You can think of it as “invert match”:
Grep can also search in several files, and there are options for counting,
numbering, and so on.
Invoking grep
The man page synopsis of the grep command is:

Passing patterns
The PATTERNS argument contains one or more patterns separated by newlines.
If you want multiple patterns but find that separating them by newlines is clumsy, you can pass them on multiple -e PATTERNS options. You can also have your patterns in a separate file, and pass them with the -f PATTERN_FILE option.
Pro-tip: you can pass
-as thePATTERN_FILEto read patterns from standard input, which is useful in some pipeline situations.
Typically, PATTERNS should be quoted when using grep in a shell because regular expressions’ special characters can overlap with the shell’s special characters.
Note: All examples from now on will wrap the search pattern in single quotes (
''), even if we don’t strictly need them. This default is suitable for real-lifegrepbecause if you get zero results (always possible), you’ll want to modify the search with something that might otherwise clash with the shell, like a whitespace or a regex.
Passing files.
You can pass one or more files. A file named - stands for standard input.
If no FILE is specified and the recursive flag (-r) is used, grep defaults to search in every file under the current directory. If the recursive flag is absent, grep defaults to search only on standard input.
Case insensitive
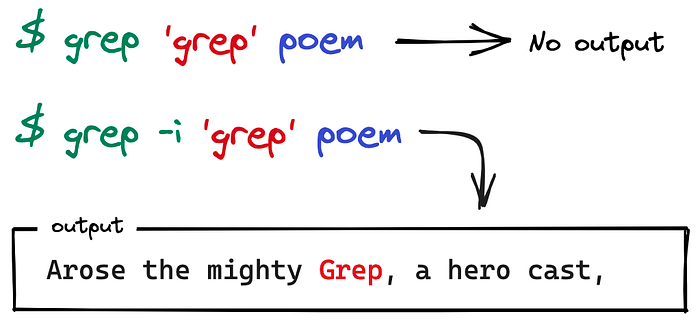
Pass -i, --ignore-case, to ignore case distinctions.
Match whole words
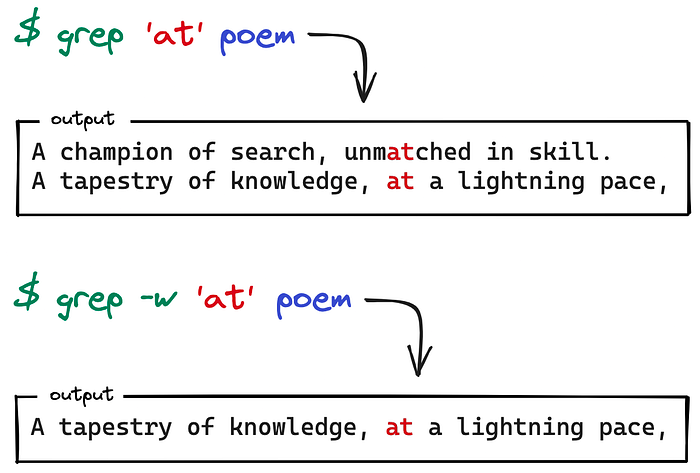
Pass -w, --word-regexp, to select only those lines containing matches that form whole words. It works by differentiating between “word constituent characters” (letters, digits and the underscore) and “non-word constituent characters” (all other characters).
It also recognizes words that are preceded and followed by the start or end of a line.
In short, it works similarly to a regular expression surrounded by \<
and \>, which mean “start of word” and “end of word” respectively. It’s also similar to \b in regular expressions, which matches any word boundary, whether it’s at the start or end.
Pro-tip: For the full details of the differences between
-w,\band\<\>, check this guide.
Match an entire line
Pass -x,--line-regexp, to select only those matches that exactly match the whole line. Same as a regular expression surrounded by ^ and $, which mean “start of line” and “end of line” respectively.
Count the number of matches

Pass -c, --count, to suppress normal output; Instead, grep will print a count of matching lines for each input file.
Add some color: --color
Possible values are never, always and auto. auto will use colors if it
thinks your terminal supports it. never is the default.
In fact, many Linux distros come with grep aliased to grep --color auto.
The colors are configurable, but the defaults are as shown in this guide:
- Bold red for the matching text
- Magenta for file names
- Green for line numbers and byte offsets
- Cyan for separators
If you want to keep the colors in the output even when you redirect it somewhere else (like less), you can use the option --color=always.
Names of matching files
If you have multiple input files, grep will prefix the file name for each match by default.
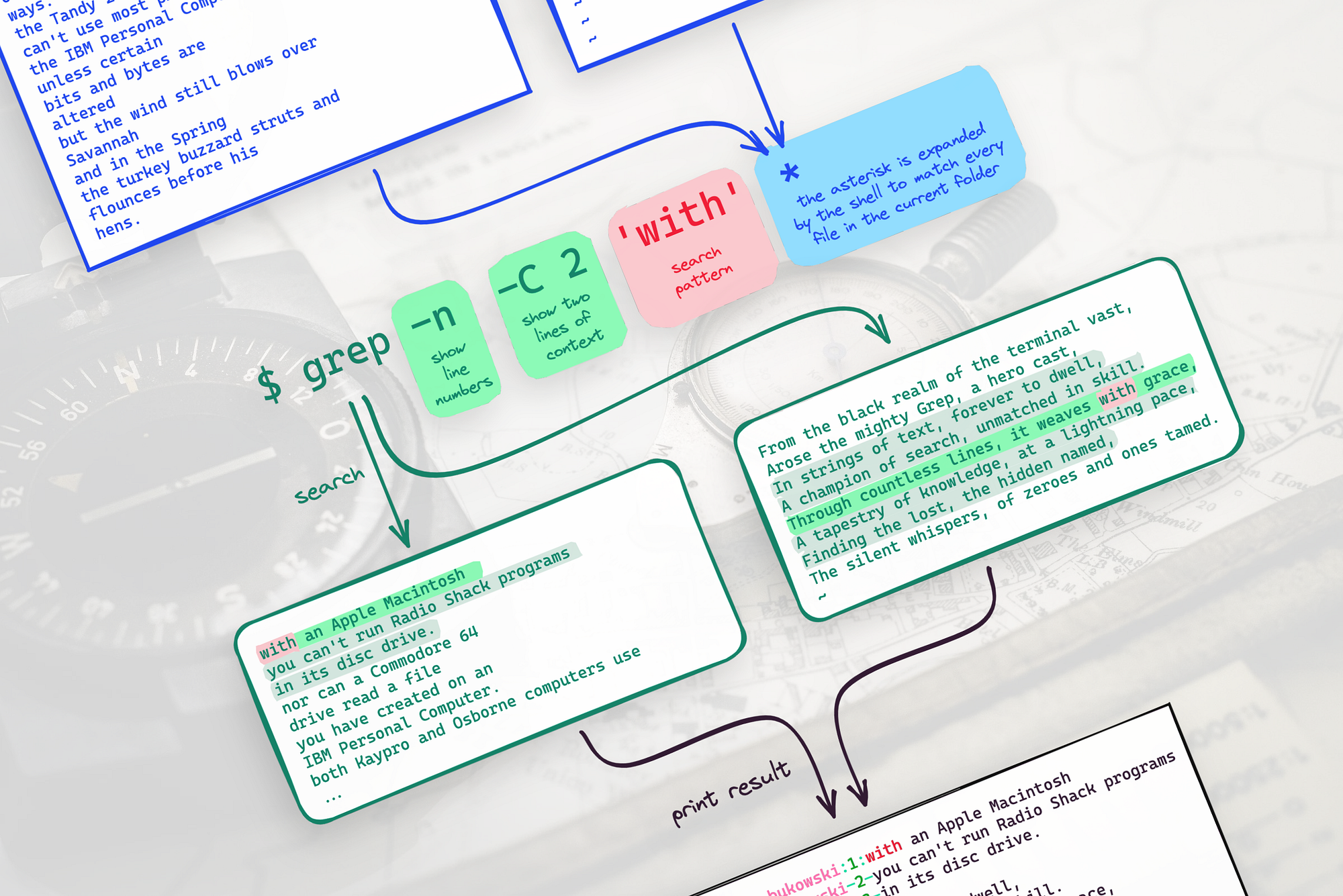
Suppose that the current directory contains our familiar “poem” file and another file with a poem by Charles Bukowski, and we want to look for the word “with” in any of those files. Just type grep ‘with’ *:
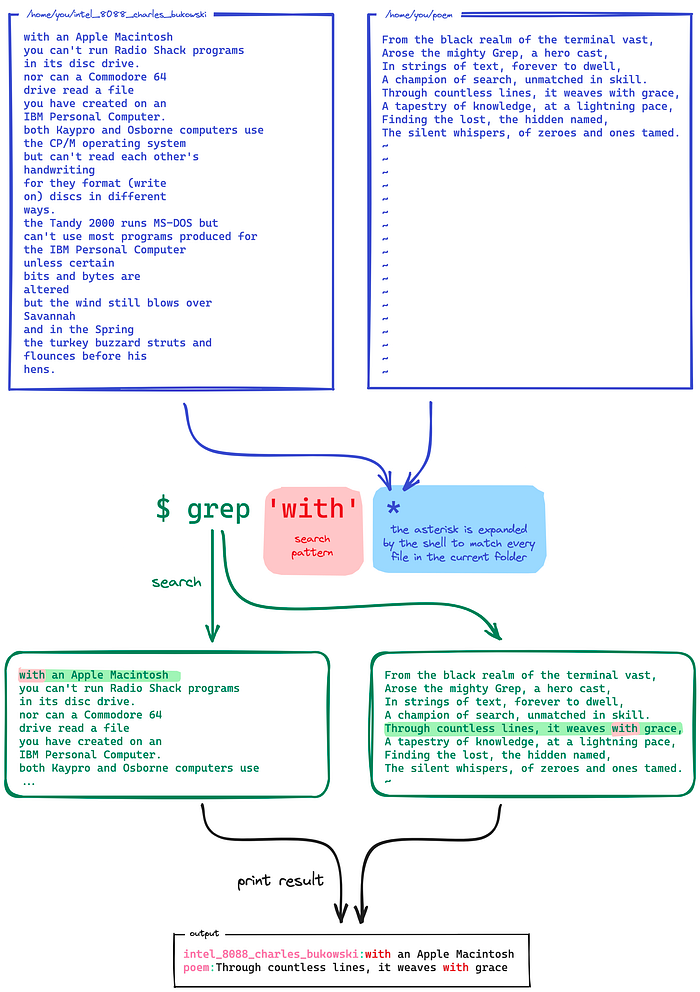
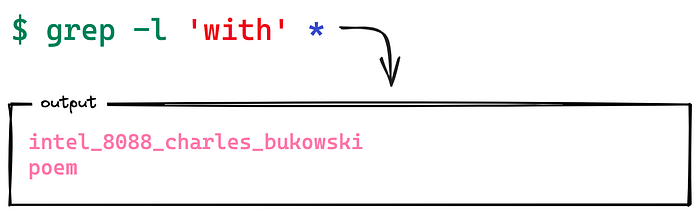
Pass -l (or --files-with-matches) to suppress normal output; Instead, grep prints only the name of each input file from which there would be a match.
You can also pass -L (or --files-without-match) to print the name of each input file from which there would be no match:

Stop after a number of matches

Pass -m NUM, --max-count=NUM, to stop reading a file after NUM matching lines.
This option reasonably adapts to other grep options:
-m NUM -vwill stop after the firstNUMnon-matching line.-m NUM -cwill not output a count greater thanNUM.
Gigachad-tip: Using
-m 1also enables an advanced feature which is a variation of passing a file from standard input to a shell while loop. This can be leaner and faster than a regularwhileloop when you want to do something complex on every matching line of a log file:
while grep -m 1 'Grep'; do
echo xxxx;
done < poemPrint only the actual match

Pass -o, --only-matching, to print only the matched parts of a matching line, with each such match on a separate output line.
This comes in handy when you have regular expressions as your pattern — otherwise, you’re just wasting your time and energy on something you already know the answer to, which is a sure way to anger the Unix gods and invite their wrath! 😱
Keep it quiet with -q, --quiet, --silent

Do not write anything to standard output. Exit immediately with zero if
any match is found.
Gigachad-flag:
-s,--no-messages— This flag suppresses error messages about nonexistent or unreadable files. Those messages occur frequently when using the-r(recursive) flag. Sometimes we want to suppress them as they convey little useful information.
Output Prefix Control

As the name suggests, these are a series of flags that affect the prefix of each output line on grep.
-n, --line-number
Prefix each line of output with the 1-based line number within its input file.
-H, --with-filename
Print the file name for each match. This is the default when there is more than one file to search.
-h, --no-filename
Suppress the prefixing of file names on output. This is the default when there is only one file (or only standard input) to search.
Context Lines
“Context lines” are non-matching lines that are near a matching line. grep can show you these lines to give you a better picture of your search results and how they fit into the text.
Let’s look at an example:
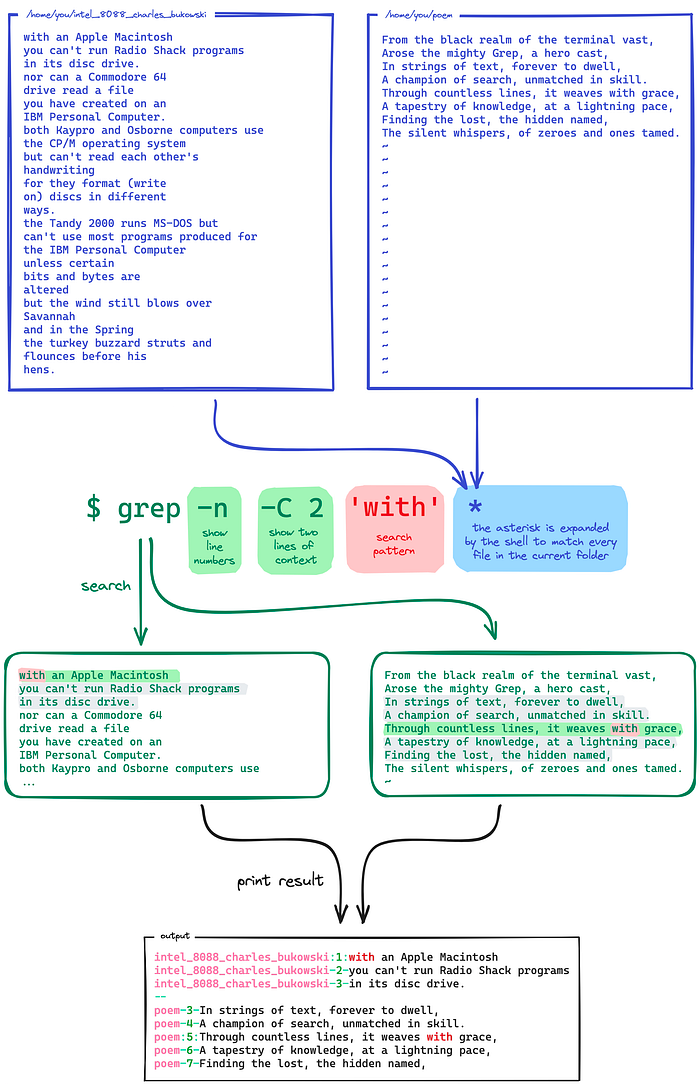
Note the following about context lines:
- Matching lines normally have a
:to separate the actual line content from the prefix fields, if any. Instead, context lines use a-. - If two consecutive groups would contain several matching lines, the groups are merged.
- Regardless of how the context line options are set,
grepnever outputs any given line more than once.
Here are the context line options:
-A NUM, --after-context=NUM
Print NUM lines of context after matching lines.
-B NUM, --before-context=NUM
Print NUM lines of context before matching lines.
-C NUM, -NUM, --context=NUM
Print NUM lines of context before and after matching lines. So, -C 2 will
print a total of 5 lines: 2 before the match, the match itself, and 2 after.
The -C option is more useful than -A and -B, unless you know that the relevant context is either before or after.
You can also pass -NUM. For example, -2 is the same as -C 2.
--group-separator=STRING
When context lines are being shown, print STRING instead of the default of -- between groups of lines.
--no-group-separator
Or, just have no separator at all. Yolo.
Note: These options have no effect if
-o(--only-matching) is specified.
File and Directory Selection Options
Ok, get ready for some advanced stuff.
A file is a sequence of bytes. Most files fall into two categories:
- Binary — a sequence of bytes whose meaning is determined by the program that reads it.
- Text — a sequence of natural-language characters (plus some formatting characters, such as “whitespace”), usually encoded in ASCII or UTF-8. By convention, lines are separated by newline characters (
\n).
While Grep works on any file, it usually reads from text files.
If a file’s data or metadata indicates that the file contains binary data (say, because of the presence of non-text bytes), then grep will “suppress” printing matches. But even then, grep will let you know if something matched inside of the binary file: it will print a message to standard error saying that a binary file matches.
By the way, grep outputs “binary file matches” because it would probably generate too much output or even crash your terminal if it attempted to output the full match — A binary file usually has no newline characters, so a match would be the entire file!
There are some flags that alter grep’s behaviour with binary files:
-I
When grep discovers a binary file, it assumes that the file doesn’t match.
This is useful when searching recursively and you just don’t care about binary files.
-a, --text
Process a binary file as if it were text.
This is the “yolo” option and it’s usually a bad idea, as your terminal might interpret some of the binary as commands and crash.
A better option is to use the strings utility to extract the text content from any file and then pipe it through grep, like this:
strings binary-file | grep pattern-d ACTION, --directories=ACTION
If an input file is a directory, use ACTION to process it. Action can be:
read: Read the directories as if they were a normal file. But most
operating systems don’t allow you to read directories, so this will
print an error.skip: Skip the directories.recurse: Read all the files under each directory, recursively, following symbolic links only if provided explicitly as arguments.
-r, --recursive
Same as --directories=recurse.
-R, dereference-recursive
Same as --recursive, but it always follows symbolic links.
--exclude=GLOB
Exclude any command line file arguments (or any file found recursively) whose suffix or base name (the part after the last slash) matches the GLOB. As a glob, it can use *, ? and [] as wildcards, and \s to escape them.
--exclude-from=FILE
Same as --exclude, but it gets one or more GLOBs from the provided FILE.
--exclude-dir=GLOB
Same as --exclude, but it only applies to directories. If a directory matches, it is skipped. It ignores redundant trailing slashes in the GLOB.
--include=GLOB
Opposite of --exclude. Both can be used at the same time. If contradicting,
the last one specified wins. If no --include or --exclude option matches,
the file is included unless the first option is --include.
Gigachad-tip: If you have complex file requirements, the
findcommand might be more versatile than the--include,--excludeand-roptions.
Other Options
--
Ah, a true classic. It delimits option lists. It’s useful when searching on files that begin with -. But who even names files like that in this day and age?
-z, null-data
Warning, this is an advanced option: It replaces every new line in the input file with a binary NUL.
Basically, it turns the entire input into a single line. This allows grep to match across lines, which goes completely against its primary directive.
It’s a bit hacky, so if you really need multi-line matching, you might want to check more advanced tools like sed and awk.
Grep variants
grep offers four variants:
- Basic Regular Expressions (BREs): Enabled by default, or with the
-G
or--basic-regexpoptions. This variant interprets patterns as basic regular expressions, as defined by POSIX. - Extended Regular Expressions (EREs): Enabled with
-Eor--extended-regexp. Allows patterns to be interpreted as extended regular expressions, as defined by POSIX. In GNU Grep, BRE and ERE are the same, with different notation. In other grep implementations, BRE are generally more limited. Most of the time you want EREs as the notation is just better. - Fixed Strings: Using
-For--fixed-strings, grep interprets
patterns as fixed strings instead of regular expressions. It significantly speeds up the search process. - Perl-Compatible Regular Expressions (PCREs): With
-Porp--perl-regexp, patterns are interpreted as PCREs. PCREs are highly versatile, often inspiring regex implementations in other languages. They include fancy features like lookbacks and backreferences.grepis typically compiled with PCRE support. It’s worth noting thatgrepprocesses text line by line, so PCRE directives that match line breaks won’t work as intended.
We won’t go into detail over the regular expression variations. For that, check this amazing guide.
Gigachad note: Unix had
egrepandfgrep, historical counterparts to the moderngrep -Eandgrep -F. They are deprecated and will be removed soon.
Frequently Asked Questions
How to grep “ps” output like a true Chad?
ps -ef | grep '[c]ron'The regular expression is pointless (cron is the same as [c]ron), but if the pattern had been written without the square brackets, it would have matched not only the ps output line for cron, but also the ps output line for this grep invocation.
You can do “OR” with "|” on regex, but how do you do “AND”?
Just pipe two greps together:
grep 'foo' file | grep 'bar'How to match empty lines?
Don’t do '’ because that matches literally everything, use '^$’ instead.
How to match lines with only spaces?
Just do '^\s*$'.
How to search both in “stdin” and a file?
Do this:
cat /etc/passwd | grep 'alain' - /etc/motdWhat if you want a faster grep?
You might have heard that ripgrep is the new grep. But the rumors of GNU Grep’s demise have been greatly exaggerated.
First of all, ask yourself this: Would you use a library that endorses murder? Ripgrep has no problem with assassination, it seems.
Joking aside, it is true that ripgrep is faster — Not to mention its trendy Rust language, and nice defaults for searching code.
But GNU Grep has been at the forefront of grep-ing for a long time, and its implementation is meant to change as faster algorithms are discovered in academia. Ripgrep might have declared victory too soon, for the slowest horse sometimes wins the race.
Think of ripgrep as the provider of a healthy dose of competition. And a great choice if you need more speed.
For a detailed comparison between GNU Grep and ripgrep, check this guide.
Closing thoughts
The journey into the world of grep has unveiled its powers as an indispensable tool with a remarkable ability to search, filter, and manipulate text data.
If the discovery of grep’s functionality has left you craving for more powerful text manipulation tools, then expanding your horizons to learn sed and awk is a natural progression.
Armed with the power of grep, sed, and awk there will be no obstacle in the text-processing realm that cannot be tamed.
Happy grep-ing!
If you liked this guide, feel free to check my visual guide to sed:
Thanks for reading! If you enjoy humorous tech stories like these and want to support me to keep writing forever, consider signing up to become a Medium member. It’s $5 a month, giving you unlimited access to stories on Medium. If you sign up using my link, I’ll earn a small commission. You can also follow me on Medium and Twitter.

