Goldilocks vs. KRR
The resources recommendation showdown!

Resource management has always been a challenge in any tech stack. Whether it’s completely VM- or container-based, the question is always — How can I make the best use of everything available to me with the least amount of compromise?
In Kubernetes, you’re probably aware of the Resources concept, which falls under two parameters: Requests and Limits.
Here’s a brief definition:
- Requests are the CPU and memory your containers inside the pod need to start and run idly. As in, your JAVA container needs 500 MB to start, but after that startup, it goes into idle mode and consumes 300MB. So, we can deduce from that, that our Request’s Memory parameter would be 500 MB. Otherwise, it will never start.
- Limits are the maximum resources the containers inside the pods can utilize from the node they are scheduled on.
In older systems, we would run significant performance tests and attempt to find the right amount of resource settings — it was shooting in the dark and hoping to hit something. In Kubernetes, these settings can be updated and checked far more dynamically than VMs and physical machines.
Enter Fairwind’s Goldilocks
The awesome folks at Fairwind created Goldilocks in its open source version, which can be found on GitHub and their Official site.
Note: I won’t be discussing how to install it. It’s for you to figure out, depending on the documentation :).
Goldilocks is a Kubernetes operator written in Go, and it watches over a few custom resources to give out its Updates or Recommendations.
What does it do? Goldilocks relies on the VerticalPodAutoscaler, which is part of the Autoscaler GitHub repository. This is from the same folks that granted us the Cluster Autoscaler.
The VerticalPodAutoscaler, or VPA for short, depends on Prometheus metrics. Even though this isn’t stated as a requirement, it’s clear from the Recommender readme file. It reads the current containers and creates a model based on that. It also queries Prometheus for those pods and containers. The query is based on eight days and a one-hour resolution (resolution is the time between changes in the graph).
The VPA can also run in “Update Mode,” which dynamically changes the Pod’s resources based on the history it calculates from Prometheus. The update mode kills the pod and spins it back up with new resources.

While running this solution and using its recommendations, you ought to have it in a performance-dedicated environment or at least some sort of separation from your continuously-running environment.
Goldilocks’ Cons
While it provides a great way to create better resource consumption, how you’d want to implement it would probably be automatic.
This is where Goldilocks falls a bit short, It’s a web-based page where you browse your namespace and deployments, and you don’t have any API access. You must access the webpage each time, check the resources, and apply them. Even if you have it in “Update Mode,” you still have to apply those values to your production deployments.
A New App on the Block — KRR
The great people over at Robusta — which you probably have heard of as well — developed the solution by the same name, Robusta. It’s an elaborate system that allows you to debug issues.
KRR stands for Kubernetes Resource Recommendations. At its core is a Pythonic CLI tool, unlike Goldilocks, but due to its simplicity, it allows you to integrate it easier.
The tool itself looks for Prometheus by default, just like Goldilocks. However, it only works in one mode — recommendation. The cool thing is that you can partially customize the default query provided out of the box.
By default, KRR looks up to seven days of history for memory, and for CPU, it adheres to the ideas of this article. Just for kicks, I recommend reading both and making your own decisions about the counter argument.
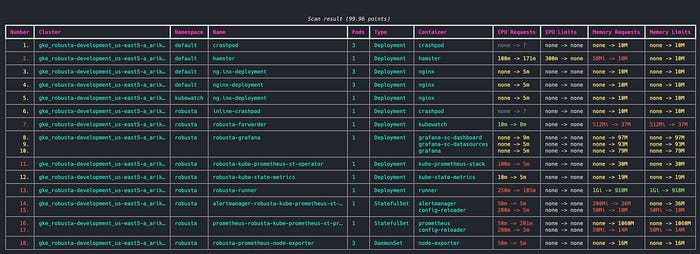
Another cool thing is that KRR allows you to add your own custom Python code to create your own recommendation strategy and view. If you’re not content with just CPU and memory metrics, you can add more calculations to the equation.
There’s also a provided Dockerfile you can build and throw as part of your CI — assuming that the pods you want to change have already been running for a while. Because you can run it as a CLI tool, this also translates to running it in pipelines and sending the results wherever you need via webhooks.
KRR Cons
Because it runs as a CLI tool, you must run it each time to get the results, unlike Goldilocks, which displays a UI with the reflected changes. This means time is consumed until you get a response. The bigger the namespace you wish to query, the longer a reply will take.
Overall
Both solutions are excellent and represent a great ability that is much needed for proper resource allocation. Combining both will create an awesome suite for performance teams to set the most applicable values for the applications to consume.
