Getting Started With LlamaIndex
Create a Python app to query GitHub repos from scratch

There’s been a lot of chatter about LangChain recently, a toolkit for building applications using LLMs. You might have also heard about LlamaIndex, which builds on top of LangChain to provide “a central interface to connect your LLMs with external data.” But what exactly does it do, and how can you use it?
I’ll start with the first question straight away, and then the rest of this article will walk you through an example of how to use it. It doesn’t take long to get value, so follow along and try it out. It’s worth it!
A Quick Overview
The basic premise of LlamaIndex is that you’ve got some documents — bits of text, code, whatever — which you’d like to ask questions about like you would with ChatGPT, except imagine it’s just read all of your documents. Now, there are generally three ways to go about this:
- Finetune your own LLM. You adapt an existing LLM, such as LLaMA, by training your data. This is also costly and time-consuming, albeit only once.
- Feed all your documents into one humongous prompt of an LLM. This might work for you now that Claude accepts 100k tokens, but it will be slow and expensive.
- Feed relevant information into the prompt of an LLM. Instead of feeding it all the data, you try to pick out the bits useful to each query.
LlamaIndex does number 3. Here’s how it works:
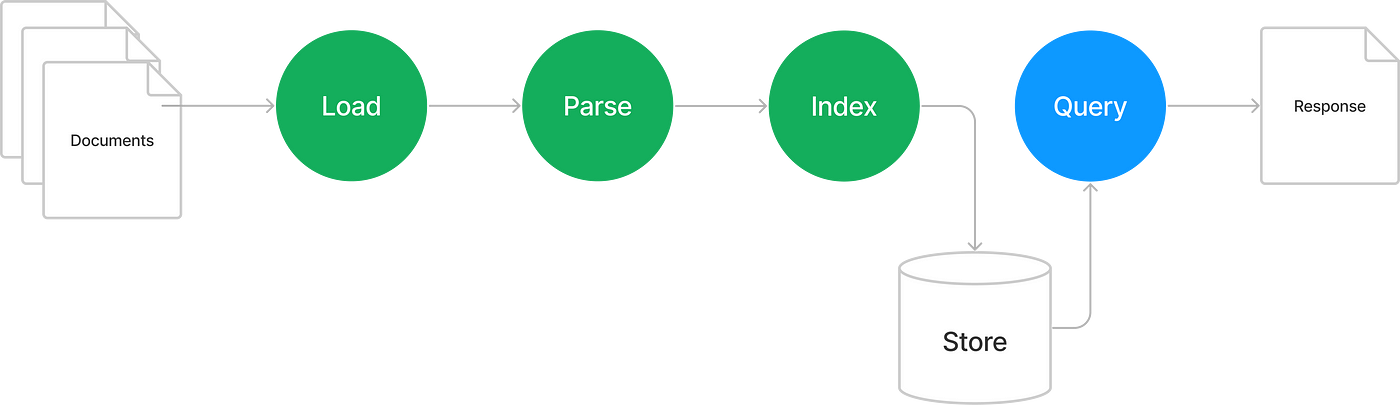
Starting with your documents, you first load them into LlamaIndex. It comes with many ready-made readers for sources such as databases, Discord, Slack, Google Docs, Notion, and (the one we will use today) GitHub repos.
Next, you use LlamaIndex to parse the documents into nodes — basically chunks of text. An index is constructed next so that, later, when we query the documents, LlamaIndex can quickly retrieve the relevant data. The index can be stored in different ways, but we will use a Vector Store because it’s typically the most interesting one if we want to query across arbitrary text documents.
As I mentioned at the beginning, LlamaIndex is built on top of LangChain, and you can think of LangChain as being the fundamental building blocks for lots of different kinds of LLM applications. LlamaIndex, on the other hand, is streamlined for the workflow described above.
In the next section, we’ll build up an example using a GitHub repo as a source of documents and ask queries about the documents. Think of it like talking to a GitHub repo.
Creating a new LlamaIndex Project
We’re going to start with an empty project. I’m using Poetry because it offers better package management than vanilla setup tools, and it’s easier to create a virtual environment to ensure you get the same library dependencies as I do. I’m also going to add llama_index to the project straight away.
$ poetry new llama-index-demo
Created package llama_index_demo in llama-index-demo
$ cd llama_index_demo
$ poetry add llama-index
Creating virtualenv llama-index-demo-fKDNAv12-py3.11 in /nfs/home/owen/.cache/pypoetry/virtualenvs
Using version ^0.6.7 for llama-index
Updating dependencies
Resolving dependencies... Downloading https://files.pythonhosted.org/packages/9d/19/59961b522e6757f0c9097
Resolving dependencies... Downloading https://files.pythonhosted.org/packages/f6/33/92cf0cc4a58fde3b1e573
Resolving dependencies... (14.2s)
Writing lock file
Package operations: 38 installs, 0 updates, 0 removals
• Installing packaging (23.1)
...
$ poetry shell
...
(llama-index-demo-py3.11) $Now we will work our way step-by-step through the pipeline in the introduction.
1. Load the Documents
Since our “documents” will be the files in a GitHub repository, we’ll head over to Llama Hub to look for a suitable loader and lo and behold, there’s one called github_repo. Here’s what it looks like:
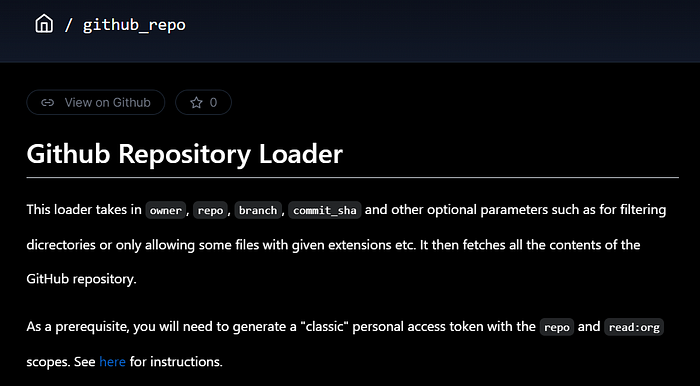
The loader requires a GitHub personal access token which you’ll need to generate on the GitHub settings page.
Copy and paste the token into a file in the project called .env, which will be read when you run the code:
GITHUB_TOKEN=<access token here>Now, we’ll make a file ingest.py and start with the following code:
import os
from llama_index import download_loader
# Use the GithubRepositoryReader to load documents from a Github repository
download_loader("GithubRepositoryReader")
from llama_index.readers.llamahub_modules.github_repo import (
GithubRepositoryReader,
GithubClient,
)
github_client = GithubClient(os.getenv("GITHUB_TOKEN"))
# Create a loader
loader = GithubRepositoryReader(
github_client,
owner="jerryjliu",
repo="llama_index",
filter_directories=(
["llama_index", "docs"],
GithubRepositoryReader.FilterType.INCLUDE,
),
filter_file_extensions=([".py"], GithubRepositoryReader.FilterType.INCLUDE),
verbose=True,
concurrent_requests=10,
)
# 1. Load documents
docs = loader.load_data(branch="main")LlamaIndex has a method download_loader to load from the hub on-the-fly. The GitHubRepositoryLoader, which we create with it, takes some arguments, such as the repository owner, name, directories, and files to filter. I’m going to scan the llama_index repo itself. You should be able to run this code as-is, and it will fetch the repo.
Now, docs is a list of all the files and their text, we can move on to parsing them into nodes.
2. Parsing the Documents
Things couldn’t get simpler than the following code:
# 2. Parse the docs into nodes
from llama_index.node_parser import SimpleNodeParser
parser = SimpleNodeParser()
nodes = parser.get_nodes_from_documents(docs)OK, but what’s a SimpleNodeParser (and is there a Complex one)? Well, it splits the text in each document and breaks it into bite-size chunks. There aren’t any other kinds of parsers out-of-the-box, but if you have some special requirements, you can create the nodes yourself, but let’s not go there now.
3. Index Construction
Actually, things do get simpler. Take a look at the code below:
# 3. Build an index
from llama_index import GPTVectorStoreIndex
index = GPTVectorStoreIndex(nodes)This will create embeddings (check out this article for a visual explanation) for each node and store it in a Vector Store.
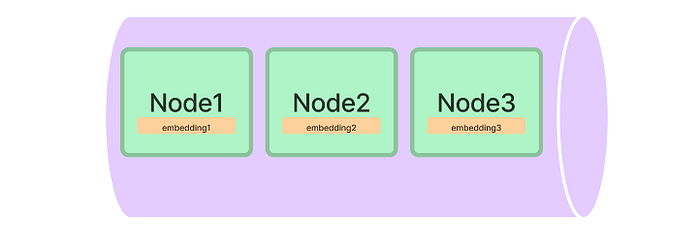
By default, LlamaIndex will use OpenAI to create the embedding, so you’ll need an OpenAI key. Head over there to create one and add it to the .env file:
OPENAI_API_KEY=<your OpenAI key>4. Store the Index
At this point, the GitHub repository will be read, parsed, and indexed, but the index will be in memory, meaning that you’ll need to rerun the whole pipeline every time you want to do a query. Fortunately, LlamaIndex has many storage backends (e.g., Pinecone is the most well-known), but we’re going with the simplest option: JSON flat-files
# 4. Store the index
index.storage_context.persist(persist_dir="index")If you run our ingestion script now, it should create a directory called index with a few files in it. Of particular interest is vector_store.json which should contain something like:
{"embedding_dict":
{"56fa485f-1c2b-448e-9538-d76ffad98add":
[0.014967384748160839,
0.04618736729025841,
-0.001153847435489297,
-0.011105049401521683,
-0.004625430330634117,
...These are the actual embeddings representing the documents you just loaded! Now, we’re all set to start asking questions.
5. Run a Query
We’ll do this in a new file called query.py so that we don’t have to keep running the ingestion if we want to change our query:
from llama_index import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="index")
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
response = query_engine.query(
"What does load_index_from_storage do and how does it work?"
)
print(response)So, if that’s unclear, we’re loading the index you created in the previous steps, preparing a query engine, asking it a question, and printing the response. Let’s run it and see:
$ python query.py
load_index_from_storage is a function that loads an index from a
StorageContext object. It takes in a StorageContext object and an optional
index_id as parameters. If the index_id is not specified, it assumes there is
only one index in the index store and loads it. It then passes the index_ids
and any additional keyword arguments to the load_indices_from_storage
function. This function then retrieves the index structs from the index store
and creates a list of BaseGPTIndex objects. If the index_ids are specified, it
will only load the indices with the specified ids. Finally, the function
returns the list of BaseGPTIndex objects.Sweet! 🍬
Next Steps
There are a tonne of other directions we could take this next. I’ll aim to cover some in subsequent articles, but I think this is a good point to wrap up because we’ve already made something end-to-end that does something genuinely useful with very little code.
I’ve created a GitHub repository with the working code at ofrasergreen/llamaindex-demo.

