Forget Luck: Optimized Wordle Strategy
Leverage Google BigQuery to find the three words that will let you dominate Wordle

Wordle is a surprisingly addictive word game by Josh Wardle that has taken the Internet by storm. It has sparked many copycats, several spoofs, and playing in other languages is definitely possible: spanish, german, portuguese, welsh… Klingon anybody?
Fun fact: the acronym of this article’s title is a nice word: FLOWS. Too bad it can’t solve the game. Keep reading to know why.
After playing it myself for a while (read: getting addicted) and having studied multiple articles on what’s the best strategy to play or what‘s the best word to use as the first move, I decided to investigate to see if I could come up with something of my own.
I’ve seen people using general programming languages (JavaScript, Python, C++…) or spreadsheets (Google Sheets, Excel…) to elaborate on Wordle, so I thought I’d try something different: I’m going to use a database. I will go into full serverless mode and leverage Google BigQuery to do the heavy lifting, Google Cloud Shell to do all the command line stuff, and Google Data Studio for visualizations.
Disclaimer: this strategy might ruin your Wordle experience. Please be warned.
As a general rule of thumb, once a 🟨 or a 🟩 is revealed, it’s a good idea not to repeat that letter and instead try new letters to explore as much as possible. This is especially true for 🟩’s. Reusing 🟩’s results, as expected, in the same 🟩 in the same positions: nothing new has been learnt.
The amount of new information (called entropy in information theory) is maximized using different letters in each turn.
Two players solving the same Wordle:

Therefore, it’s better to use words with as many different letters as possible, ideally all 5 of them, to maximize the new information obtained per turn.
Following this idea, 4 words ranked from “best” (more entropy) to “worst” (least entropy):
- GROUP tests 5 different letters: G, R, O, U, and P
- LIMIT tests 4 different letters: L, I, M, and T
- ARRAY tests 3 different letters: A, R, and Y
But there are multiple 5 letter words with unique letters: BEGIN, BREAK, FALSE, FETCH, OUTER, RAISE, RANGE, RIGHT, TABLE, UNTIL, USING, WHILE…
Is it possible to know if one word is “better” than another? Let’s find out!
Wordle uses two different groups of words:
- Solutions: the words that have to be guessed, mostly everyday words.
- Guesses: words that you can use to guess the wordle but are never the solution, some of them obscure.
In order to find the solution and guess words I turned to the game’s TypeScript source code in GitHub:
wordlist.ts ['cigar','rebut','sissy', … ,'artsy','rural','shave']validGuesses.ts ['aahed','aalii','aargh, … ,'zygon','zymes','zymic']
Extracting and saving them to a CSV file is easy:
The output is:
First three solution words:
"cigar","solution"
"rebut","solution"
"sissy","solution"Last three guess words:
"zygon","guess"
"zymes","guess"
"zymic","guess"Number of words per type:
2315 "solution"
10657 "guess"
12972 wordle.csv
Wordle’s lexicon comprises 12,972 words that you can use to play the game: 2,315 solutions and 10,657 guesses.
I will create a new Google BigQuery dataset called wordle to keep things tidy. Then I’ll load those words into a table (raw_words) to start exploring.
Let me quickly check that all data was correctly uploaded to Google BigQuery:
Since Wordle uses all caps and the extracted words are lowercase, I’ll quickly create a new table (normalized_words) with all words in uppercase to make things look pretty. I’ll keep the original word because storage is cheap in Google BigQuery:

The next step is to create a lookup table (letters) with all the different letters present in all the words (both solution and guess).
I’ll precalculate a number (letter_bitmask) for each letter. This will make my life easier down the road.
This table will look something like this:
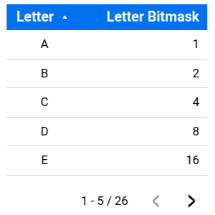
As you can see in the image above, the original Wordle uses 26 letters so think of the letter bitmask as a sequence of 25 0's and exactly one 1 that moves around.
If I consider those 0s and 1 as a binary number and I convert them to decimal I get the letter bitmask:
A = 0000000000000000000000000000001 = 1
B = 0000000000000000000000000000010 = 2
C = 0000000000000000000000000000100 = 4
D = 0000000000000000000000000001000 = 8
E = 0000000000000000000000000010000 = 16
F = 0000000000000000000000000100000 = 32
................................................
X = 0010000000000000000000000000000 = 8,388,608
Y = 0100000000000000000000000000000 = 16,777,216
Z = 1000000000000000000000000000000 = 33,554,432At this point, I can start analyzing Wordle’s lexicon. I’ll calculate a few things first:
- Length: In the original Wordle, this will always be 5. No surprises here.
- Word bitmask: this is a number that encodes which unique letters the word is using.
- Unique letters: how many different letters a word is using.
Let me briefly explain how the word bitmask is calculated.
I start separating the 5 letters that make up a word, then I remove any duplicates (GROUP BY letter does this for me) and finally I add the individual letter masks of the letters that are left. Some examples:
BITMASK(ADDED) → {A,D,D,E,D} → {A,D,E} → {1,8,16} → 25
BITMASK(FADED) → {F,A,D,E,D} → {A,D,E,F} → {1,8,16,32} → 57
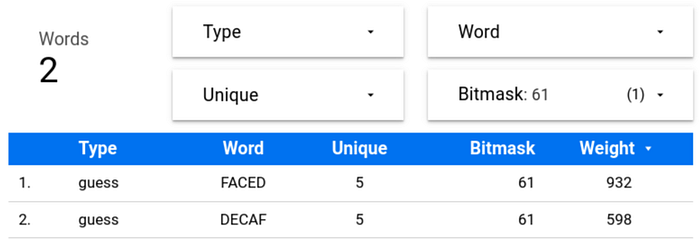
BITMASK(FACED) → {F,A,C,E,D} → {A,C,D,E,F} → {1,4,8,16,32} → 61
BITMASK(DECAF) → {D,E,C,A,F} → {A,C,D,E,F} → {1,4,8,16,32} → 61Note that FACED and DECAF have the same word bitmask because they both use the same letters, albeit in different order. These are the only two words with A, C, D, E, and F in Wordle’s lexicon:
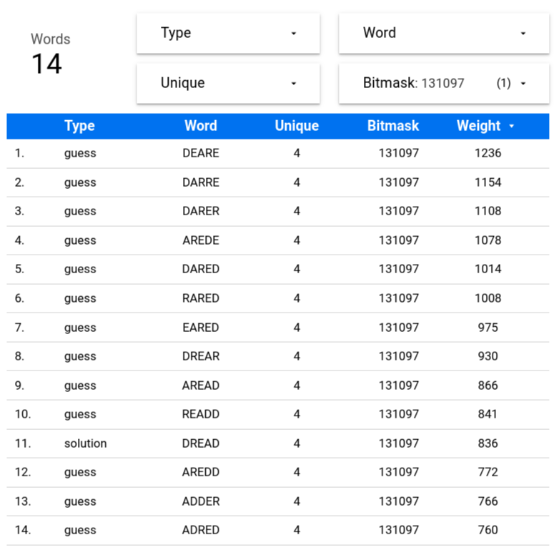
Fun fact: Wordle lets you play with 14 words that can be formed combining and repeating the letters A, D, E, and R. How many do you know? (Full list at the end)
Calculating how many unique letters a word is using is very easy: I just need to count how many 1’s there are in the word bitmask.
Google BigQuery has the BIT_COUNT(expression) function that will do exactly what the name says: count how many 1’s are present in expresion .
Let’s take some word bitmasks, their binary equivalents and count the 1's:
BIT_COUNT(BITMASK(ADDED) = BIT_COUNT(25) = BIT_COUNT(0b011001) = 3
BIT_COUNT(BITMASK(FADED) = BIT_COUNT(57) = BIT_COUNT(0b111001) = 4
BIT_COUNT(BITMASK(FACED) = BIT_COUNT(61) = BIT_COUNT(0b111101) = 5
BIT_COUNT(BITMASK(DECAF) = BIT_COUNT(61) = BIT_COUNT(0b111101) = 5Let’s see how many solution words there are taking into account the number of unique letters:
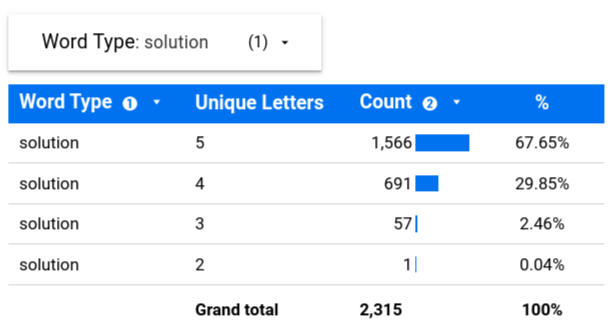
This information may be useful when you only have one turn left and you can’t decide whether you’re going to go with DOING or GOING as your final word.
For every 3 words, odds are that 2 will have 5 unique letters and 1 will have 4. Therefore, the most probable answer is DOING: the word with 5 unique letters.
Maybe it’s just me, but the fewer unique letters a word has, the harder I find it to solve.
Fun fact: there is only 1 solution that uses 2 different letters. Don’t worry, I won’t spoil the surprise.
Now I’m going to borrow a trick from cryptanalysis and I’ll perform a quick letter frequency analysis to determine how letters are used in Wordle’s lexicon, but only on solution words:

The most frequent letters in Wordle solutions are E, A, R, O, and T, so a good starting word should be one that has all those letters.
The least frequent letters are Z, X, Q, and J. Most probably, you won’t come across words that use them.
Fun fact: out of 2,315 solutions, only 27 words use the letter J (the least used), that’s 2 orders of magnitude smaller. So yeah, pretty rare.
Finding all words that have the top 5 letters exactly once is very easy leveraging the word’s bitmask:
BITMASK(EAROT) → {E,A,R,O,T} → {A,E,O,R,T} → 671761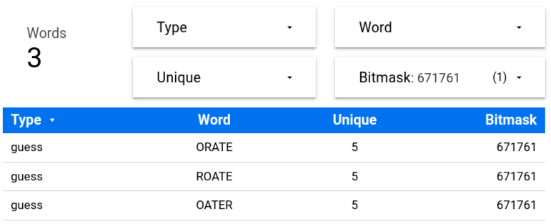
Sadly, none of those words is a solution, so even if they’re optimized guesses, it won’t be possible solve Wordle on the first turn. ☝
They’re good starting words and all three have the same probability of unveiling 🟨’s on your first turn.
But… can we do better? 🤔
Definitely!
Getting 🟨’s is very good, but getting 🟩’s is even better! Do any of these words have more probability of unveiling 🟩’s?
To answer this question, I need to extend letter frequency analysis to the position of each letter in solution words:

Getting back to ORATE, OATER, and ROATE, let’s find out the frequency of each letter at each position:

The O is not very popular as a first letter, so it seems ORATE is not a good pick. However, A is the top performing third letter and E as fifth letter does twice as good as the R in that position.
In order to understand how “good” a word is at unveiling 🟩, I need to come up with some formula that takes into account all these frequencies and outputs a number that I can use to compare two words’ efficiency in an easy manner.
Let me define some things.
First, the Positional Letter Weight (PLW for short) is the number of times a letter is present in a certain position. I will denote it as:
PLW(letter, position_in_word)So, PLW(O, 1) = 41 because O appears 41 times as the first letter. Similarly, PLW(E, 5) = 424 because E appears 424 times as the fifth letter.
Next, I’m going to define the Word Weight (WW for short) as the sum of each positional letter weight. WW can easily be defined in terms of PLW as:
WW(word) = PLW(1st_letter, 1) + PLW(2nd_letter, 2) + PLW(3rd_letter, 3) + PLW(4th_letter, 4) + PLW(5th_letter, 5)Theoretically, the higher WW is, the more probable a word will unveil one or more 🟩. Getting back to the candidate words:
WW(ROATE) = PLW(R,1) + PLW(O,2) + PLW(A,3) + PLW(T,4) + PLW(E,5)
WW(ROATE) = 105 + 279 + 307 + 139 + 424 = 1,254
WW(ORATE) = 41 + 267 + 307 + 139 + 424 = 1,178
WW(OATER) = 41 + 304 + 111 + 318 + 212 = 986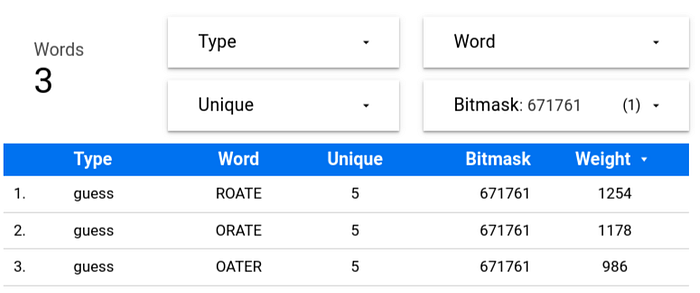
Looks like ROATE is the “heaviest” word and therefore it has more chances of unveiling 🟩’s.
But… can we do better? 🤔
I think so!
ROATE was selected purely based on the fact that those letters were the most used on solution words in any position.
Now that I have the positional letter frequency for all letters, let me calculate the weight for all 12,972 words and check if ROATE is indeed the best starting word:

- The heaviest word overall is SAREE (1,575) and has 4 unique letters
- The heaviest guess word with 5 unique letters is SAINE (1,542)
- The heaviest solution word is SLATE (1,437)
I would discard SAREE because it only has 4 unique letters (remember, I want to maximize entropy using 5 different letters) and I’d favor SLATE over SAINE purely because their weight is very similar and SLATE may grant me a satisfying instant win! 🎯
In case you’re wondering, ROATE ranks #160 🤦🏻♂ in the list of weighted words with 5 unique letters. It doesn’t look that good if we forget about overall letter frequency and instead we consider positional letter frequency and word weight.
Fun fact: the “worst” starting word you can use is “IMSHI” (australian military slang: go away; be off). Not only does it have the lowest weight (191), it’s a guess word so it’ll never be the solution to the daily puzzle. This is like playing 2–7 offsuit in Texas Hold’em… you really need to be the Doyle Brunson of Wordle to pull it off. ♥♠♦♣
Great! We have our optimized first guess: SLATE. Hopefully Wordle reveals some 🟨’s and 🟩’s.
But… can we do better? 🤔
Totally!
With the first turn already defined. Wordle unveiled some ⬛’s, 🟨’s, and 🟩’s. Now what?
Optimizing the first word to use is great. But it’s unlikely (1 in 2,370) I’m going to solve Wordle in 1 move. I need a strategy. And the simpler it is, the better: I don’t want to remember complex decision trees, tables, percentages or an endless list of words.
Using the first move to test the letters (S,L,A,T, and E) allowed me to cover 37.40%. This is a bit less than 39.69% that the top 5 letters (see rectangle ① in the image below) cover.
What if I use two moves to test the top 10 letters (E, A, R, O, T, L, I, S, N, and C)? I would cover 66.57% (rectangle ② in the image below) and I’d still have 4 turns left. Neat.
Following that logic, using three moves to test the top 15 letters (E, A, R, O, T, L, I, S, N, C, U, Y, D, H, and P) jumps the coverage to 84.20% (rectangle ③ in the image below) and I’d be left with 3 turns to complete the game. I like those odds. 🎲
Extending this logic to test the top 20 letters (E, A, R, O, T, L, I, S, N, C, U, Y, D, H, P, M, B, G, F, and K) is not very interesting since there are diminishing returns when investing an extra move: the coverage only jumps to 95.84% (rectangle ④ in the image below) but I’m left with only 2 turns to complete the game. Extremely risky.

I’m going to settle with 3 turns. This means I will be testing the top 15 letters. Let’s find out how many words with 5 unique letters contain those top 15 letters. Once again, putting BIT_COUNT() to good use:
Google BigQuery easily churns the data and reveals that out of 12,972 words there are 2,760 that contain 5 unique letters from the top 15 letters: 527 solutions and 2,233 guesses. Good.
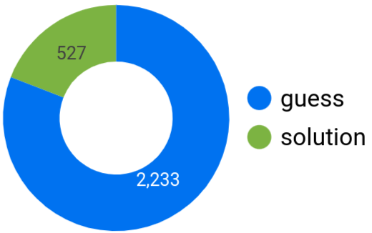
The next step is to check all the permutations of 3 words (triplets) that use the top 15 letters exactly once. For example: (ADULT, HYPER, SONIC). Calculating and checking all the permutations can be tricky since potentially Google BigQuery has to explore:
2,760 X 2,759 X 2,758 = 21,001,728,720 tripletsThat’s a “large” number but definitely nothing that Google BigQuery can’t handle.
Leveraging once again the BIT_COUNT() function, performing some bitwise operations and using some creative pruning, it takes less than 4 seconds to come up with the answer: 299,544 triplets.
Any of these triplets is a good choice for the first three tries:
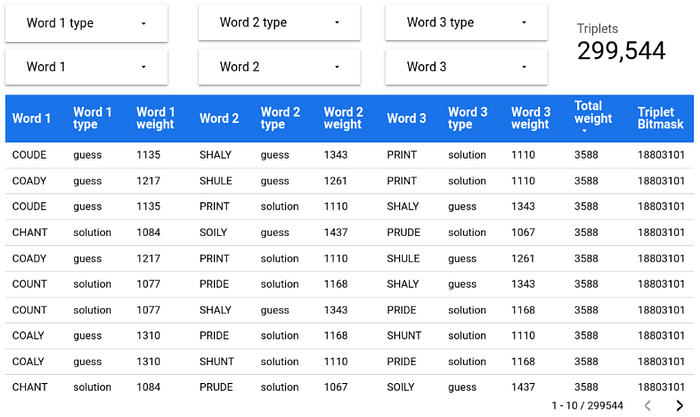
But… can we do better? 🤔
Of course!
There are some things that can still be done to optimize even further.
Firstly, I can discard all triplets that have guess words and keep only those with 3 solution words. This narrows down from 299,544 to only 2,730 triplets.
Secondly, I can pick the triplets with the highest total weight since this will give me a greater chance of revealing 🟩’s as early as possible. Turns out there are only 6 triplets with a combined weight of 3,505 formed by the permutation of these 3 words: CURLY, POINT, and SHADE.
The best triplet overall (COUDE, PRINT, SHALY) has a combined weight of 3,588 and the best triplet formed only by solution words (CURLY, POINT, SHADE) is 3,505. Their weights are so similar that it’s worth discarding triplets with guess words and going for the hole in one! ⛳

Thirdly, to reveal as much information as soon as possible, those words can be played in descending weight order:

There you have it!
Play SHADE as your first move.
Most probably, you will need more information: play POINT on your second move.
Chances are that you still need more 🟨’s and 🟩’s. Use CURLY on your third move.
After the first 3 moves, it should be just a matter of using the 🟩’s and rearranging the 🟨’s to solve the word in the fourth turn.
If I don’t have enough information to solve in the fourth move, I will need to explore more letters. I have 3 specific words I like to use in turn 4 involving the letters G, M, and B (the next 3 most popular letters) and any 🟨 vowels from the first 3 moves to try to turn them into 🟩’s. Any of this words jumps coverage to 92.04%.
Similarly, there are 5 words for the fifth move involving two of F, K, W, V, and any 🟨 vowels from past turns to cover up to 95.84%.
I won’t go into much more detail because I’m sure I’ve ruined the game for you too much by now… 🤦🏻♂
But… can we do better? 🤔
I’m pretty sure!
I don’t think this strategy is optimal as it’s most probably not solving in the fewest moves. Instead, it’s easy to remember and, most of the time, solves the game🤞.
Think of it as something similar to a beginner’s method (for example layer by layer) for solving the Rubik’s cube: very few short algorithms to remember but very slow compared to the Friedrich method used in speedcubing.
Granted, this strategy is just a routine for the first 3 moves but turns Wordle into a logic puzzle in turn 6, rather than luck all along.
Happy Wordling!
Strategy in motion:






Fun fact solved: The 14 words that use A, D, E, and R are: