Fine-tuning GPT-J 6B on Google Colab or Equivalent Desktop or Server GPU
Fine-tuning a version of Eleuther AI’s model

Natural Language Processing (NLP) has been revolutionized by recent research and the release of new transformer-based large language models(LLM) from the likes of OpenAI(GPT-2 and GPT-3), Eleuther AI (GPT-NEO and GPT-J), and Google(BERT, T5, PaLM).
Large language models are generative deep learning models that are based on transformer architecture. They seem to have dominated the vast majority of common NLP tasks such as summarization, text generation, keywords and named entity extraction, conversational chatbots, language translation, essay or blog post writing, generating computer code, writing smart contracts, and many more.
It is important to note that they can perform all of these tasks that traditional NLP models do but with a single model and out of the box without any task-specific or supervised training.
They usually require a few to no examples to understand a given task(including tasks that they were never trained for) and outperform state-of-the-art models trained in a supervised fashion.
GPT-3 and GPT-J are the most popular and easily accessible large language models today.
What Are GPT-3 And GPT-J?
GPT-3
According to Wikipedia, GPT-3 is an autoregressive language model that uses deep learning to produce human-like text. It is a general-purpose learner, which means it was not specifically trained to do any one thing. However, it is very good at translating text, answering questions, summarizing passages, and generating text output.
Basically, you can instruct GPT-3 to perform any text-based task by providing a few examples of the task in form of a prompt, and then it can learn to perform that task excellently such that when given input and will generate the appropriate or correct output.
GPT-3 has 175-billion-parameter and was revealed to the public in 2020. Although its source code has never been made available to the public, access to GPT-3 is provided exclusively through an API offered by Microsoft.
It is a successor to GPT-2 (the largest model has 1.5 billion parameters) which was also created by OpenAI in February 2019, GPT-2 was in turn developed as a “direct scale-up” and successor to OpenAI’s 2018 GPT model.
GPT-3 has a couple of limitations:
- The very large model cannot fit into a high-end PC or even expensive GPU servers.
- It is very expensive and can only be accessed through the OpenAI API.
- Lack of transparency
GPT-J
GPT-J 6B is a 6 billion parameter model released by a non-profit research group called Eleuther AI(Founded in July of 2020). Eleuther AI is a decentralized collective of volunteer researchers, engineers, and developers focused on AI alignment, scaling, and open source AI research.
GPT-J was trained on the Pile dataset.
The goal of the group is to democratize, build and open-source large language models. So they released GPT-J 6B and other models(GPT-NEO) which are currently publicly available. GPT3 on the other hand, which was released by OpenAI has 175 billion parameters and is not openly available to the public.
Despite the huge margin in the number of parameters, GPT-J has been actually shown to outperform GPT3 in some areas like code generation tasks and chatbot conversations. For information on their comparison please check here
GPT-J generally performs better than the smaller versions of OpenAI’s GPT-3 models(Ada and Babbage), but not quite as well as Davinci(GPT-3 most powerful and expensive model).
GPT-J, GPT-NeoX 20B (recently released), and other large language models from Eleuther AI can be used and deployed by anyone on a server for free.
Fine Tuning
While it is pretty obvious that the more parameters a model has the better it will generally perform, an exception to this rule applies when one explores fine-tuning. Fine-tuning refers to the practice of further training transformer-based language models on a dataset for a specific task or use case.
Using this powerful technique GPT-J can be made to easily outperform even the most powerful GPT-3 model Davinci on a number of specific tasks. Indeed fine-tuning is a powerful and invaluable technique used not just for improving the performance of language models or in NLP but also in other areas of deep learning and machine learning such as computer vision, and text-to-speech (TTS), speech-to-text (STT), GANs, image captioning and so on.
However, in this post, we are going to focus on fine-tuning a special version of Eleuther AI’s GPT-J 6B model, which is called the Quantized EleutherAI/gpt-j-6b with 8-bit weights. It was modified and developed by Hivemind and this post adapts most of the code used.
For a tutorial on fine-tuning the original or vanilla GPT-J 6B, check out Eleuther’s guide.
Fine-tuning GPT-J-6B on google colab with your custom datasets: 8-bit weights with low-rank adaptors (LoRA)
The Proof-of-concept notebook for fine-tuning is available here and also a notebook for inference only is available here.
If you want to follow the discussion on GitHub you can check here
If you are curious and want to dive deep into the inner workings and details, you should take a look at the Model card, it has more detailed explanations and auxiliary notebooks (e.g. model conversion and perplexity check).
Model description
This modified version enables you to generate and fine-tune the model on google colab or a PC with a high-end GPU (e.g. single 1080Ti).
The original GPT-J is over 22+ GB memory for float32 parameters alone, then coupled with gradients, and optimizers. Even if you cast the whole model to 16-bit, it still would not fit onto most single-GPU setups like V100, A6000, Nvidia GTX 1080-Ti, and A100. You maybe be able to perform inferencing with it on CPUs or TPUs, but fine-tuning is way more computationally expensive to perform.
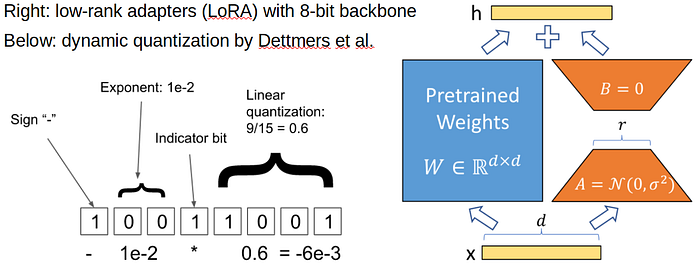
Several ingenious techniques were applied to make GPT-J 6B usable and fine-tunable on a single GPU with ~11 GB memory:
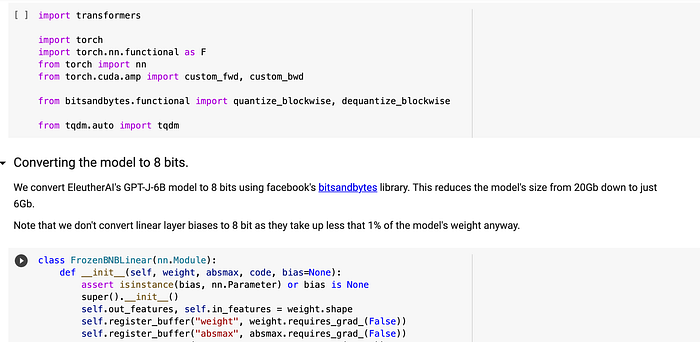
- Converting the model to 8 bits: This is done using facebook’s
bitsandbyteslibrary. This reduces the model’s size from 20Gb down to just 6Gb. Large weight tensors are quantized using dynamic 8-bit quantization and de-quantized just in time for multiplication. (The linear layer biases were not converted to 8-bit as they take up less than 1% of the model’s weight) - Using gradient checkpoints to store one only activation per layer: using dramatically less memory at the cost of 30% slower training.
- Scalable fine-tuning with LoRA and 8-bit Adam
In other words, all of the large weight-matrices are frozen in 8-bit, and you only train small adapters and optionally 1d tensors (layernorm scales, biases).
I am quite sure that at this point you must have this question at the top of your head, Does the 8-bit model affect model quality? Technically yes, but the effect is negligible in practice and the Quantized model is even slightly better but not qualitatively significant. Some studies and research have been carried out to confirm this, you can take a look into it here.
Also Performance-wise, depending on the GPU and batch size used, the quantized model is about 1–10% slower than the original model.
However the overhead from de-quantizing weights does not depend on batch size, as a result, the larger batch size you can fit, the more efficient you will train.
Open source status
The authors:
- the original GPT-J-6B was trained by Eleuther AI (citation: Ben Wang and Aran Komatsuzaki)
- fast quantization from bitsandbytes by Tim Dettmers
- low-rank adapters were proposed for GPT-like models by Hu et al (2021)
- this notebook was created by me ( @deniskamazur ) with some help from Yozh ( @justheuristic)
You can fine-tune on colab and other free GPU providers: kaggle, aws sagemaker, or paperspace.
Fine-tuning GPT-J-6B on Paperspace with your custom datasets: 8-bit weights with low-rank adaptors (LoRA)
I was able to fine-tune GPT-J 6B 8-bit on paperspace. I experimented with several GPU-enabled servers. I was able to fine-tune a dataset(consisting of 10k words articles) of about 2MB in 50 mintutes with A5000 and in 20 minutes with A6000.

To fine GPT-J-6B 8-bit, all you need is a set of training and test examples formatted in multiple text files with each example generally consisting of a single input example and its associated output. The optimal way to format your dataset will depend on your specific use case.
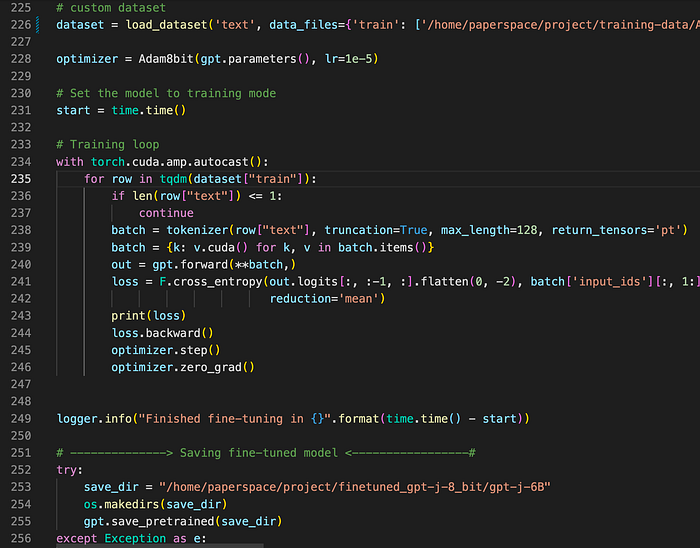
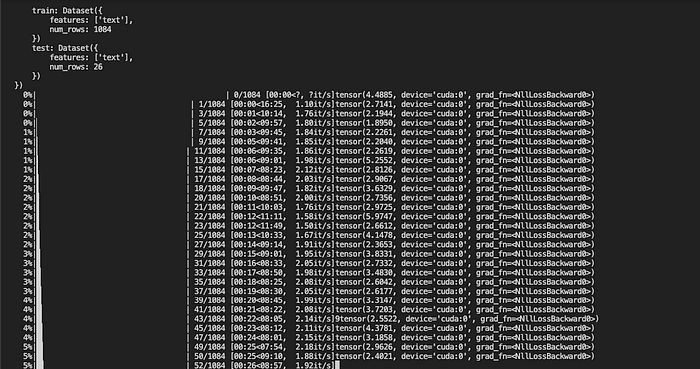
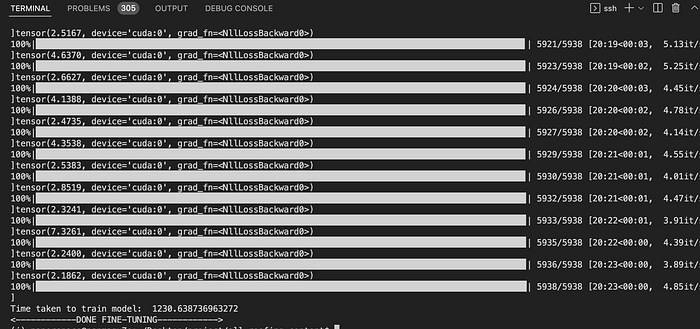
Here is the link to access the code which I used to fine-tune GPT-J 6B 8-bit on paper space. The GitHub repo also contains code for a simple API built with FastAPI for performing inferencing with the model.
I hoped you enjoyed following this post and found it useful.
Special thanks to Eleuther AI and Hivemind.
Connect with me on Linkedin , Twitter and Github, website. Are you looking to drive your business forward with cutting-edge generative AI and machine learning solutions? Look no further than our consulting and development services! visit our website
Our team of experienced designers, software developers, data scientists and machine learning experts can help you harness the power of your data to gain valuable insights, make data-driven decisions and deliver bespoke solutions.
Whether you’re looking to build or fine-tune custom models or optimise existing algorithms or develop entirely new applications on top of cutting-edge models and APIs like GPT-4, GPT-3, ChatGPT-3, Dalle-3, GPT-J, GPT-NEO, BERT, T5, Stable Diffusion, and so on…we have the expertise to help you achieve your goals!
Our comprehensive development services includes everything from design, data science, AI, ML and modeling to software development and cloud deployment. We’ll work closely with you to understand your unique business needs and develop bespoke solutions that delivers measurable results.
Don’t let your data go untapped or your ideas vanish!
Contact us today to learn more about our consulting and development services and take your business to the next!
#datascience #machinelearning #consultingservices, # deeplearning #chatgpt #gpt-3 #gpt-4 #LLM #generativeai #cloud #chatbots #NLP

