You're unable to read via this Friend Link since it's expired. Learn more
Member-only story
Fine-Tuning GPT-3.5 RAG Pipeline with GPT-4 Training Data
NVIDIA SEC 10-K filing analysis before and after fine-tuning

OpenAI announced on August 22, 2023, that fine-tuning for GPT-3.5 Turbo is now available. This update allows developers to customize models that perform better for their use cases and run these custom models at scale.
Hours later that same day, LlamaIndex announced the release 0.8.7, with the brand new integration of fine-tuning OpenAI gpt-3.5-turbo baked into LlamaIndex already! Guides, notebooks, and blog posts were shared with the open source community immediately following the new release.
In this article, let’s take a close look at this new feature in LlamaIndex by analyzing NVIDIA’s SEC 10-K filing for 2022. We will compare the performance of the base model gpt-3.5-turbo and its fine-tuned model.
RAG vs Fine-Tuning
We’ve been exploring RAG pipelines quite a bit so far. What exactly is fine-tuning? How is it different from RAG? When should you use RAG vs fine-tuning?
There are great resources online on this topic. I came across two great articles that thoroughly analyzed RAG vs fine-tuning. I highly recommend you check them out:
- RAG vs Finetuning — Which Is the Best Tool to Boost Your LLM Application? by Heiko Hotz.
- AI: RAG vs Fine-tuning — Which Is the Best Tool to Boost Your LLM Application? by Raphael Mansuy.
My main takeaways from those two articles are the following two summary images:

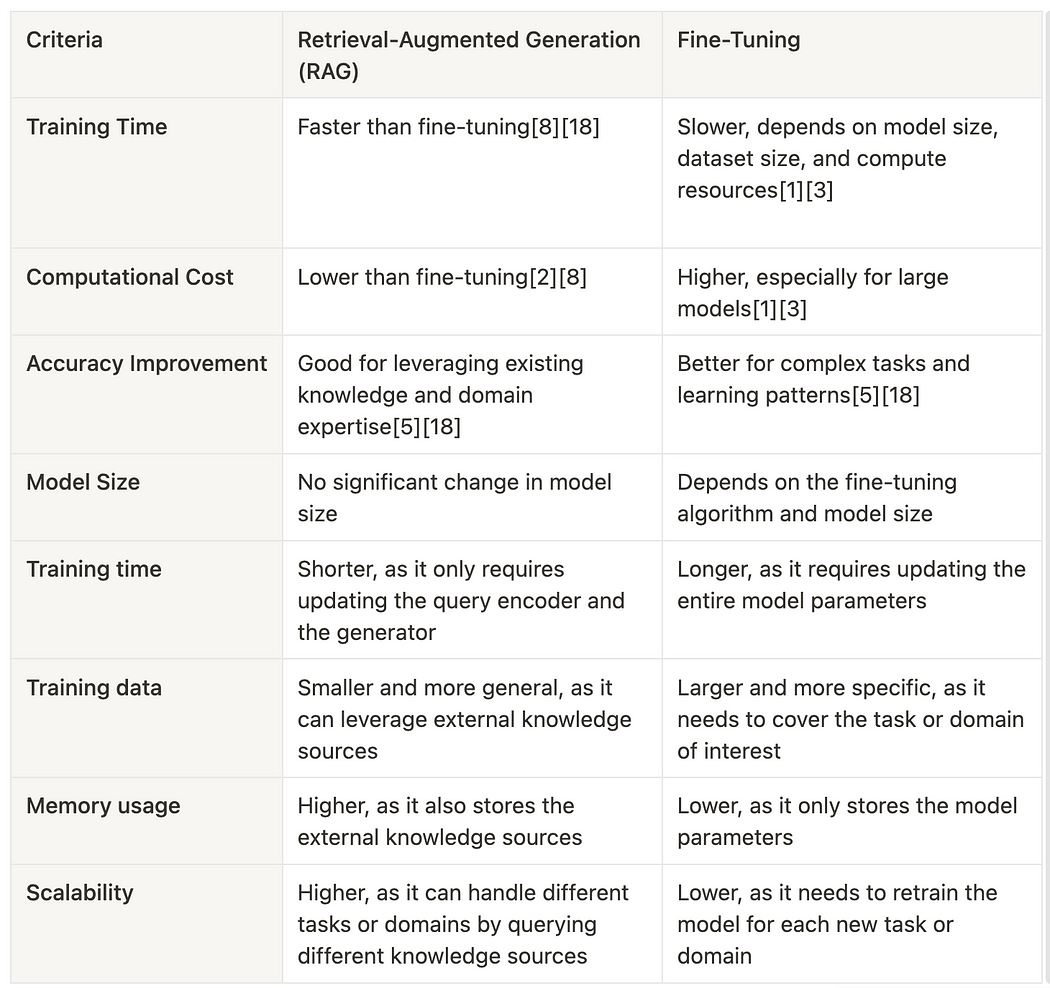
These two images summarize it all, providing us great guidance on choosing the right tool for the right use case.
However, RAG and fine-tuning are not mutually exclusive. It’s perfectly fine to have both applied in the same app in a hybrid approach. Heiko Hotz dived deep into this hybrid approach in his article, with detailed use cases…

