Everything You Need To Know About Kafka
A simple guide for beginners

Kafka, the technology that started simple from LinkedIn, is now an indispensable tool kit in most tech companies.
Every technology is created to deal with a problem. Kafka is no exception.
With that said, let’s return to the drawing board and tell you everything you need to know about this amazing technology.
Let’s get started!
Why Do We Need Kafka?

Before we dive deep, it pays to revisit why Kafka was first invented.
Imagine maintaining a group of microservices for an e-commerce company.
When an order is made, the Order server informs others as follows:
- Wallet server to deduct the amount from the user’s account
- Warehouse server to deduct the stock count of the item
- Logistic server to ship out the item
The complexity escalates when more services are to be informed when an order happens.
The order server needs to do the following:
- Keep track of whom to notify
- Ensure that all recipients have indeed received and processed the message
- Manage the connections and the routing strategy of the recipients
As you may tell, this is not scalable.
Hence, the advent of Kafka.
Message Queue vs Pub-Sub

The message queue and the Pub-Sub system are both the key to the above problem.
Instead of having the Order server maintains the event notifications, the Order server publishes the event to a middleman who behaves like a queue.
Servers interested in the queue, often known as a consumer, subscribe to the queue and consume the events accordingly.
The difference between a message queue and a Pub-Sub system lies in a subtle manner.
Message Queue
A message queue is a queue-like structure where a message is published and is consumed once and only once.
This comes in handy for processes that are not idempotent and the event should be processed by only one consumer.
RabbitMQ was initially designed to be a message queue.
Pub-Sub System
A Pub-Sub system, on the other hand, allows a message to be consumed multiple times by multiple consumers.
Our previous e-commerce example adopts a Pub-Sub solution. The order event is consumed by numerous consumers.
Kafka was designed to be both a message queue and a Pub-Sub system. We will dive deeper into how this is done in the later section.
Kafka Components

To fully understand how Kafka works, let’s dissect the components of Kafka and discuss them individually. Here’s what we’ll discuss:
- Kafka broker and cluster
- Publisher
- Consumer
- Topics
- Partition
- Consumer group
- Replica
- Zookeeper
- Long Polling
Kafka Broker And Cluster
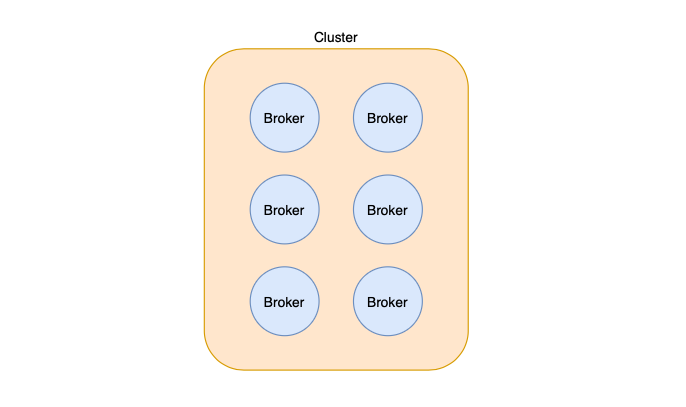
Kafka is nothing but a server that manages the publishing and consumption of data.
A Kafka server is known as a broker.
A collection of brokers that maintain the same group of topics are known as a Kafka cluster.
Publisher
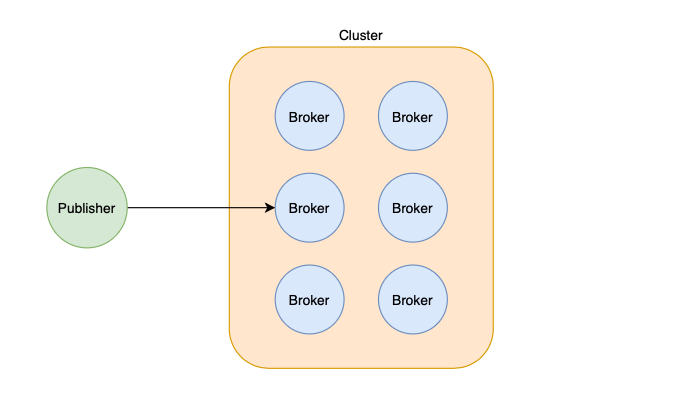
A server that publishes data to a Kafka broker is known as a publisher.
The Order server we mentioned previously is an example of a publisher.
Consumer
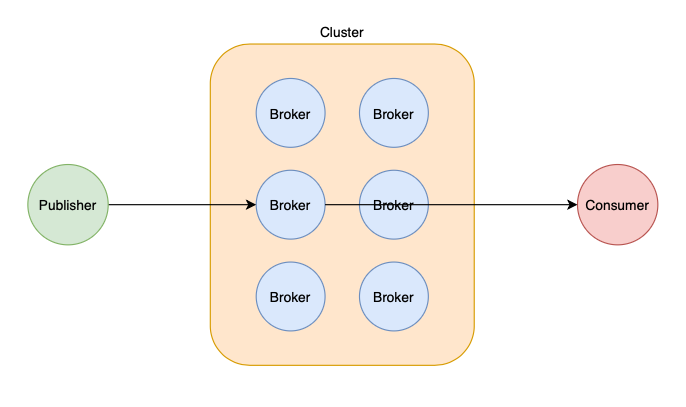
A consumer, on the other hand, is a server that subscribes and consumes data from a Kafka topic.
In our previous example, the Wallet server, Warehouse server, and Logistic server act as the consumers of the Order topic.
Topic
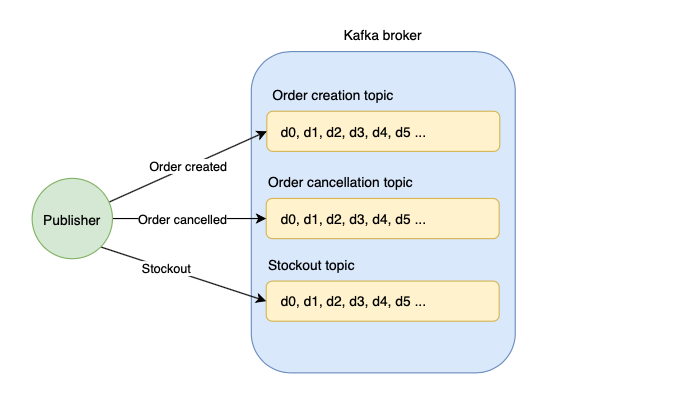
A Kafka broker maintains different types of events, such as the following:
- Order creation event
- Order cancellation event
- Stockout event
Each of these events is a massive stream of data. A topic is simply a type of event or a stream of data.
When publishing to Kafka, the publisher specifies the topic in which the message should be published.
A topic is an append-only log. Appending a message to a topic is akin to appending data to a queue, it takes O(1) constant time, hence, it’s extremely fast.
Partition
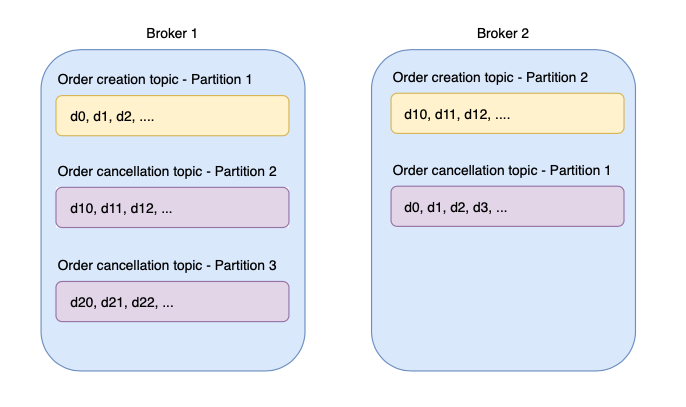
A topic is an append-only log that’s stored on a Kafka broker.
As the number of messages increases, there’s a limit on how much data a broker can store on a specific topic.
Instead of storing all the data in an append-only log, a topic can be split into multiple partitions. Each partition stores a portion of the data for a specific topic.
This is akin to database sharding.
The topic is sharded based on partitions. A partition of the same topic can be stored either on the same or a different Kafka broker. This allows Kafka to be highly scalable.
The publisher specifies the topic and the partition of a message before publishing. Hence, it’s the publisher’s responsibility to ensure that the partition logic will not result in a hot partition.
Offset
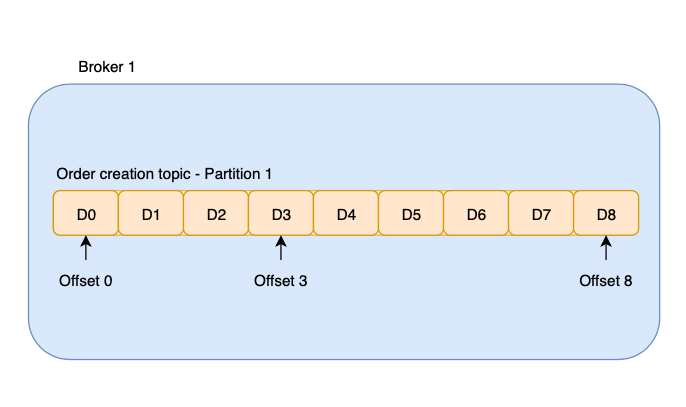
An offset is a unique index of a message in a partition.
As Kafka pushes data to the consumer, it increases and keeps track of the current offset.
There are two types of offset that are worth highlighting:
- Current offset
- Committed offset
A data can be retrieved specifically by specifying the topic, partition, and the offset of the message.
There are a lot of details when it comes to offsets. We will talk more about them in a separate article.
Consumer Group
As mentioned, Kafka is meant to be both a message queue and a Pub-Sub system. This is designed elegantly via a consumer group.
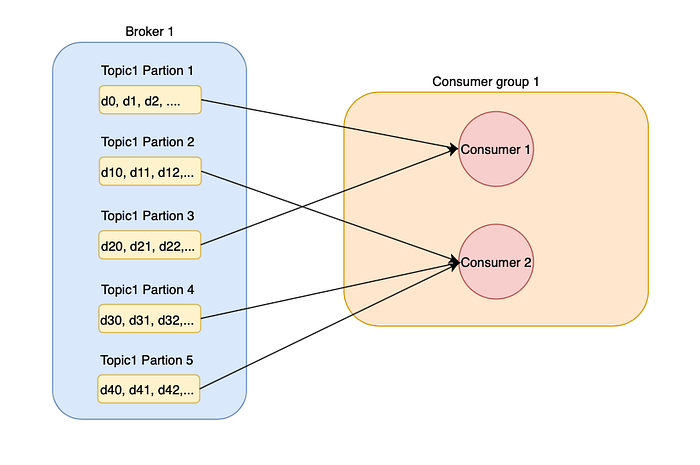
A consumer group consists of a group of consumers that consume the same topic.
A consumer can consume multiple partitions at a time. However, each partition can only be consumed by one and only one consumer from the same group.
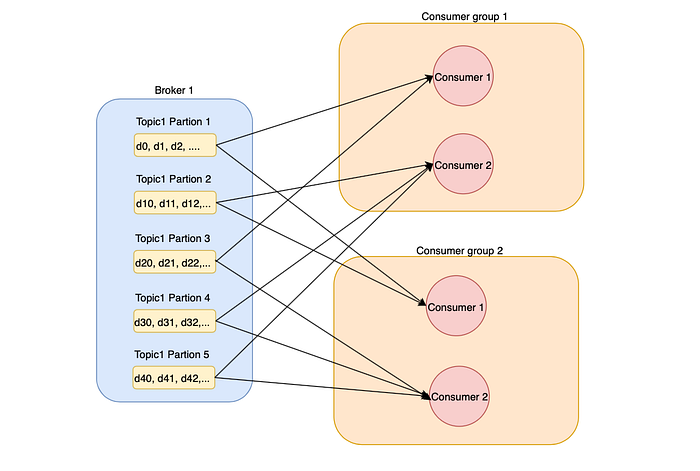
Consumer groups are independent of each other. Different groups can consume from the same topic concurrently with a different offset.
A queue is achieved by placing all the consumers in the same group. Messages in the same partition will not be consumed concurrently by different consumers from a similar group.
A queue is achieved on the partition level. Hence, if a stream of data is to be processed sequentially, the publishers must ensure that the data is always pushed to the same partition.
A Pub-Sub system, on the other hand, is achieved via multiple consumer groups. Consumer groups know nothing about each other and consume data using a separate offset.
In the previous example, the Wallet servers and the Logistic servers each belong to a different consumer group and consume data separately.
Rebalance and Partition Assignment
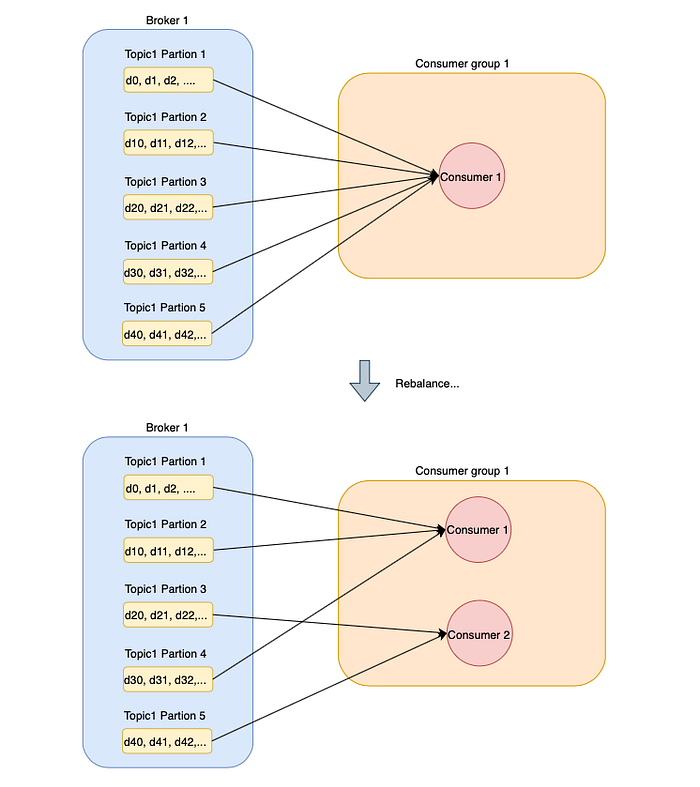
If there’s only one consumer in a group, the consumer will be responsible for the consumption of all available partitions.
When a new consumer joins the group, for example, a new server instance is added, Kafka will perform rebalancing and assigns a portion of the partitions to the new consumer.
This ensures that each consumer shares the same amount of work, hence, allowing Kafka to be scalable.
Kafka uses its own rebalance strategy for the partition reassignment and that deserves another separate article for it.
Replica
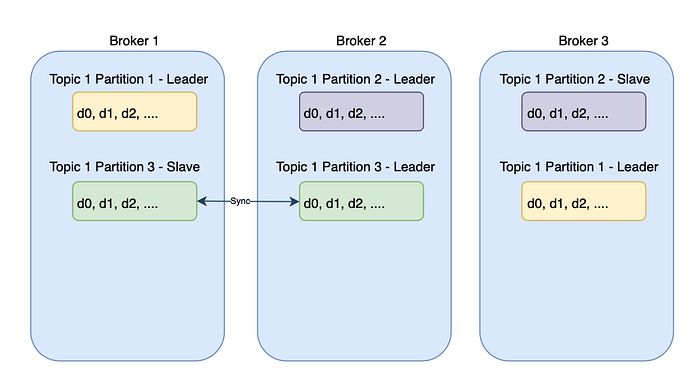
The single point of failure is the nightmare of every distributed system. Kafka is no exception.
If a broker goes down, partitions stored on the broker might go unavailable.
Hence, replicas are created on the partition level.
Replicas are created for each partition and are stored on different Kafka brokers. A leader is elected for each partition to serve both publishers and consumers.
The replicas constantly sync data from the leader. When the leader goes down, the Zookeeper joins in to help with the leader's election.
Zookeeper

As you may be pondering, there are a few missing pieces in our puzzle.
- How do we know the leader of each partition?
- How do know the number of partitions for each topic?
- How do we know the latest offset of each consumer group?
- How do we know the number of consumers in each consumer group?
That’s where the zookeeper comes into play. It’s a service synchronisation system that stores metadata and coordinates the distributed system in Kafka.
It’s mainly involved in the following:
- Leader election — Ensure that there’s a leader for each partition
- Cluster membership — Keep track of all functional brokers in a cluster
- Topic configuration — Keep track of all available topics, partitions, and their replicas
- Access control list — Keep track of the number of consumers in each group and their access right
- Quotas — Keep track of the amount of data each client can read and write
Long Polling

Here comes the million-dollar question, how does Kafka push messages to its consumers?
RabbitMQ adopts the push model. The broker maintains a persistent TCP connection with the consumers and pushes data to them should there be available data.
A push model, however, can potentially overwhelm the consumers. If the brokers push data faster than the consumers can process them, the consumers might fall behind. RabbitMQ does have a solution for this but that’s beyond our scope.
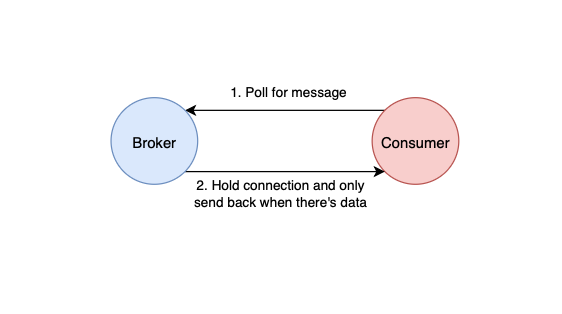
Kafka utilises a pull model, aka long polling, instead. The consumers pull data periodically from the broker. Hence, the consumers can pull data only when they are ready. However, if there’s no data on the partition, periodic polling from the consumers might result in resource wasting.
Kafka solves this by using the “long polling” waiting mode method. In short, Kafka does not return an empty response if there’s no data on the partition. Instead, the broker holds the connection and waits for data to come in before returning it to the consumers.
This alleviates the frequent polling from consumers when there’s no data on the partition and prevent the wasting of resources.
Conclusion

Here comes the end of this long-winded article.
There are a lot of details when it comes to managing Kafka, however, these are the basic components that will allow you to jumpstart your journey with this amazing technology.
I hope you find this helpful, and I’ll see you in many more that follow!
Ciao!

