Enhance Your Node.js Performance Through Clustering (Part 1)
Understand how Node.js works under the hood

Why Should We Use Clustering in Node.js?
Node.js applications run on a single processor, which means that by default they don’t take advantage of a multiple-core system. If you have a 4-core CPU and you run a Node.js application normally, then it’ll get executed on one core and the other three cores will remain unused.
Let’s discuss a basic scalability problem with a simple Node.js application.

Let’s add a small piece of code into it.
This application has two routes:
1. /slow is calling load() which will take five seconds to complete. and this route will return a random string (“I took 5 seconds”).
2. /fast is returning some random string as quickly as possible.
If I load a /slow page, it takes 5 seconds — as expected.

If I load a /fast page, it takes 6 milliseconds — which is almost negligible.

But if I try loading the /slow page first and then immediately try loading the /fast page, how much time will the execution take? Let’s check.

The /fast page took 4.5 seconds instead of the milliseconds it was taking previously.
Why did this happen?
This happened because our application is running on a single cluster. When we tried loading the /fast page immediately after loading the /slow page, the /fast page load was still waiting for the /slow page load to get completed first.
Imagine if this kind of situation occurs in a production environment where there are millions of users. This can definitely damage the user experience — and may even lead to user drop offs, which is hazardous for any organisation.
How Clustering Can Help Here
With the help of clustering, we can create multiple node clusters within the same Node.js application with the help of Node’s cluster module.
The main advantage of using this approach is we can easily scale up our application execution by utilising multiple processor cores. One more advantage is clusters run on the same port — therefore all the request will be routed through a single port.
Cluster Manager is the master process which is responsible for creating and controlling worker processes by using the fork() method of the child_process module. Although it may sound complex in theory, it’s very straightforward. We can use clustering in our application with the help of the Node.js cluster module.

For using the cluster module:
const cluster = require(“cluster”);The cluster module executes the same Node.js process multiple times, so you have to identify which portion of the code is getting executed for the master process and which portion is getting executed for the child process.
The cluster module helps us to identify the master and child processes with the help of the cluster.isMaster flag. For example:
Let’s check the output:

So if you call cluster.fork() two times.
Here’s the output:

The cluster module has executed the same process three times. The first one gets executed in the master mode, and the next two get executed in the child mode.
Let’s take the same /slow and /fast example we discussed earlier and execute it using clustering.
Let’s load the /slow route.
Now let’s load the /fast route.
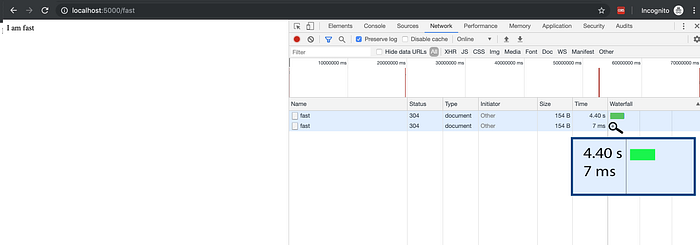
The /slow route took 5 seconds to load (the same as it was taking earlier), but the/fast route, which was previously taking almost 4.4 seconds, now gets loaded in 7 milliseconds.
Why did this happen?
Previously both the routes were getting loaded in a single core, but now with the help of clustering, these /slow and /fast routes get loaded in two different cores — as we have created two worker child processes by calling cluster.fork() twice.
What’s Next?
Plenty of doubts may definitely arise in understanding the clustering concept, such as:
- What is the ideal number of child processes we should create for the best throughput?
- Is there any better and realistic way to test the clustering flow instead of loading
/slowand/fastroutes redundantly? - Is calling
fork()the only way to use clustering (as generally it’s not used frequently)?
Don’t worry, all these questions will be answered in the next piece.
Coming up in this series
There are many more topics we need to discuss in detail. In the next few pieces, I’ll write in detail about the following topics:
- Enhancing Node.js performance through clustering (Part 2)
- How the Node event loop works internally
- Should you use hapi or Express for your startup?
Thanks for reading.