DINOv2: The New Frontier in Self-Supervised Learning?
Understanding the improvements in DINOv2
If you’re into self-supervised learning, you’ve probably heard about Facebook AI’s DINO (DIstillation of knowledge with NO labels). It was a bit of a game-changer in visual learning. Now, there’s DINOv2. It’s not just a new version but an evolution, bringing fresh improvements to the table and setting a higher bar in discriminative self-supervised learning.
Our aim here isn’t to hype up DINOv2, We’ll try to understand how it’s improved upon its predecessor, and what implications these advancements might have for the field at large. Let’s dive in and explore what makes DINOv2 tick.

A Look Back at DINO
Before we dive into the new kid on the block, let’s take a quick trip down memory lane to revisit the original DINO. It was the brainchild of Facebook AI, devised as a solution for self-supervised learning in the field of visual understanding.
The core of DINO’s architecture was built around the idea of knowledge distillation without the use of labels, hence the catchy acronym. In layman’s terms, it trained a student network to mimic the behaviour of a more powerful teacher network, all without the need for explicit labels in the training data.
Under DINO’s hood was the Vision Transformer (ViT) architecture, a design that took inspiration from the transformer models in Natural Language Processing (NLP) and applied them to visual data. This was a departure from the typical convolutional neural networks (CNNs) that dominated the scene.
DINO used a contrastive learning method where the model learns to identify similar and dissimilar examples from the data useful in image retrieval tasks. However, DINO ditched the usual practice of negative pair sampling, opting for a global self-attention mechanism instead. This allowed it to capture a more holistic view of the data.
In terms of performance, DINO made waves. It outperformed other self-supervised learning methods and even gave some supervised methods a run for their money. Its versatility was evident in its successful application across a variety of tasks, including image classification, object detection, and even instance segmentation.
But as impressive as DINO was, it wasn’t without room for improvement.
Enter DINOv2: The Enhanced Dino
DINOv2 is like DINO on steroids. It keeps the best parts of its predecessor and adds several enhancements to enable more efficient training and better performance. Here’s a look at some of the key improvements:
- The FlashAttention Mechanism: This new implementation improves both memory usage and speed in self-attention layers, crucial for managing large-scale models. It works best when the embedding dimension per head is a multiple of 64 and the full embedding dimension is a multiple of 256.
- Nested Tensors in Self-Attention: This allows running the global crops and local crops (which have different numbers of patch tokens) in the same forward pass, leading to significant compute efficiency gains.
- Efficient Stochastic Depth: This version skips the computation of the dropped residuals, thereby saving memory and computing power.
- Fully-Sharded Data Parallel (FSDP): The models are now split across GPUs, allowing the model size to be bounded not by the memory of a single GPU, but by the total sum of GPU memory across all compute nodes.
- Model Distillation: For smaller models, DINOv2 utilizes knowledge distillation from the largest model, ViT-g, rather than training from scratch, leading to improved performance. This process involves transferring knowledge from the larger, more complex model (teacher) to the smaller model (student). The student model is trained to mimic the teacher’s output, thereby inheriting its superior capabilities. This process enhances the smaller models’ performance and makes them more efficient.
Dataset and Training
The researchers used a blend of curated and uncurated data, amassing a staggering 1.2 billion unique images to form the training set. The curated datasets were composed of multiple high-quality sources, including ImageNet-22k, the train split of ImageNet-1k, Google Landmarks, and an assortment of fine-grained datasets. These curated images provide a broad spectrum of well-defined visual data that aids the model’s learning.
On the flip side, the uncurated dataset was sourced from publicly available web-crawled data. To ensure the quality and safety of these images, multiple filtering techniques were applied, such as PCA hash deduplication to remove duplicates, NSFW filtering for content appropriateness, and face blurring to ensure privacy.
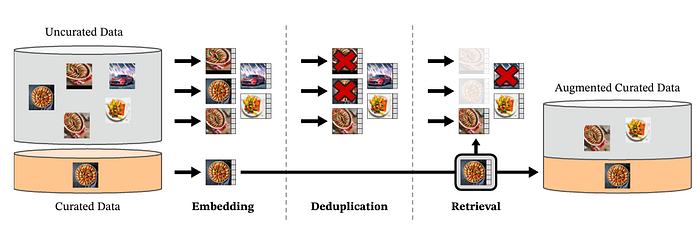
The images, both curated and uncurated, were first mapped to embeddings. Uncurated images went through an extra step of deduplication before being matched with the curated ones. The result was an augmented dataset, enriched by a self-supervised retrieval system.
The LVD-142M, a large dataset consisting of 142 million images, which the Meta AI researchers created by distributing the process across a high-performance computing cluster. This compute cluster consisted of 20 nodes equipped with 8 V100–32GB GPUs and took less than 2 days to create.
This dataset was constructed using a self-supervised image retrieval pipeline, allowing the model to extract essential features directly from the images rather than relying on text descriptions. As for the model training, they used A100–40GB GPUs and took 22k GPU hours to train the Dinov2-g model.
Let’s use one of their pre-trained models and run some inferences with it.
Start by setting up the environment:
git clone https://github.com/facebookresearch/dinov2.git
cd dinov2 && pip install -r requirements.txtimport os
import torch
import torchvision.transforms as T
import hubconf
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# Load the largest dino model
dino = hubconf.dinov2_vitg14()
dino = dino.cuda()
# Load the images
img_dir = '/path/to/your/image/folder'
image_files = os.listdir(img_dir)
images = []
for image in image_files:
img = Image.open(os.path.join(img_dir, image))
img_array = np.array(img)
images.append(img_array)
Let us see how good DINOv2 is in finding similarities in features across these 4 images.
# Preprocess & convert to tensor
transform = T.Compose([
T.Resize(560, interpolation=T.InterpolationMode.BICUBIC),
T.CenterCrop(560),
T.ToTensor(),
T.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
# Use image tensor to load in a batch of images
batch_size = 4
imgs_tensor = torch.zeros(batch_size, 3, 560, 560)
for i, img in enumerate(images):
imgs_tensor[i] = transform(img)[:3]
# Inference
with torch.no_grad():
features_dict = dino.forward_features(imgs_tensor.cuda())
features = features_dict['x_norm_patchtokens']
print(features.shape)You should see the output as torch.Size([4, 1600, 1536]), since the feature dimension for the ViTg14 model is 1536. I used only 4 images to run this inference, which is why I used a batch size of 4 and loaded everything into a single image tensor. If you have more than 4 images in your directory you need to adapt it accordingly.
# Compute PCA between the patches of the image
features = features.reshape(4*1600, 1536)
features = features.cpu()
pca = PCA(n_components=3)
pca.fit(features)
pca_features = pca.transform(features)
# Visualize the first PCA component
for i in range(4):
plt.subplot(1, 4, i+1)
plt.imshow(pca_features[i * 1600: (i+1) * 1600, 0].reshape(40, 40))
plt.show()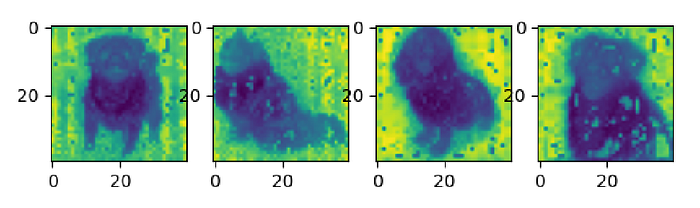
The first PCA component corresponds to the direction in the high-dimensional space along which the data varies the most. In the context of features learned by a model like DINOv2, this could correspond to the most important visual features that the model has learned to recognize. For example, it might correspond to high-level features such as the presence of certain objects, or low-level features like edges, colors, or textures.
Let us remove the background and visualize the first 3 components to see how the features match across these 4 images.
# Remove background
forground = pca_features[:, 0] < 1 #Adjust threshold accordingly
background= ~forground
# Fit PCA
pca.fit(features[forground])
features_forground = pca.transform(features[forground])
# Transform and visualize the first 3 PCA components
for i in range(3):
features_forground[:, i] = (features_forground[:, i] - features_forground[:, i].min()) / (features_forground[:, i].max() - features_forground[:, i].min())
rgb = pca_features.copy()
rgb[background] = 0
rgb[forground] = features_forground
rgb = rgb.reshape(4, 40, 40, 3)
for i in range(4):
plt.subplot(1, 4, i+1)
plt.imshow(rgb[i][..., ::-1])
plt.show()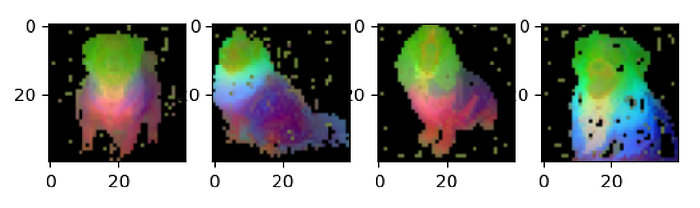
We can see clearly that the same parts of the dogs are matched across the images despite changes in the type, pose, and image style.
Indeed, generating features from their pre-trained backbones paves the way for an array of applications. This method of feature extraction lends itself to a myriad of use cases, offering a robust framework for understanding and interpreting complex, high-dimensional data.
DINOv2 Applications
- Instance Retrieval: Using a non-parametric approach, DINOv2 was able to outperform self-supervised and weakly-supervised models on various datasets such as Paris, Oxford, Met, and AmsterTime. Its ability to perform well across different task granularities is a testament to its robust feature learning capabilities.
- Semantic Segmentation: The model demonstrated strong performance on all datasets, even with simpler predictors. Surprisingly, when evaluated using a boosted recipe, it almost matched the state of the art on Pascal VOC. By freezing the backbone and tuning the weights of the adapter and head, the model achieved results close to the competitive state of the art on the ADE20k dataset.
- Depth Estimation: DINOv2 showed remarkable proficiency in monocular depth estimation tasks, surpassing both self-supervised and weakly supervised models. Its ability to generalize well out-of-domain was highlighted in the SUN-RGBd dataset, where a module trained on indoor scenes from NYUd generalized impressively to outdoor scenes.

Try out the DINOv2 demo.
Conclusion
DINOv2’s impressive capabilities and versatile applicability signal a bright future for the realm of self-supervised learning. Its performance on various tasks, be it semantic segmentation or depth estimation, signifies a significant leap in the field of computer vision.
As we move forward, the team plans to integrate DINOv2 as a building block in larger, more complex AI systems that could interact with large language models. The rich information that DINOv2 can provide about images will allow these complex AI systems to reason on images in a more profound way than merely describing them with a single text sentence.
By overcoming the limitations of models trained with text supervision, DINOv2 opens up new possibilities in image understanding. The journey of self-supervised learning is just beginning, and DINOv2 has set a promising stage for future developments.
I hope you found this insight valuable.

