Demystifying Consensus Algorithms and Their Implementations
A deep dive into consensus algorithms and fundamentals of distributed computing

What are consensus algorithms?
What are distributed databases?
How do Kubernetes and ZooKeeper store data in a fault-tolerant way?
These are some of the questions that we will try to answer in this article. Part A of the article will try to explain some of the common terminologies that you will hear in the current world of distributed computing. In Part B, we will explore the basic concepts of consensus algorithms. Part C will cover two famous consensus algorithms, Raft and Zab, and towards the end, we will explore how these algorithms power the distributed nature of ZooKeeper and Kubernetes.
These concepts might seem new, but knowledge of them will surely help you in your work or your next interview. A lot of textual content has been borrowed from the superb book written by Martin Kleppmann, titled Designing Data-Intensive Applications. Happy learning!
Part A. Terminologies Related to Distributed Databases
Single Leader, Multiple Followers (Primary-Secondary Replication)
In a single-leader replication, the leader (primary) replicates data to all of its followers (read replicas, secondary nodes). This is the most commonly used mode of replication. Whenever a new write comes to the primary node, it keeps that write to its local storage and sends the same data to all its replicas as a change stream or replication log. Each secondary then updates its own local copy of data in the same order as it was processed on the leader node.
Split-brain problem
In leader-follower situations, it could happen that two nodes both believe that they are the leader. This situation is called split-brain. It is dangerous if both leaders accept writes, and there is no process for resolving conflicts. Data is likely to be lost or corrupted.
But why would two nodes believe themselves to be the leader?
Let’s consider a situation where we have five nodes. Node A is the current leader and the rest are followers. Now suppose our Node A goes down. The rest of the nodes decide amongst themselves and promote Node B as the new leader. Now Node A comes back online. This node isn’t aware of what has happened until now and still believes itself to be the leader, which results in the system to be having two leader nodes.
Linearizability
The basic idea behind linearizability is to make a system appear as if there were only one copy of the data and that all operations in it are atomic. With this guarantee, even though there may be multiple replicas, in reality, the application does not need to worry about them.
Linearizability is important as it solves some of the very important use cases, such as lock and leader election, database uniqueness guarantees (uniqueness constraints), and cross-channel timing dependencies.
You might think that the simplest way to achieve this would be to really only use a single copy of the data. However, this approach is not fault-tolerant. If the node holding that one copy failed, the data would be lost, or at least inaccessible until the node was brought up again. Now the question arises, how to achieve linearizability in a replicated database.
- Consensus algorithms that we discuss later can implement linearizable storage safely.
- Single leader replication: Here the leader has the primary copy of the data that is used for writes, and the followers maintain backup copies of the data on other nodes. If you make reads from the leader, or from synchronously updated followers, then they have the potential to be linearizable.
Total order broadcast
Single-leader replication determines a total order of operations by choosing one node as the leader and sequencing all operations on a single CPU core on the leader. The challenge then is how to scale the system if the throughput is greater than a single leader can handle, and also how to handle failover if the leader fails. In distributed systems, this problem is known as total order broadcast or atomic broadcast.
Total order broadcast is usually described as a protocol for exchanging messages between nodes. Informally, it requires that two safety properties always be satisfied:
- Reliable delivery. No messages are lost. If a message is delivered to one node, it is delivered to all nodes.
- Totally ordered delivery. Messages are delivered to every node in the same order.
Another way of looking at total order broadcast is that it is a way of creating a log (as in a replication log) where delivering a message is like appending to the log. Since all nodes must deliver the same messages in the same order, all nodes can read the log and see the same sequence of messages.
Linearizability vs. total order broadcast
Total order broadcast is asynchronous. Messages are guaranteed to be delivered reliably in a fixed order, but there is no guarantee about when a message will be delivered (so one recipient may lag behind the others). By contrast, linearizability is a recency guarantee. A read is guaranteed to see the latest value written.
Epoch number
Almost all of the consensus algorithms internally make use of a leader. These protocols make use of epoch number and guarantee that within each epoch, the leader is unique.
1. Every time the current leader is thought to be dead, a vote is started among the nodes to elect a new leader.
2. This election is given an incremented epoch number, and thus epoch numbers are totally ordered and monotonically increasing.
3. If there is a conflict between two different leaders in two different epochs (perhaps because the previous leader actually wasn’t dead after all), then the leader with the higher epoch number prevails.
4. Before a leader is allowed to decide anything, it must collect votes from a quorum of nodes. A node votes in favour of a proposal only if it is not aware of any other leader with a higher epoch. This prevents the split-brain problem.
Part B. Fault-Tolerant Consensus

Consensus means multiple servers agreeing on the same information. Generally, we can define a consensus algorithm by three steps:
- Elect. Processes elect a leader to make decisions. The leader proposes the next valid output value.
- Vote. The non-faulty processes listen to the value being proposed by the leader, validate it, and propose it as the next valid value.
- Decide. The non-faulty processes must come to a consensus on a single correct output value.
A consensus algorithm must satisfy the following properties:
- Uniform agreement. No two nodes decide differently.
- Integrity. No node decides twice.
- Validity. If a node decides value v, then v was proposed by some node.
- Termination. Every node that does not crash eventually decides some value.
Consensus algorithms are a huge breakthrough for distributed systems. They bring concrete safety properties (agreement, integrity, and validity) to systems and they nevertheless remain fault-tolerant. They provide total order broadcast, and therefore they can also implement linearizable atomic operations in a fault-tolerant way.
Assumptions
- There is a limit to the number of failures that an algorithm can tolerate. Any consensus algorithm requires at least a majority of nodes to be functioning correctly in order to assure termination.
- Most consensus algorithms assume that there are no Byzantine faults.
Limitations
Consensus algorithms have some limitations associated with them, which restrict their usability in some situations.
- The process by which nodes vote on proposals before they are decided is a kind of synchronous replication, leading to performance issues.
- Consensus systems always require a strict majority to operate. This means, in a quorum of four nodes, you need a minimum of three nodes to operate.
- Consensus systems generally rely on timeouts to detect failed nodes. In environments with highly variable network delays, it often happens that a node falsely believes the leader to have failed due to a transient network issue. Frequent leader elections in such scenarios result in terrible performance because the system can end up spending more time choosing a leader than doing any useful work.
Part C. Consensus Algorithms and Implementations
Finally, the part we are all waiting for: understanding how everything we have read till now forms the backbone of various consensus algorithms. Then we look at the workings of various commonly used coordinations services: ZooKeeper and etcd.
Raft consensus algorithm (2014)
Raft is a single-leader algorithm. A node in the Raft algorithm can be in one of the three states:
1. Follower
2. Candidate
3. Leader
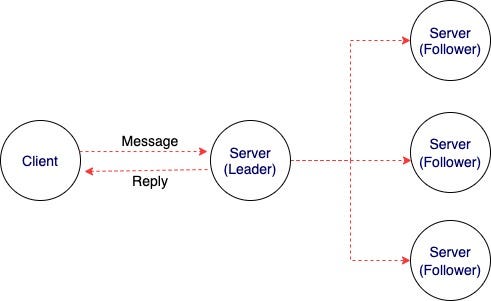
The leader keeps sending a heartbeat to all the followers at regular intervals specified by the heartbeat timeout. All messages are communicated through this heartbeat. The Raft algorithm follows the following steps.
- All nodes start in the follower state.
- If followers don’t hear from a leader, then they can become a candidate. The election timeout is the amount of time a follower waits until becoming a candidate. It is randomised to be between 150ms and 300ms.
- The candidate then starts a new election term. It votes for itself and sends out request vote messages to other nodes. Nodes reply with their vote.
- The candidate becomes the leader if it gets votes from a majority of nodes. This process is called leader election. All changes go through the leader, as shown in the figure above.
- During a leader election, the request vote also contains information about the candidate’s log to figure out which one is the latest. If the candidate requesting the vote has less updated data than the follower from which it is requesting vote, the follower simply doesn’t vote for the said candidate.
- Each change is added as an entry in the leader’s log. The log entry is initially uncommitted.
- To commit, the leader first replicates this value to follower nodes.
- The leader waits until a majority of nodes have written the entry. After receiving the response, the entry is now committed.
- The leader then updates the followers that the value has been committed. Follower nodes then commit this value respectively.
- The cluster has now come to a consensus about the system state. This process is called log replication.
- The split-brain problem is solved because in the cluster at any moment only one node can achieve a majority. If two nodes have equal votes, then the voting happens again.
As you must have realised, this algorithm uses the concept of two-phase commit that we previously explored. First, a round of votes is initiated from a leader. After the acceptance of more than half of the votes, a commit is launched.
It is being used in a variety of systems such as etcd and Consul (Hashicorp). MongoDB’s replication is also widely influenced by the Raft algorithm
ZAB consensus algorithm (2007)
ZAB (ZooKeeper Atomic BroadCast) is a consensus protocol used in ZooKeeper. ZAB is a dedicated protocol for ZooKeeper and hence its usage is limited to ZooKeeper. ZAB was born in 2007 along with ZooKeeper.
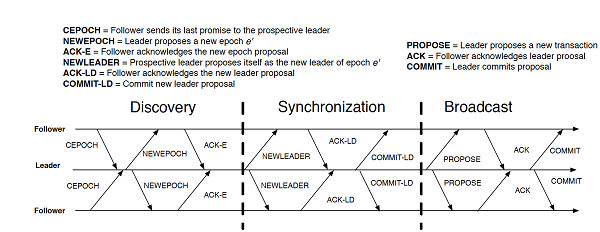
- It works on the leader-follower principle.
- The epoch number is termed as zxid.
- It enables log replication by using a two-phase commit, similar to the Raft algorithm.
- If the leader fails in the commit phase and this write operation has been committed on at least one follower, then this follower will definitely be selected as a leader because its zxid is the greatest. After being selected as the leader, this follower lets all followers commit this message.
- Unlike Raft, ZAB logs only require the append-only capability.
- It implements total order broadcast.
Consensus Algorithms — Implementations

As we can see from the above chart, the consensus algorithms we have explored until now have a wide range of implementations such ZooKeeper, etcd, and Chubby. They are indirectly used to solve various issues in distributed systems such as service discovery, coordination, locks, failure detection, and master election.
etcd (Raft)
The official website defines it as
“a strongly consistent, distributed key-value store that provides a reliable way to store data that needs to be accessed by a distributed system or cluster of machines. It gracefully handles leader elections during network partitions and can tolerate machine failure, even in the leader node. Communication between etcd machines is handled via the Raft consensus algorithm.”
Let us now take a look at some of the popular tools/software where it is being used.
Kubernetes
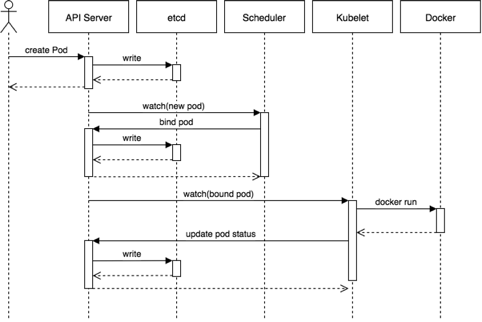
etcd is used as the back end for service discovery and stores all the clusters state and configurations, essentially as its database.
It uses etcd’s watch functionality to monitor changes to either of these two things. If they diverge, Kubernetes makes changes to reconcile the actual state and the desired state.
Anything you might read from a kubectl get xyz command is stored in etcd.
Any change you make via kubectl create will cause an entry in etcd to be updated.
Any node crashing or process dying causes values in etcd to be changed.
ZooKeeper (Zab)
The official website defines it as
“a centralised service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.”
ZooKeeper is itself a technical marvel, so we won’t be going into complete in-depth details of it.
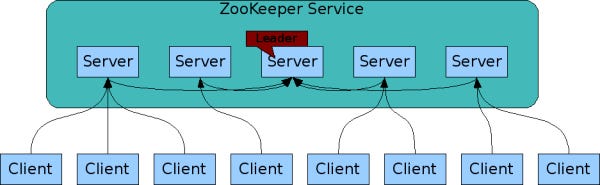
- ZooKeeper maintains cluster configuration info which is shared across all the nodes in the cluster.
- It can be used for solving distributed synchronization problems in the cluster by using locks, queues, etc.
- ZooKeeper also helps in group service with the selection of a primary in the cluster (the leader election process).
- Provides change notification capabilities. Clients can find out when another client joins the cluster (based on the value it writes to ZooKeeper) or if another client fails.
- It works in two modes: replicated mode (leader-follower) and standalone mode (single ZooKeeper server).
As an application developer, you will rarely need to use ZooKeeper directly because it is actually not well suited as a general-purpose database. It is more likely that you will end up relying on it indirectly via some other project. For example, HBase, Hadoop YARN, OpenStack Nova, Akka, and Kafka all rely on ZooKeeper running in the background.
Explore more at https://dzone.com/articles/an-introduction-to-zookeeper-1
Kafka
“Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.” — Apache Kafka website
Why is ZooKeeper necessary for Apache Kafka?
- Controller election: The controller is one of the most important broking entities in a Kafka ecosystem, and it also has the responsibility to maintain the leader-follower relationship across all the partitions.
- Configuration of topics: It includes the configuration regarding all the topics, including the list of existing topics, like the number of partitions for each topic, the location of all the replicas, etc.
- Access control lists: Access control lists or ACLs for all the topics are also maintained within ZooKeeper.
- Membership of the cluster: ZooKeeper also maintains a list of all the brokers that are functioning at any given moment and are a part of the cluster.
However, Kafka is soon planning to remove the dependency on ZooKeeper in order to simplify its architecture. Some amazing articles related to working of Kafka can be found on their blog https://www.confluent.io/blog/category/apache-kafka
That's all from my side, folks. I hope this article made sense to you. Please feel free to give your feedback. Check more such articles at — https://www.aboutall.tech/
References
- Designing Data-Intensive Applications (Martin Kleppmann)
- https://dzone.com/articles/a-brief-analysis-of-consensus-protocol-from-logica
- https://link.medium.com/2uXLjLHlhab
- http://thesecretlivesofdata.com/raft/
