Corrupted Hard Drive? Python to the Rescue!
The story of how I saved a year's worth of work with a simple Python script when all else failed

In today’s world of clouds and endless advanced backup solutions, storing your most precious projects on a simple external hard drive may sound a little outdated, but as I learned recently (against my will) it seems to still be musicians’ preferred choice.
My (very specific) problem
So I was in for an interesting weekend when one of my husband’s external hard drives just decided to croak. It also happened to be the one where he was storing all of his latest music projects, sound effects for his streams and something called “stems” that I’ve learned enables him to copyright his music. Not fun.
So to spare myself days of trying to comfort him over the loss of an entire year of work, I decided to dive head first and try to save as much of his data as possible — using conventional methods I researched on the Internet like the smart tech-y person that I am.
This quickly proved to be fruitless: the disk seems to be littered with random unreadable sectors that not only slow down beyond reason any kind of scanning poor Disk Drill or equivalent apps tried to do, but also any attempt of automated or manual backup was ultimately interrupted by the disk being randomly unmounted and re-mounted whenever a program hit a snag.
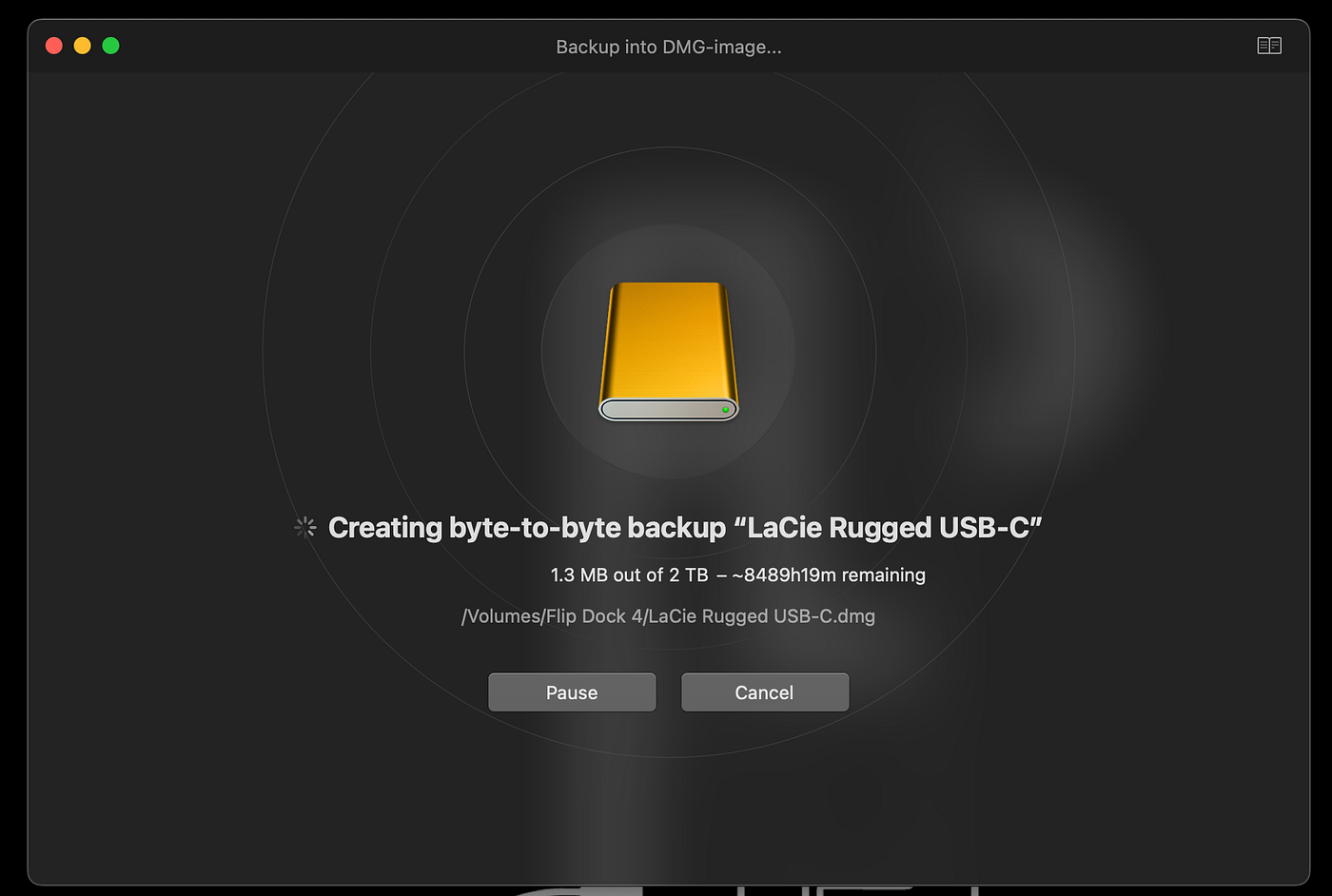
The one redeemable thing is that the disk is still detectable and (however slowly) readable. With a lot of patience, I found that copying individual files actually works, and if they’re not corrupted it happens at relatively normal speeds.
So, to save as much data as possible, one would have to go through each single file and try to copy it, then wait to see if it works or if the file raises an I/O error. HAH! But we’re talking 500GB of data here across various directories and sub-directories and sub-sub-sub-sub directories… Time to give up, right? No, because we can automate this!
The Python Solution
Because of the very specific nature of the problem, I had to write a very specific script for the file backup, but parts of this solution may be useful for a fellow sufferer when all else fails.
Here’s the roadmap for my script:
1. Reproduce the directory tree in a backup iCloud directory
- choose a subset of folders to backup
- for each found folder make a sibling in the backup location
- keep a list of individual files with full paths from each found folder (to be copied in Step 2)
- save file list for future retrieval
And the code for this step:
Depending on the number of directories and sub-directories, this may take a while on its own, but at the end of it we have a list of all of the individual files with their full paths in the hard drive.
I chose this option instead of copying each file while walking through the directories simply because of how long the backup takes and how often it can be interrupted by unforeseen errors. This way, I only compile the list once and can refer to it in the future.
Don’t forget to save the list to a file if you suspect the script will crash at some point! I’m a sucker for numpy, so this is how I did it:
A smarter option is probably to write each path to a file within the loop itself, so that’s homework for anyone unfortunate enough to have to reproduce this.
2. Copy each individual file to its sibling location on iCloud
- load file list
- initialize a flags array to keep track of progress — helps if you still don’t know what errors you’re trying to catch and uncaught ones break the loop. Also great for future analysis of how much of the disk was saved vs lost.
- try/except to copy each file, with updates to the flag array based on success or caught exceptions
I quickly noticed that not all sub-directories were created within the os.walk() loop, so I first had to hack that based on the files list:
I also decided to write some logic to handle files that take too long to copy — sometimes they won’t throw an error but will slow down the entire process, which I wanted to avoid:
And then, the actual backup loop:
You’ll notice that I keep track of several different errors and here’s why:
FileNotFoundError— raised when the disk randomly unmounts and re-mounts or a file simply can’t be found. To keep track of both scenarios, I addtime.sleep(120)which allows time for the disk to re-mount, as well as a counter (j) for the number of times a file has been tried. If it fails twice in a row, I skip it and flag it as not found (flag -1)IOError— nothing much to do here except raise a flag to indicate the file is corrupted and lost (flag -2)TimeOutException— I give each file a maximum of 5 minutes to copy. If this time limit is exceeded a timeout exception is raised and flagged (-3). Some of these files can then be revisited if they are simply too large or too important to skip.- All other exceptions are flagged with -999 to indicate they are none of the above (and can be revisited if we care to examine them in more detail).
And that’s it!
This simple Python-based approach managed to save 78% of the important data on this corrupted external drive when fancy apps failed to even recover a single byte. Time-wise, writing up the script took less than half an hour, troubleshooting it another hour or so, and the backup itself took about two days (if this sounds too long, remember the 8,000+ hours Disk Drill estimated!). Depending on the size of the backup and your patience, this can even be further optimized with multiprocessing.
And, the best part — it’s free!

I will now go offer a sacrifice to the Python gods.

