Cloud Native Patterns Illustrated: Retry Pattern
Retry pattern, transient failures, cloud-native services, backoff, jitter algorithms, robustness, and more

We’re living in an indeterministic world. It is pretty common for network connections and third-party services to be unstable in the cloud. For example, there may be packet drops in the network or rate limiters in place that can cause requests to fail.
It’s a good practice to use retry pattern while building cloud-native services, so we can design our application to handle these failures smoothly and continue functioning effectively.
Retry Pattern
The name is self-explanatory here. We retry an operation (a function call, a network request, etc.) until it succeeds or we hit the maximum number of retries.

We can abstract the retry operation as a function, which takes another function as parameter:
type Retriable func(context.Context) error
func Retry(ctx context.Context, maxRetries uint, waitFor time.Duration, f Retriable) errorHere, Retriable is a function type which takes Context as parameter and returns an error. The idea is that if the returned error is nil, then the function succeeded and we can just return from Retry. If not, it means that the function is failed to execute and we need to retry it.
We use the maxRetries param to make sure to not to call the given function infinitely. And waitFor specifies the duration to wait between consecutive retries.
Let’s implement the Retry function:
func Retry(ctx context.Context, maxRetries uint, waitFor time.Duration, f Retriable) error {
for trial := uint(0); ; trial++ {
if trial >= maxRetries {
return errors.New("maximum number of trials reached")
}
err := f(ctx)
if err == nil {
return nil
}
select {
case <-ctx.Done():
return ctx.Err()
case <-time.After(waitFor):
}
}
}The implementation is pretty straightforward, we try the function f for at most maxRetriestimes with waitFor the waiting interval.
The select-case part may be hard to understand if you’re not familiar with Go channels. Here we’re trying to receive from the channel returned from ctx.Done(), which denotes if the channel is cancelled or not. If not, the case is not applicable and we move to the next case, which is time.After(duration). This function returns a channel that will be populated duration nanoseconds after the time it is called. So basically we wait for duration nanosecs and then continue the for a loop.
Let’s use Retry with a function transiently failing for a number of calls…
package main
import (
"context"
"errors"
"log"
"time"
)
func NewRetriableTransientError() Retriable {
var count int
return func(_ context.Context) error {
if count < 3 {
count++
return errors.New("fake retriable failed!")
}
return nil
}
}
func main() {
ctx := context.Background()
f := NewRetriableTransientError()
err := Retry(ctx, 5, time.Second, f)
if err != nil {
log.Panic("Retry failed: %v", err)
}
log.Printf("OK!")
}…and run it:
$ go run main.go
2009/11/10 23:00:03 OK!Nice!
Backoff
Now let’s think about a case: We’re using this retry implementation on multiple deployments on scale to send an HTTP request to the same server. If the server has a rate limiter and our retry wait duration is relatively low, then our workers will be rate-limited for a while.
We can easily bypass this by increasing the waiting duration to a higher level. However, this will increase the overall return time of the retried function if the related service is down due to a transient error.
What if we increase the waiting time over the retries? This introduces the backoff mechanism. With backoff, we increase the waiting duration between retries using an algorithm. The most popular ones are linear backoff and exponential backoff.
In linear backoff, we calculate the waiting duration using the trial number with a linear relation. In exponential backoff, the duration is calculated by using a constant base and the exponent as the trial number. Mostly, the base is 2 in the exponential backoff, so it’s called binary exponential backoff.
It’s also a good practice to add a limit to the backoff duration. Otherwise, we can wait forever for a failing service if the maximum retry limit is high enough.
Let’s define the backoff strategy as a function in Go:
type BackoffStrategy func(trial uint) time.Duration
func NewLinearBackoff(backoff time.Duration, cap time.Duration) BackoffStrategy {
return func(trial uint) time.Duration {
d := time.Duration(backoff.Nanoseconds() * int64(trial+1))
if d > cap {
d = cap
}
return d
}
}
func NewBinaryExponentialBackoff(backoff time.Duration, cap time.Duration) BackoffStrategy {
return func(trial uint) time.Duration {
d := time.Duration(backoff.Nanoseconds() * int64(1<<trial))
if d > cap {
d = cap
}
return d
}
}Here for linear backoff we wait for backoff * trial nanoseconds, and for the exponential backoff, we wait for backoff * 2^trial nanoseconds as we’ve used 2 as the base.
We can use this backoff inside our Retry function easily:
func Retry(ctx context.Context, maxRetries uint, backoff BackoffStrategy, f Retriable) error {
for trial := uint(0); ; trial++ {
if trial >= maxRetries {
return errors.New("maximum number of trials reached")
}
err := f(ctx)
if err == nil {
return nil
}
select {
case <-ctx.Done():
return ctx.Err()
case <-time.After(backoff(trial)):
}
}
}Notice how we have used time.After() inside select-case to wait for the duration returned from backoff(trial).
Jitter
Now that we added backoff inside our retry implementation, let’s think about the case with multiple workers again. Let’s say we used binary exponential backoff, and now the rate limiting with long waiting times problem is solved. However, we will be sending synchronized requests to the service.
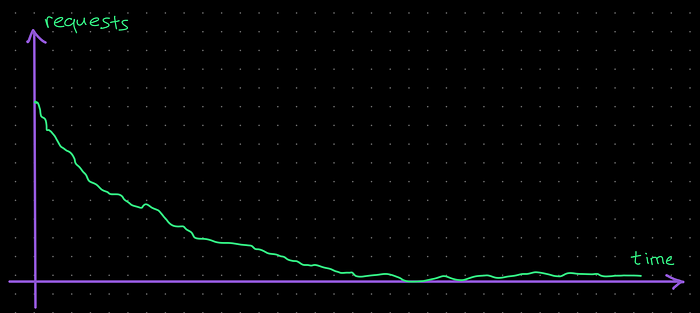
The requests/sec graph of the service (for only our requests) will look like below:
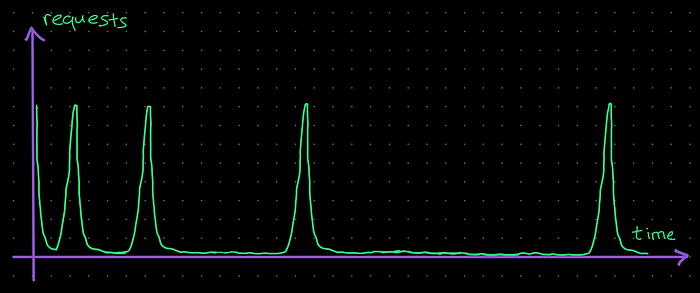
Having too many workers with the same retry schedule is not something we want, especially if we’re not trying to execute a DOS attack to the remote service. It would be better to introduce some randomness to each of the worker’s retry schedule to spread those spikes. This randomness is called “jitter”.
Let’s add jitter to NewLinearBackoff and NewBinaryExponentialBackoff:
func NewLinearBackoff(backoff time.Duration, cap time.Duration) BackoffStrategy {
return func(trial uint) time.Duration {
d := time.Duration(backoff.Nanoseconds() * int64(trial+1))
if d > cap {
return cap
}
dMax := time.Duration(backoff.Nanoseconds() * int64(trial+2))
return time.Duration(randRange(d.Nanoseconds(), dMax.Nanoseconds()))
}
}
func NewBinaryExponentialBackoff(backoff time.Duration, cap time.Duration) BackoffStrategy {
return func(trial uint) time.Duration {
d := time.Duration(backoff.Nanoseconds() * int64(1<<trial))
if d > cap {
return cap
}
dMax := time.Duration(backoff.Nanoseconds() * int64(1<<(trial+1)))
return time.Duration(randRange(d.Nanoseconds(), dMax.Nanoseconds()))
}
}
func randRange(min int64, max int64) int64 {
rand.Seed(time.Now().UnixNano())
return rand.Int63n(max-min+1) + min
}After this updater, the requests per second graph will look like this:
Conclusion
To wrap up, it’s a good practice to use the retry pattern to handle transient failures when building cloud-native services. Additionally, backoff and jitter algorithms can improve the robustness of the retry operation and prevents overwhelming the remote service.