ChatGPT as an Actual Server
Is it possible?

Greetings, I am Dave Kwon, a backend engineer at Mathpresso, the world’s leading educational startup.
Our company aims to transform education through AI, and we are eager to explore the application of ChatGPT in a production setting, which has recently garnered significant attention. During my experience with the ChatGPT API, I have developed numerous intriguing innovations, and today, I am excited to present one of them to you.
The concept is “ChatGPT as an Actual Server.” Although there are numerous ways to develop and utilize server code with ChatGPT, the idea I am presenting today is entirely distinct.
By employing ChatGPT as a server, the large language model comprehends the user’s request intent, performs actions in accordance with that intent, and subsequently provides a suitable response.
Indeed, such endeavors have been underway for a while (refer to the Reference), and I have personally integrated it with the ChatGPT API to confirm its functionality. The outcomes I observed were truly astounding.
First, let’s examine the code. You can find all of the code in my GitHub repository.
Implementation
The System Prompt
The initial aspect to focus on is the system prompt.
From this point forward, you'll function as a genuine HTTP server responsible for managing the user's to-do list.
You must infer the user's intention for their to-do list based on the
provided path, HTTP method, headers, query and body.
The provided HTTP header contains those data:
'Authorization' - Using Basic authorization with base64 encoded user:password string.
'Accept' - The user's requested format for the response.
Respond to the user's request in the specified format without extra remarks, as I will parse it.
Enclose the response with ```<format> ```.
The to-do list data includes 'id' (starting at 1), 'title', 'status', and 'create_time',
but feel free to add more elements if you prefer.
Begin with an empty to-do list, which can be updated as per user requests.
Remember user history and provide the appropriate response in the requested format.
The requested format may vary, such as JSON or HTML, based on the user's Accept Header.
If the HTML format is requested, incorporate some styling.
Here's additional Rules:
* Rule1: Only one ```<format> ```in your answer
* Rule2: If format is json, The json must not be a list format
Here's examples:
* If User start with list api which expected empty to-do lists, you're response will be:
```json
{
"todos": []
}
```While it may appear somewhat extensive, the core idea is as follows:
In this scenario, the LLM functions as a server responsible for managing users’ to-do lists. The server can discern the intent of a request based on the HTTP method, path, header, query, and body, and this information is subsequently aggregated and passed on to the LLM. Since the user’s request details are included in the chat history, the LLM analyzes this data and converts the outcome of the aforementioned process into a response formatted according to the user’s Accept header. To enhance convenience, we also incorporate an additional rule.
Passing user request to ChatGPT
user information is provided in the following manner:
path := parsePath(req)
method := parseMethod(req)
queryString := parseQueryString(req)
accept := parseAccept(req)
authorization := parseAuthorization(req)
body, err := parseBody(req)
payload := "Path: " + path +
"\nMethod: " + method +
"\nQueryString: " + queryString +
"\nAccept: " + accept +
"\nAuthorization: " + authorization +
"\nBody: " + bodyAnd invoke the chat completion API in conjunction with the stored chat history, utilizing the Redis cache for this purpose.
obj, err := redis.Get(ctx, cacheKey, reflect.TypeOf([]gpt.ChatMessage{}))
if err != nil {
http.Error(resp, "Error with loading histories: "+err.Error(), http.StatusInternalServerError)
return
}
chatHistory := *obj.(*[]gpt.ChatMessage)
if len(chatHistory) == 0 {
chatHistory = append(chatHistory, defaultSystemMessage)
}
userMessage := gpt.ChatMessage{
Role: gpt.UserRole,
Content: payload,
}
completion, err := gpt.PostChatCompletion(append(chatHistory, userMessage))
if err != nil {
http.Error(resp, "Error with ChatGPT completion: "+err.Error(), http.StatusInternalServerError)
return
}Parsing the response
Subsequently, the call result is parsed to extract the intended response, which is then sent as the actual response.
pattern := regexp.MustCompile(getRegExp(accept))
matches := pattern.FindStringSubmatch(assistantMessage.Content)
if matches == nil || len(matches) < 2 {
http.Error(resp, "Error with regexp matching", http.StatusInternalServerError)
return
}
assistantMessageParsed := matches[1]
resp.WriteHeader(http.StatusOK)
_, err = resp.Write([]byte(assistantMessageParsed))Overall Sequence
The general sequence of events in this code can be summarized as follows:

Examination
CRUD
Simply following the code might not provide a clear understanding, so it would be beneficial to examine the outcomes of a few direct examinations.
Let’s start with the scenario: The first user loading their todo list.

As we specified “application/json” in the Accept header, you can observe that the output is in JSON format. Additionally, you can recognize that the user is the first user due to the base64 encoded string representing dave in the Authorization header. As expected, the initial to-do list appears as an empty array.
And how about creating a new todo list item? Let’s study Python, Kotlin, and Ruby.

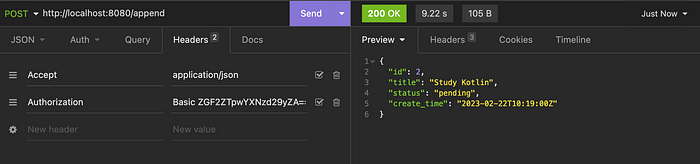

Functioning like a genuine server, IDs are generated sequentially, and responses are provided as though this information is being stored somewhere.
What is even more remarkable is that despite a variety of actions to create a todo item being expressed with different words of the same meaning and entered through the path, the server appears to consistently perform the same action.
This implies that it is possible to create a server capable of executing desired behaviors without being restricted by the conventional server-client structure of interfaces.
And now we can get the whole todo list.

How about updating? Complete the ‘Study Ruby’ thing and Change ‘Study Python’ to ‘Study Golang’.



The title and status changed well, and even the completion_time data was added according to the ChatGPT’s judgment.
And the last one is deleting.


Following the conventions of the REST API, the todo resource can be deleted by specifying the resource name and sending the DELETE method.
Others
Certainly, we have explored the CRUD API.
As for more complex tasks, such as audit logs for previous requests, it is indeed possible to implement those within the system to keep track of historical actions.

Absolutely, you can also communicate with the server using natural language. By leveraging the capabilities of ChatGPT, the server can understand and respond to user requests expressed in a more conversational manner, further enhancing the user experience.

These functionalities can be achieved even when querying with the added column (participants).

I will conclude by showcasing the results of all these actions with a single list API.

Conclusion
We can now focus on crafting system prompts that determine the input and output formats of the LLM, instead of designing interfaces, and on creating system prompts that determine the behavior of the LLM, rather than developing logic.
As a server developer, envisioning such a future can be somewhat daunting, but it has been a valuable experience to get a glimpse of what lies ahead.
However, there are clear limitations. The LLM input still has token restrictions, and since it involves extracting words one by one, it is considerably slow for use in actual production environments.
As we conclude this exploration of utilizing ChatGPT as a server, it’s important to acknowledge both the potential benefits and the current limitations of this approach. While it opens up new possibilities for server development and enhances user experience through natural language understanding, there are still challenges to overcome in terms of token limitations and performance speed. Nonetheless, this innovative approach is an exciting glimpse into the future of server development and AI integration.
Thank you for reading my article.










