Avoiding Premature Software Abstractions
How we removed 80% of our code — improving development speed and reducing errors
Software developers love abstractions. Abstractions are great and absolute key for efficient development. Writing software using solely 1’s and 0’s would be quite the chore after all. The problem comes when abstractions are introduced prematurely, i.e., before they are solving a real non-theoretical problem. Adding abstractions always comes at the cost of complexity and, when done excessively, starts slowing down the speed of development and the ability for people to easily comprehend the codebase.
All problems in computer science can be solved by another layer of abstraction… Except for the problem of too many layers of abstraction. — Butler Lampson
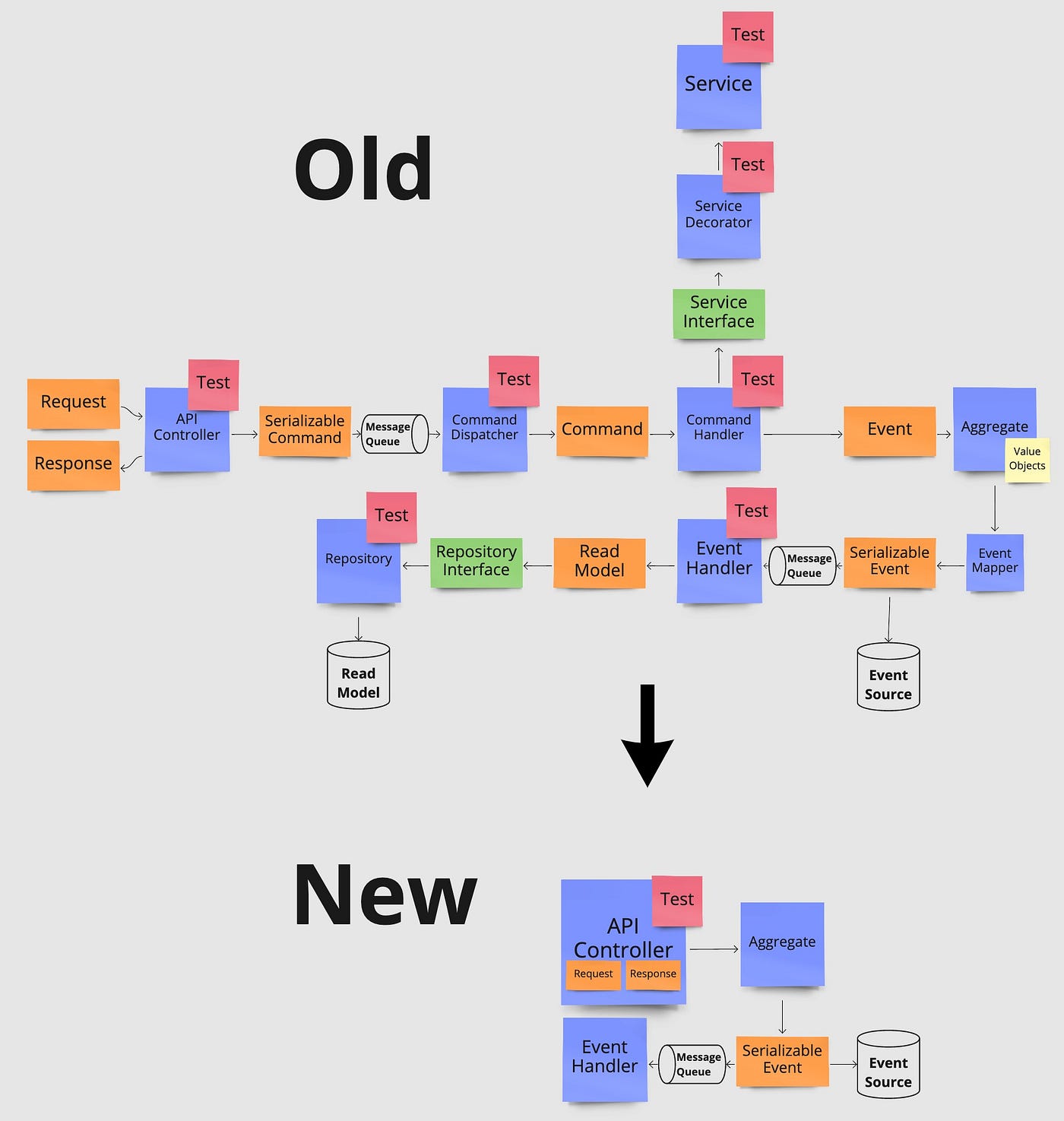
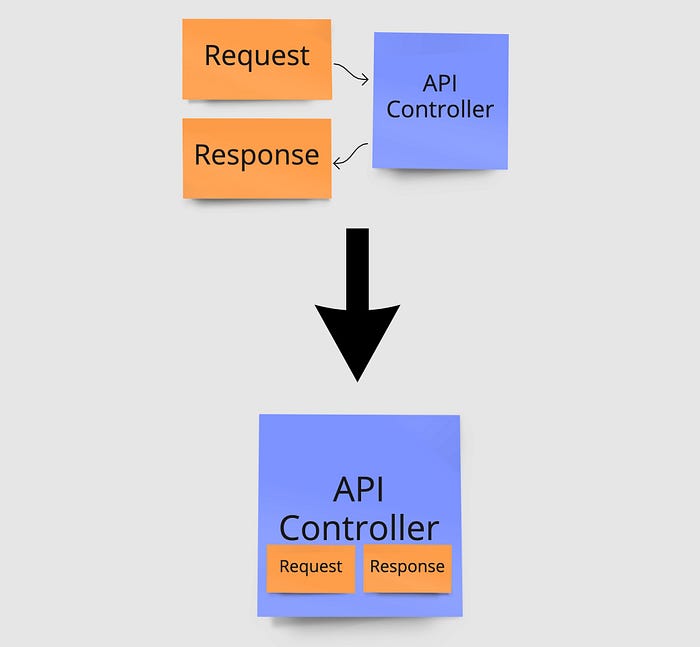
This post illustrates how avoiding common abstractions can lead to a much cleaner codebase with massively reduced complexity as well as increased readability and maintainability. The post is based on a transformation in the way I, and the rest of our team, build microservices now compared to previously. For us, this has reduced the size of a regular feature, such as a new microservice endpoint for updating or reading data, from a total of approximately 25 files down to just 5, that’s an 80% reduction with the majority of code simply having been deleted, all while simultaneously improving code readability.
The points discussed are grounded in principles like Keep it Simple, Stupid (KISS) and You Aren’t Gonna Need It (YAGNI), meaning that we want to keep abstractions to a minimum and only introduce complexity when it provides a significant and real benefit. The points will apply to most kinds of software engineering.
Common Premature Abstractions
Let’s look at some concrete cases of premature abstractions that tend to occur often in practice. These are all based on real examples found in our own codebases.
- Responsibilities are abstracted too granularly
- Design patterns are used without real benefit
- Performance is optimized prematurely
- Low coupling is introduced everywhere
Let’s take a closer look at each of these individually.
1. Responsibilities are abstracted too granularly
One root cause of a complex codebase is responsibilities being split at a way too granular level. This could be the abstraction of a database query into a dedicated repository class, an HTTP call abstracted away into a service class, or some fully internal piece of logic moved to a separate component.
This is typically done to satisfy the highly popular SOLID principle of single responsibility — each class should only have one reason to change, or, they should only have one job. If we split every tiny piece of logic into a separate class then everything has super clear-cut responsibilities, only does one job, and thus only has one reason to change. Great right? The problem is that all these small pieces are typically still tightly coupled and highly dependent on each other. If any communication between the pieces changes, often that will have a cascading effect requiring changes in many of these pieces. So they might each only have one reason to change, but that does no good if a single change often requires making changes in many of the pieces, making changing the code a pain.
Additionally, there are often no real practical advantages to having classes that change for one reason only. As a matter of fact, making changes in classes that do more than one thing often provides a lot more context for the developer which makes understanding the change and its impact on surrounding code much easier.
So when should we split responsibilities then? A common and very valid case is when the logic needs to be used in more than one place. If the exact same HTTP call or database query is needed in multiple locations in the code, duplicating the logic will often reduce the maintainability. In such a case moving it to a shared and reusable component will likely be a good idea. The key is to not do this before it is required. Another valid case is when the logic is very complex and impacts the readability of the surrounding code negatively. If a piece of the logic takes up 300 lines of code this might be the case, whereas doing it for only a few lines will probably end up just hurting readability and making navigating the code harder. Remember that splitting responsibilities always adds more structural complexity to the code.
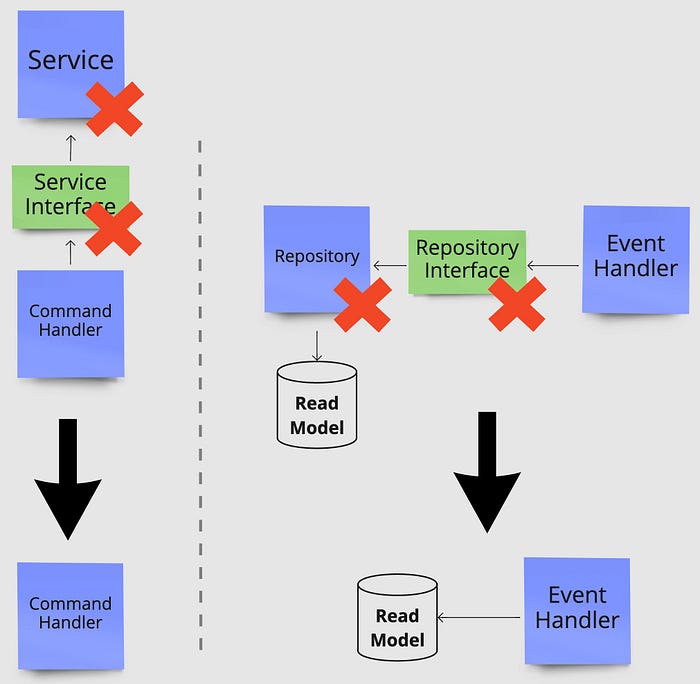
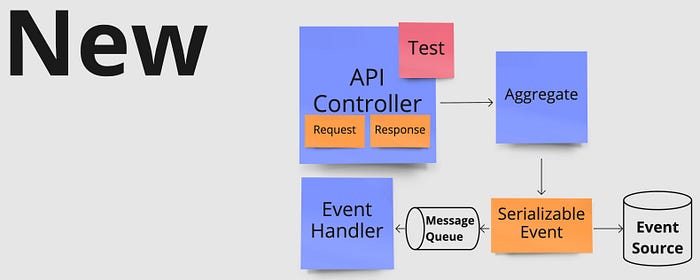
Below you see how changing our view on class responsibilities impacts the original architecture shown at the top of the post. On the left, we place logic from a service class directly into the command handler which needs the logic of the service. On the right, we move a database query in a repository class directly into the event handler that needs it.
2. Design patterns used without real benefit
Introducing various programming design patterns before their benefit is really needed is another common pitfall. Design patterns are great at solving specific problems in a codebase, and under certain circumstances can reduce overall complexity. That said, almost all of them come with the downside of added structural complexity and reduced coherence of the code.
A good example of this is the Decorator Pattern. The decorator pattern is often used for adding additional functionality on top of an existing component. This could be a component making an HTTP request, to which we want to add a retry mechanism. Without changing the original component, we can add a new component wrapping the original one with the retry logic added on top. By implementing the same interface it can be substituted for the original component directly in the code or through dependency injection.
At first, this seems like a great idea. We don’t have to change any existing code, we can test each of them in isolation and each piece is easy to understand when looked at individually. The massive downside comes from the fact that we again lose coherence. When a developer, later on, looks at the original component or the code using the component, it will not be immediately clear what will happen when the code is executed as there is more logic added on top “behind the scenes”. I have seen real cases of retries being added directly to a class only to later find out that it was already decorated with retry logic ending up in a multiplication of retries when deployed. Cases like these only really happen when it is not immediately clear how the code behaves.
Another pattern used extensively is the Command and Publish-Subscribe Pattern. Here a class, instead of handling a request directly, abstract it into a command to be handled elsewhere. An example could be an API controller mapping HTTP requests into commands, and publishing them to be handled by an appropriate handler that is subscribing to this specific command. This provides loosely coupled and clear-cut segregation between the part of the code that receives and interprets requests and the part that knows how to handle the requests. There exist legitimate use-cases of this pattern, but it is healthy to question yourself whether it, in practice, is just a useless layer of mapping. A layer of mapping that furthermore makes it harder to follow the execution path of the program as the publisher, per pub-sub definition, does not know where the command ends up being handled.
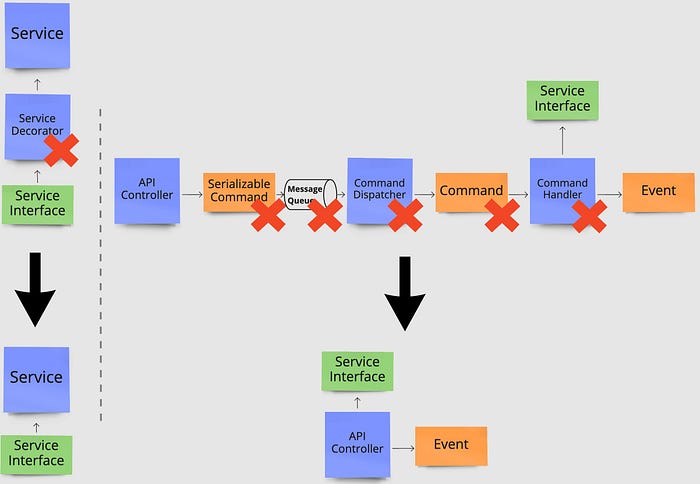
These are just a couple of examples of design patterns that are often used prematurely. The same thing can be said for almost any pattern out there. They all have downsides to them, so only bring a pattern to use when the benefits are needed and outweigh the cons. Below you again see the impact on our original architecture from removing unnecessary design patterns. On the left, we remove the Decorator pattern and on the right, the entire command flow including a publish/subscribe mechanism is removed.
3. Performance optimized prematurely
Building software that performs well is crucial, and often the most efficient solution to a problem is the cleanest and simple. At other times, though, this is not quite the case. Here the cost of optimizing must be held against the real practical benefit that we expect to gain. Costs to take into consideration would be time spent analyzing, implementing, and maintaining the optimization as well as the potential decrease in code readability from using a more complex approach to achieve efficiency. Do not sacrifice code readability for unnecessary efficiency, and remember that the cost of a developer's time often far exceeds the potential gain from saving computational resources by micro-optimizing code.
Premature optimization is the root of all evil — Donald Knuth
Optimizations can also be done at an architectural level. One example is the Command Query Responsibility Segregation (CQRS) pattern. CQRS essentially implies that you have two separate data models, one for updating data and one for reading data, splitting your application into a read and write side. This allows optimizing one side for efficient reads and the other for efficient writes as well as scaling one side more than the other in case your application is particularly read-heavy or write-heavy.
The huge downside of this pattern is the fact that a whole separate data model needs to be built and maintained resulting in a massive development overhead. If the performance is needed, this tradeoff might be just fine, but even for applications used by millions of people, I rarely see the added read or write efficiency providing any measurable benefit. A more sensible approach would be to use a single model for both reads and writes and only create optimized read models for the few individual cases where it is known for a fact the simple approach will not perform adequately.
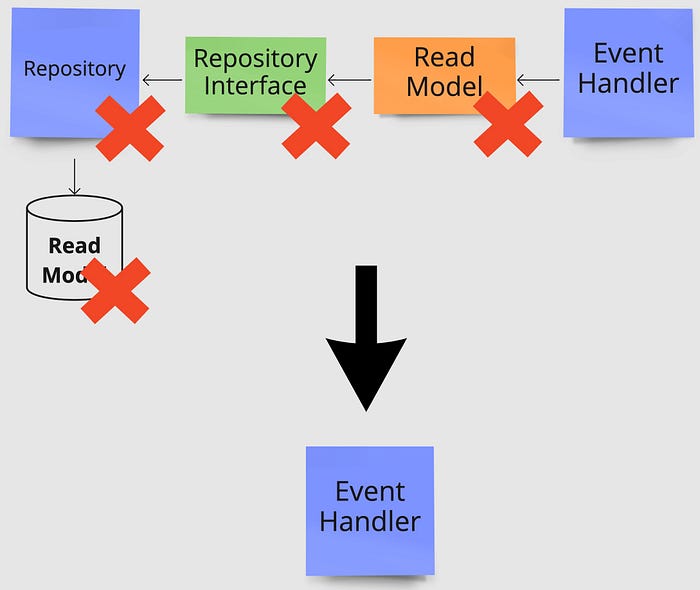
Below you see an illustration of the read side being removed from our example flow. Instead of subsequent queries reading from the dedicated Read Model table, they would read directly from the Event Source which in our example is where the data is originally written to.
4. Low coupling introduced everywhere
A codebase with low coupling is one where each part is as independent as possible from the other parts. Low coupling makes changes to one part cause only minimal impact to other parts and makes swapping out a part of the code easier as they depend on each other only in the most minimal way. Good examples of this are external libraries or modules that are used by multiple different codebases. We don’t want changes to the functionality of a library to affect the codebases using it more than what is absolutely required, and it is beneficial to be able to swap out this library for a different one in case the need arises.
A typical way of achieving low coupling is by following the Dependency Inversion and Open/Closed SOLID principles saying that entities should depend on abstractions rather than concrete implementations while being open for extension and closed for modification. In practice, this is often done by abstracting classes behind interfaces and having others depend on those interfaces rather than the concrete classes.
The problem comes when the interpretation of these principles results in low coupling being introduced everywhere, even among individual classes within the same isolated feature, such as an API endpoint of a microservice or a screen in a frontend. This can often be seen by interfaces being introduced extensively for every single class that exposes any kind of logic used by other classes inside the given feature.
An isolated feature does not need low coupling and interfaces between the elements inside it. The reason is that this low coupling comes at a cost. Low coupling, and interfaces specifically, make the code less coherent and harder to navigate as you do not directly know what concrete code will be executed. Instead, you first need to check which implementations exist of the interface and then figure out which one is actually used at runtime. Additionally, an interface is yet another file that needs to be added to your project and held up to date whenever the signature of the concrete implementation change.
Interfaces solve tons of problems, introduce them whenever they are needed to solve a real practical problem, and not any earlier than that just to achieve unnecessary low coupling. Typically, this would be when you need to be able to swap the implementation, or when creating external libraries used by others without access to modifying the library codebase. Also, if you are merely using interfaces to allow mocking in tests, seriously consider switching to a mocking library that allows mocking concrete classes to avoid the overhead.
Below this is visualized by removing two interfaces, letting the event handler and command handler have direct references to concrete implementations of the repository and service class respectively.

Bonus tip for the adventurous
If you are feeling particularly adventurous, you can go the extra mile and move separate classes into the same file. If the classes are closely related, co-dependent, and often change together, this can improve both maintainability and the context readily available when making changes. That said, be prepared to move the class to its own file if it should happen to grow significantly in size — we don’t want to end up hurting the readability.
The important thing here is that code that changes together is located as close together as possible, to make those changes seamless. It typically happens more often that a change will impact multiple classes because they are within the same feature, rather than because they are of a specific type. This is essentially favoring a Vertical Slice Architecture over the more classical Onion Architecture, as typical changes are vertical in nature rather than horizontal. Grouping classes in folders based on the feature they are related to rather than their type goes a long way here.
In our example architecture, this is seen by classes for the request and responses being placed directly in the same file as the controller who takes the request as input and provides the response as output. This is a good example of very closely related classes that often change together. When placed in the same file, you immediately get the full overview of the feature without needing to jump between files. An important note here is that we only have one endpoint per controller. Thus, each file only cares about that single feature and nothing else.
Refactor when the need arises
Now that we are no longer doing premature abstractions, it is important to consider refactoring as a natural part of making changes. If a piece of logic is suddenly needed in more than one place, then now is the time to abstract it to a separate reusable component. If we suddenly need to swap implementations, then now is the time to add an interface. Avoiding premature abstractions does not mean that abstractions will never be introduced, just that we will introduce them ad hoc when a real need arises. It is by no means an excuse for writing sloppy spaghetti code.
With all these improvements though, doing refactorings and moving pieces around should become a breeze. One pain point which is still present when refactoring often is having dedicated unit tests for every single class where all its dependencies are mocked. This type of automated testing locks down each class to behave and communicate with other classes in a very specific way as you are essentially testing the implementation of the codebase rather than the behavior. This means that whenever a class changes its unit tests, and often other tests mocking that class, needs to be updated. This is not nice when the change is a purely structural refactoring, such as moving some piece of logic to a reusable component, where the external behavior of your codebase does not change.
For this reason, we have dropped this kind of unit testing entirely and opted for a completely different approach to automated testing. This allows us to make all kinds of internal refactorings quickly without having to update a single test. But that’s a whole other topic for a separate post, which you can find here.
Applying the above principles to our original architecture results in the improved design shown below — all by removing premature abstractions.
Conclusion
We have taken a look at 4 common types of premature abstractions often seen in codebases resulting in unnecessary complexity. All have very valid reasons for being used, but the problem arises when they are introduced prematurely and provide no real benefit in practice. There exist many more examples similar to the ones listed in this post. The key takeaway is to change your mindset to always look harshly at each part of your code. Every time you consider introducing yet another abstraction really ask yourself, and your colleagues, if it will actually provide the value that you are looking for, or if it could simply be left out without any issues. Adding complexity just for theoretical reasons like “to separate concerns” and “to not depend on concrete implementations”, is simply not good enough. There should always be concrete, practical, real-world benefits every time new complexity is added.
Now, take a look at your codebases. Do they also have premature abstractions that you could remove? A good codebase makes it super quick and easy to make simple changes and refactorings. Check your recent pull requests and compare the size of the changes with what was achieved by them.
I would be happy to hear if these ideas and principles have changed the way you build software and your experience from doing so.

