Creating a GitHub Documentation Bot With LLMs
All the documentation in my repo is generated by GPT4 and I can update these docs with the click of a button.

The automation is powered by AgentHub and is able to read my GitHub project, generate new markdown docs, and publish the PR for me. Here’s how I made it and how you could build your own.
Why?
Trying to keep documentation up to date is like building a sandcastle below the tide line. You can work on perfecting it all you want but the tide of contributions is going to eventually roll in and turn it into meaningless mush. This is especially true in open-source projects with active communities.

The essence of this art lies not in its longevity, but in its fleeting existence, reminding us that just like a sunset, true beauty often resides in the impermanent. — ChatGPT
Let’s ignore the beauty of ephemeral art in this analogy and acknowledge that re-writing documentation is a pain. It can be so frustrating that many projects ignore it, letting their documentation degrade to the point of needing a complete rewrite. Even if they do allocate time for it, an engineer who knows enough to write the docs shouldn’t be spending their valuable time writing them.
I built an LLM-powered pipeline on AgentHub that generates documentation for my own repo. My sand castle rebuilds itself.
How It Works
Whenever the pipeline is ran, it ingests all the files in my GitHub repo, passes them through the LLM while asking it to generate descriptive markdown documentation and finally raises a PR using my GitHub credentials.
For context, the code I’m documenting is the python code for the AgentHub operators. These are the modular components (called operators) which act as the building blocks of AgentHub pipelines . Each operator is it’s own short python file designed to accomplish a specific task (ex: HackerNews scrapes HN posts, IngestPDF reads a pdf via and outputs the content as plain text).
This solution is built using operators and also documenting the very same operators. Hopefully, this isn’t too confusing.
Here’s my pipeline on AgentHub:
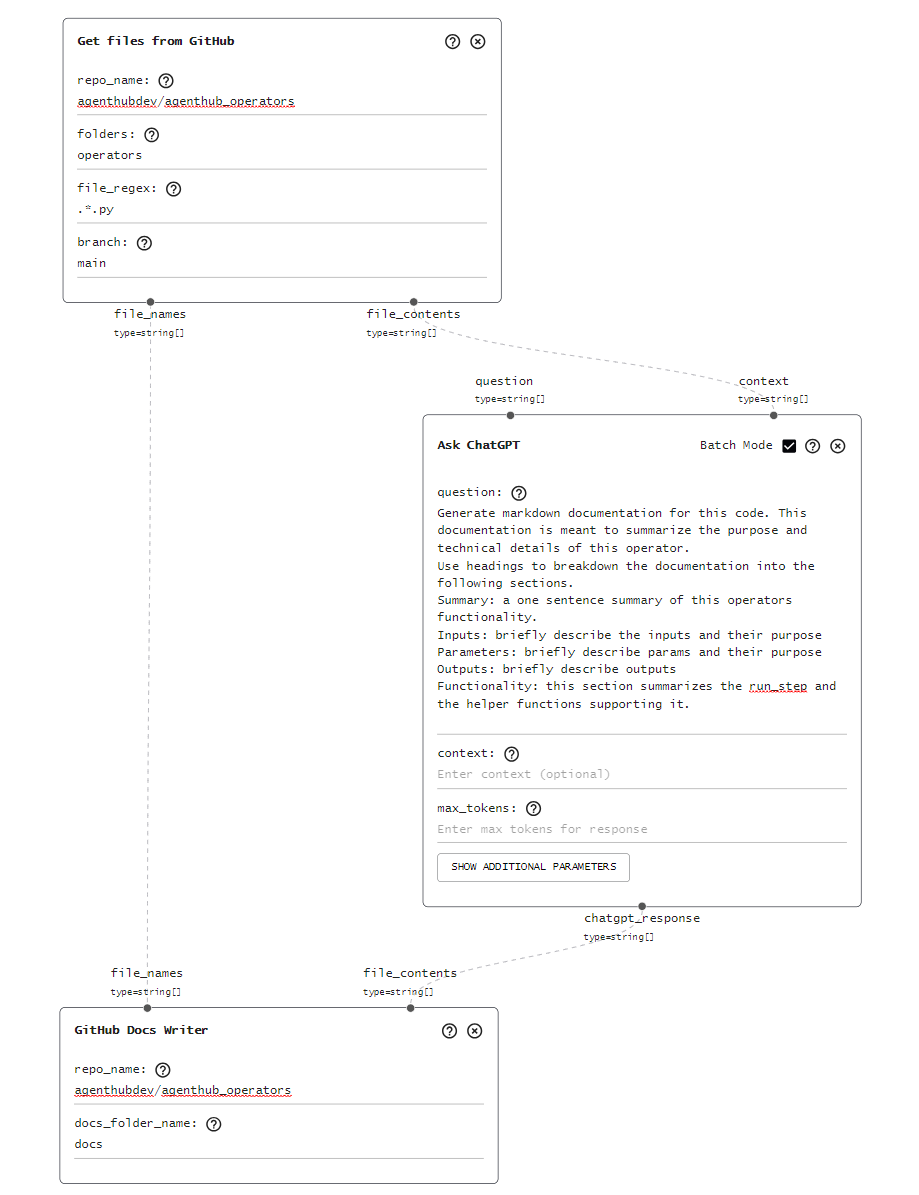
Read GitHub Files:
First I need to scrape the contents of my files from GitHub. I use the “Read files from GitHub” operator for this. It returns the file names along with the file contents in plain text.
def read_github_files(self, params, ai_context):
repo_name = params['repo_name']
folders = params.get('folders').replace(" ", "").split(',')
file_regex = params.get('file_regex')
branch = params.get('branch', 'master')
g = Github(ai_context.get_secret('github_access_token'))
repo = g.get_repo(repo_name)
file_names = []
file_contents = []
def file_matches_regex(file_path, file_regex):
if not file_regex:
return True
return re.fullmatch(file_regex, file_path)
def bfs_fetch_files(folder_path):
queue = [folder_path]
while queue:
current_folder = queue.pop(0)
contents = repo.get_contents(current_folder, ref=branch)
for item in contents:
if item.type == "file" and file_matches_regex(item.path, file_regex):
file_content = item.decoded_content.decode('utf-8')
file_names.append(item.path)
file_contents.append(file_content)
elif item.type == "dir":
queue.append(item.path)
for folder_path in folders:
bfs_fetch_files(folder_path)
ai_context.add_to_log(f"{self.declare_name()} Fetched {len(file_names)} files from GitHub repo {repo_name}:\n\r{file_names}", color='blue', save=True)
ai_context.set_output('file_names', file_names, self)
ai_context.set_output('file_contents', file_contents, self)
return TrueAsk ChatGPT:
This is the workhorse of the pipeline. I pass the contents of each file from the previous step input/context for this “Ask ChatGPT” operator. I use the following very explicit prompt to generate the markdown documentation.
Generate markdown documentation for this code. This documentation is meant to summarize the purpose and technical details of this operator.
Use headings to breakdown the documentation into the following sections.
Summary: a one sentence summary of this operators functionality.
Inputs: briefly describe the inputs and their purpose
Parameters: briefly describe params and their purpose
Outputs: briefly describe outputs
Functionality: this section summarizes the run_step and the helper functions supporting it.
def run_step(self, step, ai_context):
p = step['parameters']
question = p.get('question') or ai_context.get_input('question', self)
# We want to take context both from parameter and input.
input_context = ai_context.get_input('context', self)
parameter_context = p.get('context')
context = ''
if input_context:
context += f'[{input_context}]'
if parameter_context:
context += f'[{parameter_context}]'
if context:
question = f'Given the context: {context}, answer the question or complete the following task: {question}'
ai_response = ai_context.run_chat_completion(prompt=question)
ai_context.set_output('chatgpt_response', ai_response, self)
ai_context.add_to_log(f'Response from ChatGPT: {ai_response}', save=True)Create Pull Request:
Finally, if I had to copy the output over and raise the PR myself, this automation would be a chore. This last step takes the list of file names and file contents (markdown documentation) and creates a PR via my account.
def run_step(
self,
step,
ai_context : AiContext
):
params = step['parameters']
file_names = ai_context.get_input('file_names', self)
file_contents = ai_context.get_input('file_contents', self)
g = Github(ai_context.get_secret('github_access_token'))
repo = g.get_repo(params['repo_name'])
forked_repo = repo.create_fork()
base_branch_name = 'main'
base_branch = repo.get_branch(base_branch_name)
all_files = []
contents = repo.get_contents("")
while contents:
file_content = contents.pop(0)
if file_content.type == "dir":
contents.extend(repo.get_contents(file_content.path))
else:
file = file_content
all_files.append(str(file).replace('ContentFile(path="','').replace('")',''))
new_branch_name = f"agent_hub_{ai_context.get_run_id()}"
GitHubDocsWriter.create_branch_with_backoff(forked_repo, new_branch_name, base_branch.commit.sha)
run_url = f'https://agenthub.dev/agent?run_id={ai_context.get_run_id()}'
for file_name, file_content_string in zip(file_names, file_contents):
file_path = file_name
name = os.path.splitext(os.path.basename(file_path))[0] + '.md'
docs_file_name = params['docs_folder_name'] + '/' + name
commit_message = f"{file_path} - commit created by {run_url}"
if docs_file_name in all_files:
file = repo.get_contents(docs_file_name, ref=base_branch_name)
forked_repo.update_file(docs_file_name, commit_message, file_content_string.encode("utf-8"), file.sha, branch=new_branch_name)
else:
forked_repo.create_file(docs_file_name, commit_message, file_content_string.encode("utf-8"), branch=new_branch_name)
# Create a pull request to merge the new branch in the forked repository into the original branch
pr_title = f"PR created by {run_url}"
pr_body = f"PR created by {run_url}"
pr = repo.create_pull(
title=pr_title,
body=pr_body,
base=base_branch_name,
head=f"{forked_repo.owner.login}:{new_branch_name}"
)
ai_context.add_to_log(f"Pull request created: {pr.html_url}")
@staticmethod
def create_branch_with_backoff(forked_repo, new_branch_name, base_branch_sha, max_retries=3, initial_delay=5):
delay = initial_delay
retries = 0
while retries < max_retries:
try:
forked_repo.create_git_ref(ref=f"refs/heads/{new_branch_name}", sha=base_branch_sha)
return
except Exception as e:
if retries == max_retries - 1:
raise e
sleep_time = delay * (2 ** retries) + random.uniform(0, 0.1 * delay)
print(f"Error creating branch. Retrying in {sleep_time:.2f} seconds. Error: {e}")
time.sleep(sleep_time)
retries += 1GPT 3.5 vs GPT 4
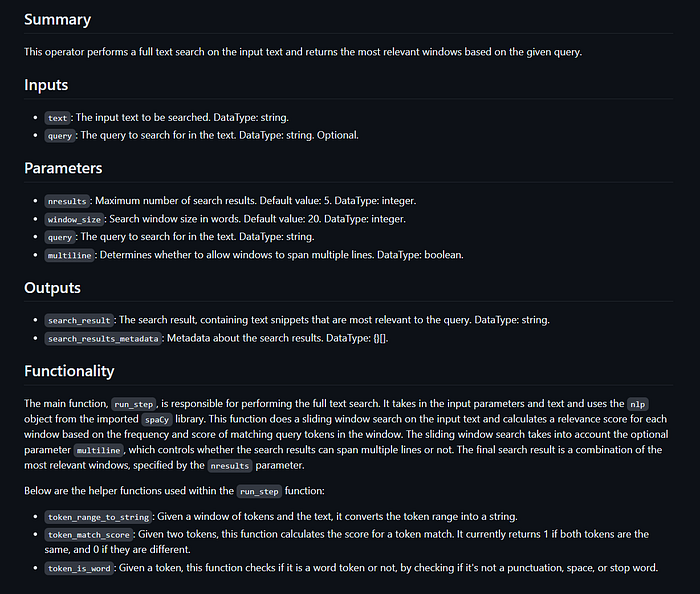
AgentHub lets you choose what model you want to run for your pipeline. I tried both GPT-3.5-turbo and GPT4 for this task. The GPT4 docs leave less to the reader’s imagination and are much closer to what I would have written.
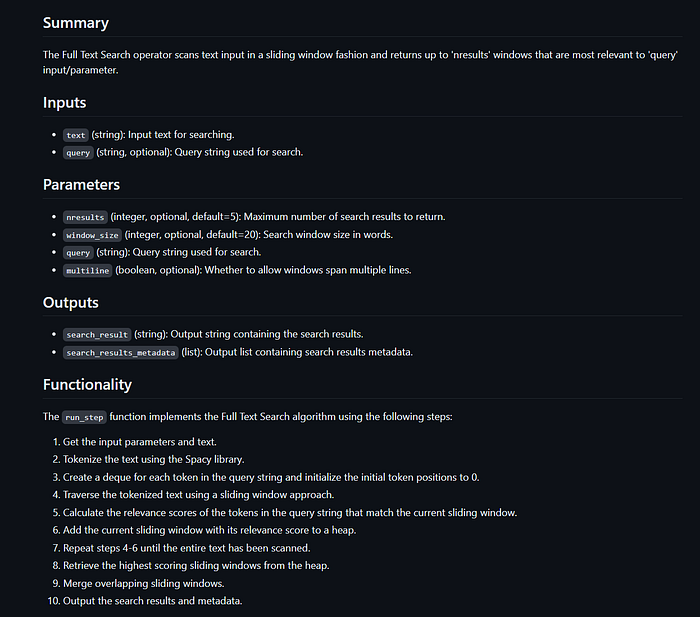
Here’s an example of the same, relatively complicated, operator being documented by each model.
GPT3.5’s attempt:
GPT4’s attempt:
Conclusion
If you have any ideas or needs for new operators I’d love to help you out!
I built AgentHub and would love to hear about any tasks you’d like automated. Feel free to join the discord, and follow the (very new) AgentHub Twitter.
I wanted to give a shoutout to Sam Snodgrass who came up with this automation and contributed the operators to AgentHub!
One last thing, if you found this interesting I’d recommend reading my last post. I automated the order desk for an importing agency using LLMs.
Thanks for reading.

