Architecting Distributed Systems: Increasing Availability Using Client Libraries
By having a library in the client application, we can handle faults consistently, increasing the perceived availability of the system
When developing APIs that are consumed either within our own company or externally, we have an option to deliver client libraries in addition to documenting and exposing the endpoints. This approach has multiple advantages for the user: easier to implement (sometimes it’s even a one-liner), easier to migrate (often just bump a dependency version), and possibly easier to set up security.
While it takes effort to develop and maintain such client libraries, there is a serious benefit they can bring to the API developers too, which is, among others, the increased perceived uptime/availability of the system. When transient faults occur, retrying the operation can often solve the problem. This logic can be built into the client libraries and have great effects.

The aim of this article is to see under which circumstances adding a client library on top of a plain API definition can result in a significant uptime improvement. First, we will go over some of the best practices in distributed systems architecture, which are necessary prerequisites to benefit from the uptime gains achieved with the help of client libraries. Then, we will go over how exactly a client library could be developed to increase the perceived uptime of our system while not costing too much to maintain. To conclude the article, I’ll mention a couple of other ways how client libraries can make the lives of API developers better.
Before beginning, let’s define availability/uptime in the context of this article. It is “a percentage of successful operations from the client’s point of view”, meaning, in the case of plain HTTP implementation, it is a percentage of requests that didn’t timeout or return a 5xx response code. In the case of a library implementation, it is a percentage of successful method calls that did not result in an exception or return a server error.
Again, we are trying to reduce the number of errors perceived as such by the client using retries, not the number of failed network requests or service restarts. Let’s begin by understanding some of the most important prerequisites for this.
🌎 Prerequisite 1: High Availability and DNS

In order to have a high rate of successful retries, we need infrastructure without a single point of failure. If the applications in one of the physical locations stop responding, and we have reasons to believe that there is a problem with that location, a highly available setup would allow the clients to start routing requests to a load balancer in a different physical location.
If the application is entirely hosted on a single physical location, client retries can still help in case of temporary network failures, but the entire application will become unavailable in the case the physical location fails.
To make use of the highly available setup, make sure that your DNS resolves in multiple IP addresses for the clients to choose from (e.g. one per load balancer). Interesting fact: most browsers actually have built-in mechanisms to try a different IP address from the DNS response in case the one they’ve been using doesn’t respond.
🗺 Prerequisite 2: Load Balancer Configuration
Load balancers play a crucial role in increasing the reliability of software systems by routing requests to available instances in the cluster. They determine which instances are available using health checks, and maintain an active list of instances that are healthy and able to serve requests.
If a load balancer didn’t receive an expected response (or any response) from an instance deemed healthy, it should mark the instance as unhealthy, and make sure that no further requests are routed to that instance until a health check has succeeded. The faster a load balancer can detect a failed instance, the fewer requests would fail and the higher the chance that subsequent retries would be routed to another healthy instance.
While the load balancer can often detect a failure (L4 and L7 load balancers work slightly differently here, I highly recommend an explanation from Hussein Nasser if you’re not familiar), it won’t retry the same request to a different instance for us — this responsibility remains within the client application.
⌛️ Prerequisite 3: Timeouts
When exposing an API for our clients, we specify the maximum service response time, which is our client timeout. This is why it’s important to design the system in a way that the total maximum timeout on the backend is less than the client timeout.
Remember: we are using client libraries to increase the perceived availability of our system by retrying failed operations. Ideally, for the client library to be able to retry once “under the hood” before giving up and informing the client application about a failure, the difference should be at least 2x, meaning the backend timeout must be less than half of the “advertised” client timeout. In other words, we need to factor in the time for at least a single retry when promising certain maximum response times.

In a simple use case where the request just gets propagated between components, the timeout can be roughly the same at each level. However, this gets trickier when a single component has more than one remote dependency. Extending the above example, if we need to call a third-party API before interacting with the database, we can’t keep the same timeout values across the components anymore, as the sum can not exceed half of the client timeout, which is 15 seconds.

Typically, the more sequential operations are involved in the use case, the shorter each individual timeout should be. I mention timeouts from a different angle in my article about API failures and explain why you should add some jitter to the timeouts in my article about random numbers.
🔁 Prerequisite 4: Idempotence
Last but not least, we want to be able to safely retry the same operation on the client-side if we didn’t get the expected result the first time. The request might have timed out but the operation might have actually succeeded, in which case retrying must return the result of the initial operation, not execute it again. In other words, we want to be able to safely retry an operation if we don’t know whether our first attempt was successful or not.
If this concept is still confusing, check out my article about the importance of idempotence to answer any remaining questions.
📚 Client Library Implementation
When it comes to the implementation of client libraries, it is important to understand the requirements first. I typically ask two questions:
- Is our integration heavy on reads or writes?
- Can we reliably persist records on the client-side before sending?
If the client applications mostly write data to our system, and these clients have access to non-volatile memory, I would encourage making use of the memory to buffer data that hasn’t been successfully received by the server yet. This is a common pattern in IoT use cases, where we don’t want to lose any telemetry if the server is temporarily unable to ingest the data sent from the devices. The locally stored records can be removed once the server has acknowledged their successful ingestion.
Then, I ask the third question: do the clients need to be offline-first? As this is not a common requirement and is notoriously hard to get right, I’m assuming that our clients have access to the internet most of the time.
Since, most of the time, the client work is not write-heavy, they don’t need offline-first support, and are stateless, I’m going to focus on this scenario in the further explanations.
According to the latest industry standards, APIs are exposed either as HTTP endpoints or using the gRPC framework. In the case of HTTP APIs, the source of truth is an OpenAPI specification file, while if you’re exposing a gRPC API, that would be the .proto file with service and message definitions. Both OpenAPI and gRPC come with ecosystems of code generators, which act as a perfect starting point for our client libraries. In fact, what we probably want to do is use the battle-tested generators shipped with OpenAPI and gRPC, and write our own plugins with the additional retry logic.
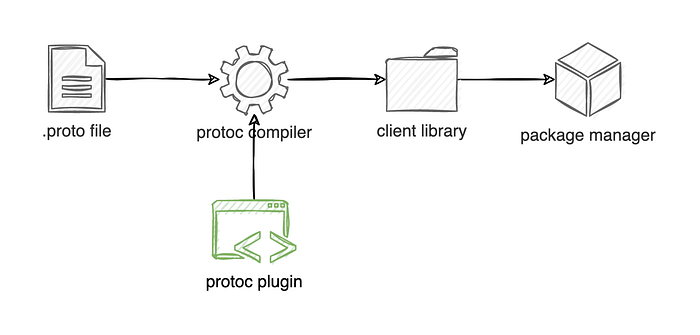
Basically, we’re taking something like this, which would be generated by the default compiler (pseudo-code):
function getWeather(city) {
return transport.callGetWeather(city); // throws Error
}And wrapping it in our own error handling logic, such as:
function getWeather(city) {
try {
return transport.callGetWeather(city);
} catch (error) {
if error.code in (500, 502, 503, 504)
// perhaps try a different load balancer
return transport.callGetWeather(city, retry = true);
else
throw error;
}
}Under the hood, the client can decide to use a different IP address from the previously executed DNS resolution, to avoid retrying the request to the same physical location.
Unfortunately, we would need to duplicate this code generation logic in the plugins for every supported programming language used by the clients. Fortunately, when done properly, this only needs to be done once for all the services. Google tends to write these plugins in the same language as the resulting library, i.e. the Java generator plugin is written in Java, allowing the language community to contribute to the project. Source.

In case some of the operations must not be automatically retried, e.g. because they are not idempotent, they can be marked as such in your API specification file. The code generator plugin could then take this information into account and wrap the code in the additional retry logic conditionally. Since we can control both the specification files and the code generator, we can have the desired flexibility depending on the specific use case.
🎁 Bonus
In addition to masking failures making the application feel more available, client libraries have other advantages, some of which I’d like to list here. If you would like me to expand on one or more of these points in a separate piece, please let me know.
- Product quality. You can provide the fastest, most reliable service ever, but if the customer makes an integration mistake and doesn’t get the advertised 99.95% availability on their end, the overall quality still deteriorates from that customer’s point of view. Having a library instead of plain API docs reduces the chance of integration errors and makes the whole product look better. Additionally, the more time the code gets executed (imagine hundreds or thousands of clients running it), the faster the bugs can be found and fixed.
- Troubleshooting. If data sharing is acceptable by the customer, error logs can be sent directly from the client library to your system, allowing you to paint the complete picture of what happened, having both the client and server logs at hand.
- Security & Migrations. I grouped these two because they mean the same thing for the customer: simplicity. Security can be non-trivial to implement, and a library can hide a large chunk of this complexity. When it comes to migrations, a simple update of the dependency can often be enough, and in case of breaking changes, a different method signature is often easier to comprehend than documentation.
- Upgrades. Zero-downtime upgrades or restarts can be hard to get right, and often developers tend to make tradeoffs in favor of minor downtime over additional complexity. By masking errors on the client-side, you might be able to make the upgrades feel like zero-downtime without the actual engineering behind them.
Thanks for reading these thoughts. You might be interested in checking out my other parts of this series about API Failures, Idempotence, and Random Numbers.
Want to Connect With the Author?Check out konarskis.com.

