Animating Regular Expressions With Python and Graphviz
Peering into the internals of a regex engine

Regular expressions have a bad reputation. It seems like whenever they’re mentioned, it invokes images of terrifying walls of text that look like absolute nonsense. For example, this is a commonly-cited regex for validating email addresses:
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])Yikes. I’m not going to pretend you’ll understand that expression by the end of this article, but I at least want to show you that it’s built on simple rules which aren’t too difficult to understand.
You may be wondering, why should you even care about how these things work in the first place? I think there are a couple of good reasons. The first is that understanding the fundamentals makes it easier to remember how to write good regular expressions.
I’ve definitely been in multiple situations where I wrote a regex and then didn’t need to look at it for months. When I eventually came back to it, I’d forgotten everything and had to relearn from scratch. By understanding the ideas behind regular expressions instead of just their syntax, you’ll be able to avoid this problem.
Also, perhaps this is the self-taught programmer chip on my shoulder, but I think it’s rewarding to take a peek into the world of theoretical computer science. Regular expressions seem to be one of the few concepts that have made their way out of theoretical computer science and into usage by everyday programmers. Understanding a regular expression engine provides a practical opportunity to engage with some high-minded concepts like finite-state automata.
I find the absolute best way to understand a concept is to visualize it. I’ve built a regex engine using Python and Graphviz that animates what actually goes on when a regex is searching through a body of text. If you want to try out your own examples, the project is publicly available on GitHub. As a demo of what’s to come, here’s an animation of the regex S+NAKE searching through the text SSSSNAKE:

Background
There’s a lot of theory underlying the concept of regular expressions, but I’m going to try to explain the bare essentials needed to implement our regex engine.
First off, we need a concrete definition for a regular expression. Wikipedia defines it as “a sequence of characters that specifies a search pattern in text.” Most characters in a regex are treated the same, but there are a few special ones that I’ll be calling meta-characters (*, +, ?, |). These have unique functions and will be discussed later.
At the core of the engine is the deterministic finite-state automaton (DFA). It sounds fancy, but in practice, it’s just a directed graph with a starting node and an ending (or accepting) node. The DFA operates by changing states based on some input. After all the input has been read, we evaluate the state of the DFA. If it’s in the accepting state, it returns True. Otherwise, it returns False.

In the DFA above, the only way to get from the starting state to the accepting state is by passing it the sequence “BAT.” This example may seem simple, but it can be expanded for arbitrarily long inputs and complicated sequences of letters. So ideally, we would like to find a method to transform a regular expression into a DFA.
Theory to the rescue! Kleene’s Theorem states that for any regular expression, there exists a DFA capable of specifying the same set of strings and vice versa. This means there is some algorithm capable of transforming the insane email regex validation I mentioned earlier into a DFA. Once it’s in that form, the computer can easily process it.
Before we get started building that algorithm, I have one more caveat to mention. It can be very computationally expensive to transform a regular expression into a DFA.
Instead, we can turn it into a nondeterministic finite-state automata (NFA). The key differences are that the NFA can be in multiple states at once and that it can move to different states without scanning an additional letter of input. This might sound a bit confusing, but I think it will become clear in the examples that follow.
Regular Expression → NFA
Here’s a quick rundown of the meta-characters that the engine supports:
- Star (
*): Matches a character zero or more times. - Plus (
+): Matches a character one or more times. - Question (
?): Matches a character zero or one time. - Period (
.): Otherwise known as the wildcard operator, it matches any character. - Parentheses (
()): Encapsulates subexpressions. - Vertical Bar (
|): Otherwise known as theoroperator, matches multiple elements within a subexpression.
If you’ve used a regular expression before, you’ll probably notice that a few meta-characters like the brackets ([]) and curly braces ({}) are missing. However, the engine still has all the functionality to implement the operations done by these missing characters.
The unsupported expression [ABC] is equivalent to the supported expression (A|B|C). Likewise, A{2, 3} is equivalent to AAA?. Adding these meta-characters is entirely possible, but it would have complicated the graphical representation, so I chose to leave them out.
I’ll demonstrate the conversion process by using the regex (A*B|AC)D as an example. First, we need to preprocess the regex a little bit by wrapping it in parentheses. Then we create nodes for each character in the regex. We also include one final blank node to symbolize the accepting state. At this point, our NFA should look like this:
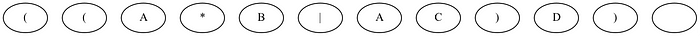
Next, we add match transition edges in black. We can think of these edges like the ones corresponding to nodes with letters in the alphabet. These edges will only be followed if the letter we scan from our text matches the letter of the node. The logic for adding match transition edges is simple: if a node does not contain a meta-character, add a match transition from that node to the next.
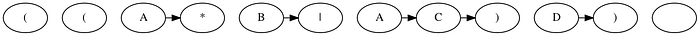
The hardest part is adding the epsilon transition edges. We can think of these edges like the ones corresponding to nodes containing meta-characters. These edges will be different for each meta-character and are also affected by the placement of parentheses. For example, any time a star operator is in the regex, it requires three separate epsilon transition edges. One to the state after it, one to the state before it, and another from the state before it back to the star.
After adding all the epsilon transition edges, the NFA is complete:

NFA Pattern Matching
Now that the NFA is fully constructed, we can run it on a body of text and observe how it transitions from state to state. We have a match if the NFA ever reaches the final, accepting state. No match is found if we finish scanning through the text and never reach the accepting state.
The basic pattern for running the NFA is as follows:
- Before scanning the first letter of the text, create a list called active states, and add the first node in the NFA to it.
- Take epsilon transitions from every node in active states to every reachable state. Put all reachable states in a list of candidate states.
- Scan the next letter in the text.
- Clear the active state list. If any state in candidate states matches the letter in the text, take its match transition to the next state and add it to the new list of active states.
- Repeat steps 2–4 until the accepting state is reached or the end of the text is reached.
The Python code for this procedure is below:
For a visual example, we will run the NFA created earlier through a body of text. We will search the text AABD to see whether we get a match. The first step is to take all possible epsilon transitions before the first letter of AABD is even scanned.

The NFA is already in 6 different candidate states at the very first step! Next, we scan to the first letter of the text.

Two nodes have a match transition from A: node 4 and node 8. The next step is to take the match transition from these nodes.

From here, the process repeats in exactly the same way. We take every available epsilon transition from our active states, scan the next letter, and take the next match transitions. The entire process is animated below:

Last Thoughts
I hope you were able to come away from this article with a better grasp of the internal operations of a regular expression engine. For additional clarification, I highly recommend these video lectures by Professor Robert Sedgewick.
I think it’s difficult to fully understand something without interacting with it, so I would encourage anyone reading this to create their own regex animations or just mess around with a regex debugger.
If you have any questions or suggestions on how to improve the visualization, I’d love to hear them. Thanks for reading!

