Accelerating CPU and GPU Heterogeneous PyTorch Workloads
…by pipelining CPU and GPU work
It is not rare that deep learning pipelines involve CPU operations that run on the results produced by a neural stage, typically run on GPUs. Be it metric computation or other custom operations not yet ported to or even unsuitable for GPUs. This heterogeneity introduces additional challenges to efficiently running such workloads.
Such a workload might be finding the semantic category with the largest single instance in a given image, where a single instance is defined to be a 2D connected component. The approach consists of two steps: to run a semantic segmentation network on the GPU and subsequently cluster the output by its connected components on the CPU. For demonstration purposes, we will assume that the clustering part has not been ported to the GPU yet, and we will use skimage.


Above are some examples of images taken from the COCO 2017 dataset that are superimposed with the corresponding semantic segmentation masks. The only detected object category in the top image is aeroplane, so that’s the one with the largest single instance. In the bottom one, the person is larger than the dog, so person is the category with the largest single instance.

This one is tricky. Although there are many people, no single one of them is larger than the motorcycle.
Now, let’s see how this problem can be solved using PyTorch and skimage.
We start by instantiating a pretrained DeepLabV3 model, as well as its corresponding transformation:
And define a function to find the category of the largest connected component in a given category map, where each cell corresponds to the category id predicted by the model for the corresponding image pixel:
We process images in two steps: First, we pass them through DeepLabV3 and resize the result to the original size. I will refer to this step as the GPU step, as the model runs on the GPU. Afterward, we copy the category map to the CPU and detect the largest connected component in. Likewise, I will be calling this step the CPU step:
Finally, we use Ignite to run our logic on the entire dataset:
This approach works. However, my testing environment results in the GPU utilization hovering around 80%, so a significant chunk of the computer power is going unused. Profiling the script with Nsight reveals the problem:
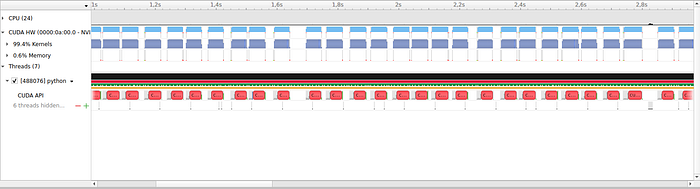
As Ignite runs the GPU and CPU steps sequentially for each item in the dataset, the GPU sits idle while the CPU is processing GPU output, evidenced by the regular breaks in the blue bar signifying GPU utilization. We can fix the problem by using multiple CUDA streams and Python threads so that the GPU can start working on the next batch as soon as it is done with the current one, in parallel with the CPU running connected component clustering on it.
To do this, we switch away from the Ignite engine and start using a custom one, which can be found in the source code I have linked at the bottom:
The rest of the code stays the same. Let’s see how the profiler timeline has changed.
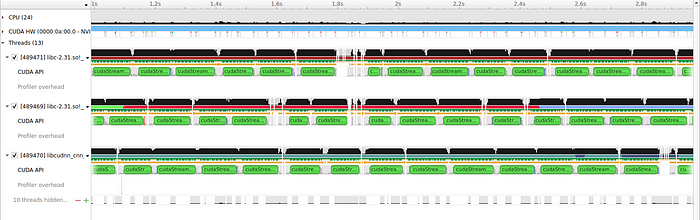
That looks much better. The GPU is now completely utilized, as the continuous blue bar shows. Notice how the script uses multiple Python threads.
Overall, on a system with an NVIDIA GeForce RTX 2080 Ti, this change increases the throughput by 45% without changing the output. One disadvantage is the increased GPU memory usage. On my setup, it increased from 2.4 GB to 4.2 GB, so this trick might not be available if you are already low on GPU memory.
You can find the full source code here.

