How We Developed and Integrated the Feature Store Into Our ML Pipeline
A feature store architecture and usage
Once upon a time, I had the opportunity to lead a project that developed a feature store. It was an amazing opportunity to learn and build something great. Now, I want to share a little about this experience, and I hope you enjoy reading it.
Before talking about feature stores, let's understand why this is important for data science projects. We can think about data science in a very simplified way as a three-step process, which will make sense for the majority of the scenarios:
- Create features based on your data that will help us observe facts.
- Group these features to create a partial view of the world that will help us model complex behaviors.
- Look at the features of a specific event through the lens of the built model (and its partial view of the world).
Yes, this is a simplified version, I agree, but we can see that feature is a central point here. We could simplify even more and say:
Data science is the art of creating and manipulating features that will translate the real-world view you’ve chosen to your model.
Maybe this is not 100% accurate, but this is more or less our day-by-day.
OK, features are important. I'm convinced. Now we should give them a proper treatment using a feature store. Let's see how.

If you are not used to feature store layers, I recommend this post. If you want to better understand the difference between a feature store and a DW, I recommend this one. Now let's explain our architecture:
Data Layer
We had two data sources to build our features:
- Delta lake: This was the company’s centralized data source, managed by a data engineering team on top of AWS S3.
- Streaming Data (Kafka): Clickstream data from the company portal.
Feature Registry
This is where we stored the metadata of built features. The feature registry was the source of truth for the feature store built on top of Cassandra.
Some of this metadata includes whether a feature is from Batch or Streaming and if it depends on other features (yes, one feature could be used as the source to another to avoid duplicate calculations).
With this, we could build, for example, a smart DAG that knows what features should be calculated and in which order.
Feature Computing
We used PySpark to compute the features (and Spark Streaming for the, guess what, streaming data).
For the batch features, we had a DAG that read feature registry data and auto-populated with the tasks necessary to compute and update the features in the proper order. So, once we registered a new feature, it was not necessary to manually update the DAG (feature registry touchdown!).
Feature Storage
We used Cassandra as our online layer and Delta Lake as the offline layer. Simple as that.
Once we'd computed new values to the features, the following was done:
- Update the online layer replacing the old value or adding a new one for a new key in the feature group. Thanks to the Cassandra Upsert feature, this was easily made.
- Insert the new values into the offline layer with the appropriate timestamp.
At this time, it is important to mention that both streaming and batch features have the same end — being stored on the online and offline layer, but updated with a higher frequency.

To support all these operations, we developed a Python lib which was responsible for (among other things):
- Registering features: to keep the feature registry updated
- Ingesting calculated features: to trigger the update of online and offline layers described above
- Getting features: for both training and inference
Features Organization and Consuming
We organized the features in our feature store in a hierarchical structure under domains and groups. As an example, since we were in the context of real estate data, we had a Product domain that had a Value group, with features like condominium_fee, rent_price, and sale_price, so to get these features later (for training or inference), we could ask them for their fully qualified name: product.value.sale_price. Simple as that!
Each feature group was a table and could exist in both online and offline layers or just the online layer (for features that don't make sense to keep history, like typology features), and each feature was a column on these tables.
To get these features, we have two specific methods in our library:
get_features: to get historic data with the possibility to filter by a periodget_online_features: to get data from the online layer. Used for inference, for example.
Since both batch and streaming features were stored together, in the consuming phase, there are no differences in consuming them. This is incredibly powerful because our models could rely on batch and streaming computed features without friction. They could always get the most updated data in the inference and training phases. Amazing!

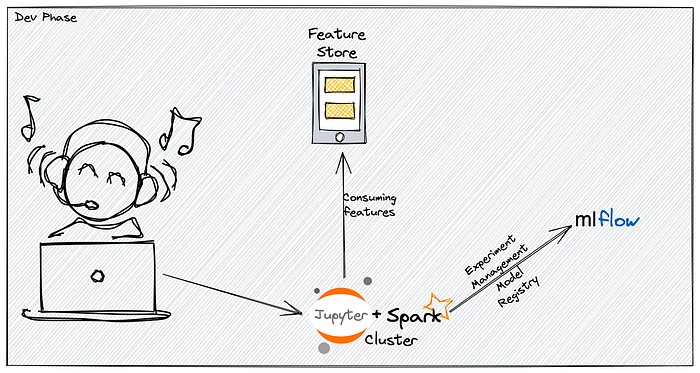
How It Integrates Into Our Ecosystem
While in the model development and training phases, the feature store integrates serving features to the data scientists, so they can concentrate on developing the model since the features were already calculated and updated.
In the inference phase, the model API gets some features from the API call, merges them with features from the feature store to generate the model prediction, and returns them to the caller.

That is pretty straightforward. What do you think about that? I hope it was helpful to you in some way.
Want to Connect?
Let's talk! You can find me on LinkedIn.
You're welcome to drop me a message!
