A Deep Dive Into Residual Neural Networks
A summarization of the paper “Deep Residual Learnings for Image Recognition”
In this blog post, I’m going to present to you the ResNet architecture and summarize its paper, “Deep Residual Learning for Image Recognition” (PDF). I’ll explain where it comes from and the ideas behind this architecture, so let’s get into it!
Introduction
At the time the ResNet paper got released (2015), people started trying to build deeper and deeper neural networks. This is because it improved the accuracy on the ImageNet competition, which is a visual object recognition competition made on a dataset with more than 14 million images.
But at a certain point, accuracies stopped getting better as the neural network got larger. That’s when ResNet came out. People knew that increasing the depth of a neural network could make it learn and generalize better, but it was also harder to train it. The problem wasn’t overfitting because the test error wasn’t going up when the training error was low. That’s why residual blocks were invented. Let’s see the idea behind it!

The Idea Behind the ResNet Architecture
The idea behind the ResNet architecture is that we should at least be able to train a deeper neural network by copying the layers of a shallow neural network (e.g. a neural network with five layers) and adding layers into it that learn the identity function (i.e. layers that don’t change the output called identity mapping). The issue is that making the layer learn the identity function is difficult because most weights are initialized around zero, or they tend toward zero with techniques such as weight decay/l2 regularization.

Residual connections
Instead of trying to make the layer learn the identity function, the idea is to make the input of the previous layer stay the same by default, and we only learn what is required to change. Therefore, each function won’t have to learn a lot and will basically be the identity function.

In figure 3, F(x) represents what is needed to change about x, which is the input. As we said earlier, weights tend to be around zero so F(x) + x just become the identity function!
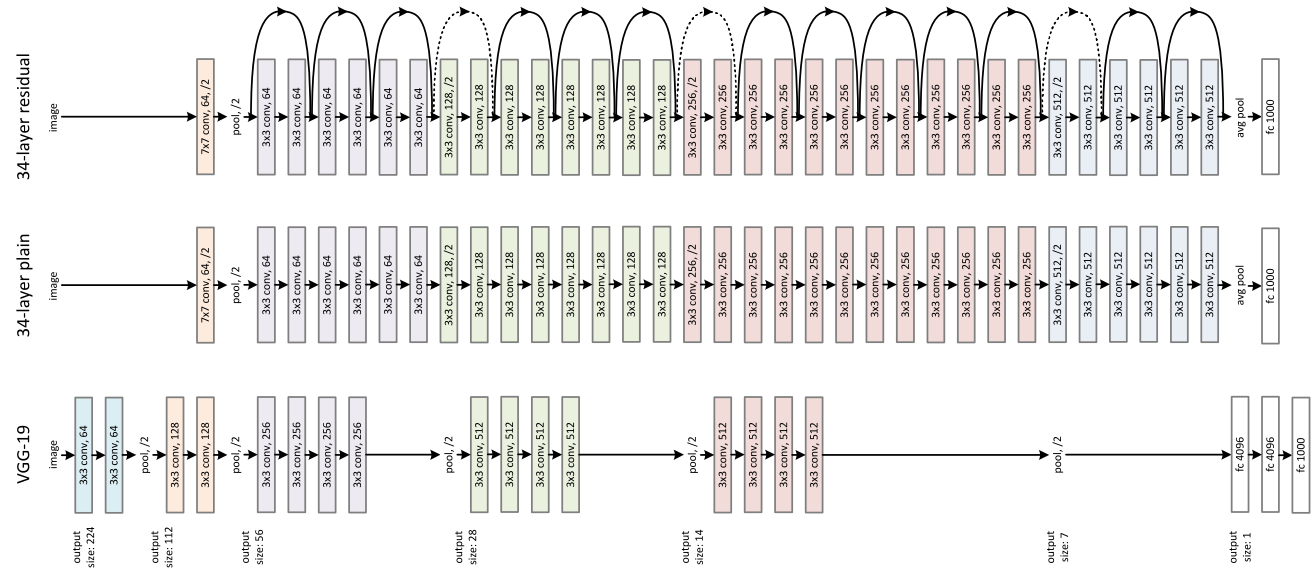
A Comparison Between the VGG-19 Model and a Residual Network
The VGG-19 model has a lot of parameters and requires a lot of computations (19.6 billion FLOPs for a forward pass!) as opposed to 3.6 billion FLOPs for a residual neural network with 34 parameter layers. The layers in the residual network are smaller than the VGG-19 model. There are also more layers, but they don’t have to learn a lot so the number of parameters is smaller. Instead of performing a pooling operation, the residual neural network also uses a stride of two. By adding layers, the simple 34-layer plain neural network actually loses performance, but this problem is solved by adding skip connections.

Adding skip connection creates another issue, after each convolution of stride 2, the output is half the size of what it was previously, and at the same time the number of filters in the next convolutions is twice as big as the previous ones.
So how do we deal with this issue and make the identity function work? Three ideas are explored to solve this issue. One is adding zero padding, the second one is to add a 1x1 convolution to those specific connections (the dotted ones), and the last one is to add a 1x1 convolution to every connection. The more popular idea is the second one as the third one wasn’t improving a lot compared to the second option and added more parameters.

As you can see in figure 5., the deeper architecture performs better than the one with 18 layers, as opposed to the graph at the left that shows a plain-18 and a plain-34 architecture.
Deeper Residual Neural Networks
As the neural networks get deeper, it becomes computationally more expensive. To fix this issue, they introduced a “bottleneck block.” It has three layers, two layers with a 1x1 convolution, and a third layer with a 3x3 convolution.
The first 1x1 layer is responsible for reducing the dimensions and the last one is responsible for restoring the dimensions, leaving the 3x3 layer with smaller input/output dimensions and reducing its complexity. Adding 1x1 layers isn’t an issue as they are much lower computationally intensive than a 3x3 layer.

As you can see in figure 7., they were able to train residual neural networks with 56 or even 110 layers, which had never been seen before this paper got released. After trying a very large number of layers, 1202, the accuracy finally decreased due to overfitting.

Conclusion
The “Deep Residual Learning for Image Recognition” paper was a big breakthrough in Deep Learning when it got released. It introduced large neural networks with 50 or even more layers and showed that it was possible to increase the accuracy on ImageNet as the neural network got deeper without having too many parameters (much less than the VGG-19 model that we talked about previously).
You can check the implementation of the ResNet architecture with TensorFlow on my GitHub! You can read the paper by clicking on this link.
Thank you for reading this post, and I hope that this summary helped you understand this paper. Stay tuned for upcoming deep learning tutorials.