6 Ways To Boost the Performance of Your Go Applications
Optimizing your Go applications

1. If your application works in Kubernetes, automatically set GOMAXPROCS to match the Linux container CPU quota
Go scheduler can have as many threads as the number of cores of the device it runs. Since our applications run on nodes in the Kubernetes environment, when our Go application starts running, it can have as many threads as the number of cores in the node. Since many different applications are running on these nodes, these nodes may contain quite a lot of cores.
By using https://github.com/uber-go/automaxprocs, the number of threads that the Go scheduler uses will be as much as the CPU limit you defined in k8s yaml.
Example:
Application CPU limit(Defined in k8s.yaml): 1 core
Node core counts: 64Normally Go scheduler will try to use 64 thread, but if we use automaxprocs it will use only one thread.
I observe quite a high-performance improvement in applications where I implement this. ~60% CPU usage, ~%30 memory usage and ~%30 response time.
2. Sort struct fields
The order of the fields used in the struct directly affects your memory usage.
For example:
type testStruct struct {
testBool1 bool // 1 byte
testFloat1 float64 // 8 bytes
testBool2 bool // 1 byte
testFloat2 float64 // 8 bytes
}You might think this struct will take up 18 bytes, but it won’t.
func main() {
a := testStruct{}
fmt.Println(unsafe.Sizeof(a)) // 32 bytes
}This is because of how memory alignment works internally in a 64-bit architecture. For more information, you can read this article.
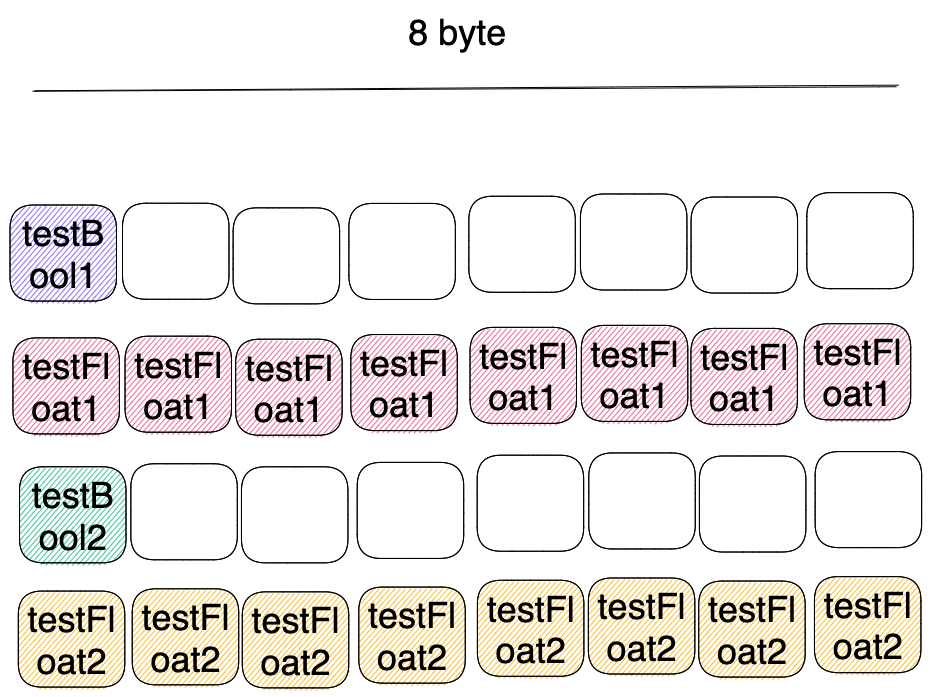
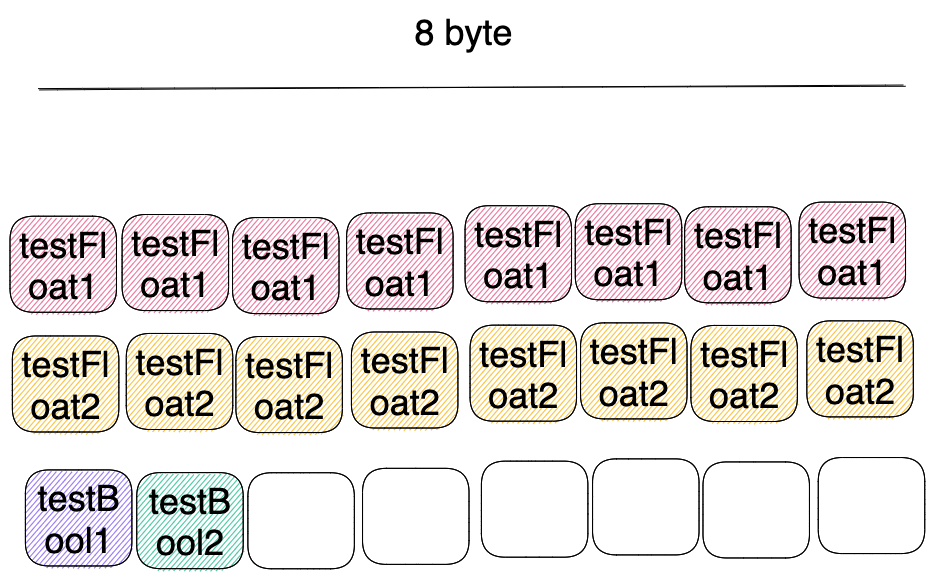
How can we decrease? We can sort fields according to memory padding.
type testStruct struct {
testFloat1 float64 // 8 bytes
testFloat2 float64 // 8 bytes
testBool1 bool // 1 byte
testBool2 bool // 1 byte
}
func main() {
a := testStruct{}
fmt.Println(unsafe.Sizeof(a)) // 24 bytes
}
We don’t always have to sort these fields manually. You can automatically sort your structs with tools such as fieldalignment.
fieldalignment -fix ./... 3. Garbage collection tune
Before Go 1.19, we only hadGOGC(runtime/debug.SetGCPercent)to configure the GC cycle; however, there were scenarios where we exceeded the memory limits. With Go 1.19, we now haveGOMEMLIMIT. GOMEMLIMIT is a new environment variable that allows users to limit the amount of memory a Go process can use. This feature provides better control over the memory usage of Go applications, preventing them from using too much memory and causing performance issues or crashes. By setting the GOMEMLIMIT variable, users can ensure that their Go programs run smoothly and efficiently without causing undue strain on the system.
It does not replace GOGC but works in conjunction with it.
You can also disable the GOGC percent config and use only GOMEMLIMIT to trigger Garbage Collection.


There is a significant decrease in the amount of garbage collection running, but you need to be careful while applying this. If you do not know the limits of your application, do not set GOGC=off.
4. Use unsafe package to string <-> byte conversion without copying
While converting between string to byte or byte to string, we are copying the variable. But internally, in Go, these two types use StringHeader and SliceHeader values commonly. We can convert between these two types without extra allocation.
// For Go 1.20 and higher
func StringToBytes(s string) []byte {
return unsafe.Slice(unsafe.StringData(s), len(s))
}
func BytesToString(b []byte) string {
return unsafe.String(unsafe.SliceData(b), len(b))
}
// For lower versions
// Check the example here
// https://github.com/bcmills/unsafeslice/blob/master/unsafeslice.go#L116Libraries such as fasthttp and fiber also use this structure internally.
Note. If your byte or string values are likely to change later, do not use this feature.
5. Use jsoniter instead of encoding/json
We often use Marshal and Unmarshal methods in our code to serialize or deserialize.
Jsoniter is a 100% compatible drop-in replacement of encoding/json.
Here’s some benchmarks:

Replacing it with encoding/json is very simple:
import "encoding/json"
json.Marshal(&data)
json.Unmarshal(input, &data)import jsoniter "github.com/json-iterator/go"
var json = jsoniter.ConfigCompatibleWithStandardLibrary
json.Marshal(&data)
json.Unmarshal(input, &data)6. Use sync.Pool to reduce heap allocations
The main concept behind object pooling is to avoid the overhead of repeated object creation and destruction, which can negatively impact performance.
Caching previously allocated but unused items help reduce the load on the garbage collector and enable their reuse later on.
Here’s an example:
type Person struct {
Name string
}
var pool = sync.Pool{
New: func() any {
fmt.Println("Creating a new instance")
return &Person{}
},
}
func main() {
person := pool.Get().(*Person)
fmt.Println("Get object from sync.Pool for the first time:", person)
person.Name = "Mehmet"
fmt.Println("Put the object back in the pool")
pool.Put(person)
fmt.Println("Get object from pool again:", pool.Get().(*Person))
fmt.Println("Get object from pool again (new one will be created):", pool.Get().(*Person))
}
//Creating a new instance
//Get object from sync.Pool for the first time: &{}
//Put the object back in the pool
//Get object from pool again: &{Mehmet}
//Creating a new instance
//Get object from pool again (new one will be created): &{}By using sync.Pool, I solved a memory leak in New Relic Go Agent. Previously It was creating a new gzip writer for every request. Instead of creating a new writer for each request, I created a pool so that the agent could use the writer in this pool and would not create new gzip writer instances for each request by using the already created ones. This would reduce the heap usage considerably, and thus the system would run fewer GC. This development approximately reduced CPU usage by ~40% and memory usage by ~22% of our applications.
I wanted to share the optimizations I actively use in Go applications. I hope it was useful.
All feedback is welcome. Thank you.

