ChatGPT, LLMs, and Foundation models — a closer look into the hype and implications for startups
We’ve all seen the craze around generative AI via e.g. ChatGPT, DALL-E, and Stable Diffusion. GPT-4 is rumored to be even more mind-blowing. There are plenty of open questions about these models, their accuracy, and even their legality from an IP perspective. And from the startup and investor perspective, there are serious concerns about whether one can build a defensible business on top of any of these types of foundation model platforms. But hype cycles come and go. Many are not aware of this, but we’ve had several AI hype cycles followed by several AI winters. Did you know that the first chatbot launched was Eliza in 1964? It was an early natural language processing computer program created from 1964 to 1966 at the MIT Artificial Intelligence Laboratory by Joseph Weizenbaum.

AI is changing the world — and the masses truly realized this via a simple user interface created by OpenAI to interact with a chatbot. ChatGPT, the popular chatbot from OpenAI, is estimated to have reached 100 million monthly active users in January, just two months after launch, making it the fastest-growing consumer application in history.
Venture capital sentiment suggests AI is in a significant moment, with many new models and startups, increased interest, and excitement over generative AI, Large Language Models (LLMs) and foundation models.
I’ve been passionate about data and AI since I started digging deeper into the world of machine learning and deep learning during my last years at Google. This was the time when Google was transforming from being a “Mobile first company” to being an “AI first company”.

When I started at Google in 2013 the company had just transitioned to become a “Mobile first company”, as mobile traffic had surpassed desktop traffic in search. Back then in 2013, Google Cloud and e.g. BigQuery were still nascent, which feels funny today. Snowflake and Databricks were founded during this time but still many years from commercial viability. AWS had just launched the first cloud data warehouse, Redshift. That much has changed in 10 years just in the world of data and the cloud.
Transformers are attention on steroids — how the Large Language Model (LLM) revolution started in 2017
Looking back almost six years to 2017, a paper at the NeurIPS scientific conference changed the course of the AI world. “Attention is All You Need” gave rise to what we today refer to as foundation models by way of the Transformer deep learning architecture.
In essence, Google’s Transformer invention, a new neural network for language understanding, brought a major advancement in “modern AI" in 2017. Stanford researchers called Transformers “foundation models” in an August 2021 paper because they see them driving a paradigm shift in AI. The “sheer scale and scope of foundation models over the last few years have stretched our imagination of what is possible,” they wrote. According to Stanford, foundational models are “models trained on broad data (generally using self-supervision at scale) that can be adapted to a wide range of downstream tasks.
It’s fair to say that the large language model (LLM) revolution started with the advent of Transformers in 2017.
A large language model with Transformer deep learning architecture works in overly simplified terms by estimating the probability of a word or sequence of words occurring within a longer sequence (sentence). See a concrete example below:
The input: The person didn’t cross the ____ because she/he was tired.
May have the following words and probabilities:
- street: 12.5%
- road: 9.2%
- bridge: 7.8%
- sea: 2.7%
- Himalayas: 0.002%
…
Transformers can be trained with a large corpus of unlabeled text (such as Wikipedia, Google Books, Reddit, etc.). They randomly mask parts of the text and try to predict the missing pieces. By doing this over and over, the Transformer tunes its parameters.
In a nutshell, a large language model is a language model trained on huge amounts of data (often e.g. text from the Internet), with lots (billions) of model parameters, and pretty much always using a Transformer-based architecture.
The biggest innovation by Google in its Transformer LLM architecture was the concept of “self-attention”. Self-attention means that each word in a sentence will “pay attention” to every other word in a sentence, identifying which words matter most to determine the context and meaning.
One could refer to Transformers as attention on steroids. Find here a great visualization of the Transformers history timeline by Damien Benveniste:
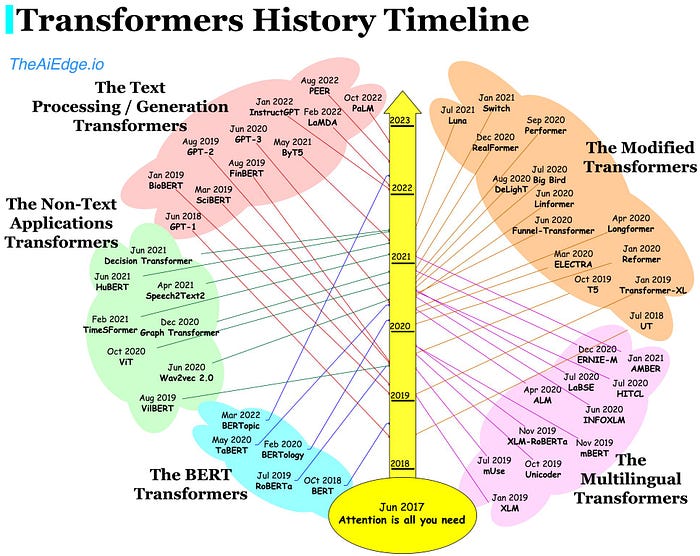
The lightning in a bottle moment for the vast majority of companies is that it is much easier to pick a pre-trained large language model utilizing the Transformer architecture(such as GPT-3 by OpenAI), which is already trained on huge amounts of text data and fine-tune it for a downstream task with company and industry-specific data — rather than training a model from scratch. Fine-tuning can be done with a much smaller set of examples than training a model from scratch making the whole process of NLP much easier.
In 2018 a very powerful LLM called BERT (which I will discuss later) had 110M parameters (parameters, simplified, are the coefficients used in the model). In 2022 — 4 years later — Google’s PaLM had 540B parameters, an increase of nearly 5000X.
But model performance ≠ number of parameters — something I will also discuss later.
The different sections of this content piece
I realize that this is a very meaty content piece. It’s divided into the following sections (click on the text to get straight to the section):
🧪 ChatGPT — a public proof of concept
🕰️ Let’s take a step back and a trip down memory lane to 2018 and 2019
😎 BERT — the original LLM gangster
⚙️ Looking under the hood of the GPT architecture powering ChatGPT
🤼 Other players on the LLM market than OpenAI (there are plenty of them)
📈 What OpenAI excelled with when launching ChatGPT
🔮 Where are we heading from an investor perspective?
🧐 There’s a lot of low-quality rumoring about GPT-4 due to the general ChatGPT hype
🚀 LLMs and foundation models — implications for startups and VCs
⚔️ Moats and defensibility for startups in the era of LLMs and foundation models
🤖 Is AI coming for developer and data jobs?
🪢 Not everything is about LLMs — the increasing data gap
📚 Recommended further readings
🗺️ Generative AI startup market maps
Note: some sections can feel incoherent without context from previous sections.
Is this time different?
“This time is different” are the four most dangerous words in investing as Sir John Templeton, the “stockpicker of the century”, famously said in Money magazine in 1999 — just before the dot-com bubble burst. However, this time it in many ways is. The emergence of the cloud a generation ago provided computing power previously not possible, enabling new areas of computer science, including Transformer models — the backbone of e.g. GPT-3.
In my opinion, the modern large language models may be one of the most impressive systems ever built. These models serve as an incredible database of information (almost everything on the public Internet is indexed) that also can do human-like reasoning and deduction. The horizon of AI’s potential is constantly shifting and becoming more noticeable.
But there are a lot of negative side effects of the hype. I’m bullish about AI and LLMs, but one cannot avoid thinking about the crypto bubble when seeing e.g. this:
As noted by Laszlo Sranger, this kind of overhype is typical in ChatGPT commentary. The same is visible via the wild rumors about the deal terms for Microsofts $10B investment in OpenAI. There’s a lot of misconception around the potential Microsoft investment and their getting a 49% stake in OpenAI after recouping their $10B investment.
The deal structure is unique, but so is also OpenAI when looking at the company's origins: OpenAI started in 2015 with $1B in pledged funding from Elon Musk (Tesla, SpaceX), Sam Altman (then-president of startup incubator Y Combinator), Peter Thiel (PayPal, Facebook investor), Reid Hoffman (LinkedIn), AWS and more.
I recommend listening to this Scott Galloway podcast episode (listen from 07:40 onwards) to understand better how the deal structure might actually look like.
ChatGPT — a public proof of concept
ChatGPT is fundamentally a probabilistic word predictor powered by the OpenAI GPT-3.5 large language model. It generates sentences.
OpenAI recently noted this in a blog post:
“We launched ChatGPT as a research preview so we could learn more about the system’s strengths and weaknesses and gather user feedback to help us improve upon its limitations”
For now, ChatGPT should be perceived predominantly as a proof of concept. The decision to execute this PoC in the public (instead of internally like Google and Facebook have done) is a purely strategic decision from OpenAI. One of the reasons OpenAI has made it public is to among others collect more feedback data from users. So free users are paying for ChatGPT in the form of providing feedback data that is utilized for reinforcement learning.
Yann LeCun (Chief AI Scientist at Facebook), has been one of the most vocal AI/ML thought leaders openly warning the public to be cautious about ChatGPT, as it often hallucinates. ChatGPT is really not a good source of information about the world. The prompt page even warns users that ChatGPT, “may occasionally generate incorrect information,” and, “may occasionally produce harmful instructions or biased content.”
More to the point, Princeton CS professor Arvind Narayanan recently said that ChatGPT is a “bulls**t generator”.
In an interview with The Markup — which is well worth reading in its entirety — Narayanan explains how ChatGPT is good at producing answers that on the surface, sound believable. However, when scratching that surface a little bit, a lot is left to be desired.
As noted by LeCun, large language models such as GPT-3.5 that ChatGPT has been built on have no physical intuition because they are trained exclusively on text. They may correctly answer questions that appeal to physical intuition if they can retrieve an answer to a similar question from their vast associative memory. But they may get the answer completely wrong.
As Laszlo Sranger highlights, the best way to think about ChatGPT as with any new technology is the following:
- Test edge cases: where are the boundaries/limits?
- Test what works, what doesn’t and how consistently.
- Brainstorm and ideate: what else can be done with it?
- Share your findings objectively.
- Don’t extrapolate, the future is exciting but unknowable.
Plenty of questions still remain open in the AI race (no pun intended). Generative AI products have many hurdles to overcome before fulfilling the wildest hopes and fears that they’ve inspired since OpenAI introduced ChatGPT in November. Both when it comes to ownership, IP, ethics, and defensibility — especially for startups building their core competitive advantage on top of foundation models. Not to mention technology itself. E.g. OpenAI and ChatGPT have suffered regular outages; the problem stems from the technical challenges that come with running any suddenly popular website.
The challenge of computing power in particular is likely to shape the development of the field, and potentially the products themselves. And the cost of computing is already influencing which entities will have influence over the foundation models and products that seem set to shape the future of the Internet.
To put things into some context — OpenAI — which had access to a 10,000 Nvidia V100 supercomputer provided by Microsoft when training GPT-3 (although it hasn’t disclosed the exact amount of GPUs they used) — decided to not retrain GPT-3 after researchers had found a mistake because it wouldn’t have been feasible. Some very gross calculations estimate a training cost of at least $4.6 million (when using the lowest GPU cloud provider), which is out of reach for most companies — that’s without including R&D costs, which could easily get the total cost up to +$30M. This is something smaller companies can’t compete with.
The data and AI/ML space have been the gift that keeps on giving, both for founders and investors. The term “megatrend” is overused, but it certainly applies here. It’s been playing out for a few decades already, and it’s likely to continue for a long time.
Let’s take a step back and a trip down memory lane to 2018 and 2019
It can either be eye-opening or embarrassing to take a trip down memory lane and look at slides that one has created for different events back in the day.

Find below a slide from a presentation I did at an event in 2019 depicting some of the AI Winters we’ve experienced from 1955 to 2012 and the previous boom times we’ve experienced e.g. 1980–1987.

The advancements within NLP are nothing particularly new — even though the buzz around ChatGPT makes it feel like it. I still remember the enormous strides that were made within NLP in 2018 and how groundbreaking it felt when Google presented in late 2018 the state of the art open sourced large language model BERT.
As mentioned prior, in 2017, Google’s Transformer, a new neural network for language understanding, brought a major advancement in “modern AI.” This invention has served as the foundation for numerous foundational models, particularly large language models, constructed by various companies such as OpenAI, Stability AI, Hugging Face, etc. Despite the recent surge of interest in AI-based software, thousands of developers have been steadily advancing the field since 2017.
Especially the advancements within NLP in 2018 and 2019 made it feel like we had reached an inflection point that would have the same wide-ranging impact on NLP as pre-trained ImageNet models (e.g AlexNet) had on computer vision & deep learning in 2012. Find below a slide I created for the same event as the one above in 2019:
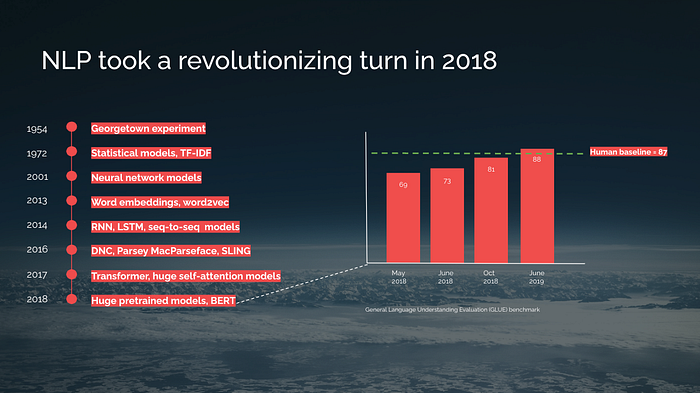
I wrote 3 years ago this article, predicting how NLP will continue its winning streak. Well, the true breakthrough moment for the masses came almost 3 years later in late 2022 when OpenAI made ChatGPT publicly available.
I remember how excited I was when Google made BERT available in 2018 and I was part of projects where we implemented it in early 2019 into workflows of some of the largest enterprises in the Nordics and Europe.
I was equally excited in 2020 when OpenAI released GPT-3 and started looking during the summer of ’20 at startups that had received early access to the GPT-3 API. I also remember well reading this blog post by Atte Honkasalo from NGP Capital about GPT-3 in the summer of ‘20.
BERT — the original LLM gangster
I might be biased here, but for me, BERT is the O.G. when it comes to Transformer based language models. BERT stands for Bidirectional Encoder Representations from Transformers and was open-sourced by Google in 2018. Google researchers developed the algorithm to improve contextual understanding of unlabeled text across a broad range of tasks by learning to predict text that might come before and after (bi-directional) other text. BERT uses an encoder that is very similar to the original encoder of the Transformer, this means we can say that BERT is a Transformer-based model. The BERT machine learning framework was specifically trained on Wikipedia (~2.5B words) and Google Books Corpus (~800M words).
These large informational datasets contributed to BERT’s deep knowledge not only of the English language but also of our world. Training on a dataset this large took some time. BERT’s training was made possible thanks to the novel Transformer architecture introduced by Google in 2017 and sped up by using Tensor Processing Units — Google’s custom circuit built specifically for large ML models. With ~64 of these TPUs, BERT training took around 4 days. In comparison, OpenAI’s GPT-3 that was launched in 2020, took according to some estimations in as “little” as 34 days.
In order to test how well language models performed compared to humans, the General Language Understanding Evaluation (GLUE) benchmark has been used, which is a collection of resources for training, evaluating, and analyzing natural language understanding systems. The progress within NLP was so fast in 2018 and 2019 that during a period of 13 months a new benchmark “SuperGlue” had to be introduced with more advanced language tasks. See below another slide that I used while presenting at an event in 2019:

Along with GPT, BERT receives credit as one of the earliest pre-trained algorithms to perform natural language processing tasks. Pre-trained models such as BERT and GPT democratized machine learning, allowing even people with less tech background to get their hands on building applications based on ML, without training a model from scratch.
These models defeated the purpose of training a model from scratch unless one was interested in investing much time and effort in building one. Instead, models like BERT could easily be fine-tuned and leveraged for the required tasks — from text similarity to question answering and sentiment analysis to name a few. However, the advent of more advanced versions like GPT-3 that came out in 2020 made the work even easier for users, where one just has to explain the task, and with a click, one can create their desired application.
But when it comes to ChatGPT — it’s not a big AI advance in itself, but it has popularized some of the AI advances of the past decade that we discussed.
Looking under the hood of the GPT architecture powering ChatGPT
Like other LLMs, ChatGPT has been trained on large and diverse data sources, such as news articles, books, websites, and social media posts, to learn the patterns and structures of language.
The underlying technology behind ChatGPT is next in the series of GPTs (Generative Pre-trained Transformers) coming from OpenAI. They are based on the revolutionary Transformer architecture initiated by Google, which we’ve briefly touched upon before in this article. In short, Transformers are based on one of the popular neural network architectures, called ‘Encode-Decoder’ networks, usually used for Language Modeling (predicting the next word) or Machine Translation.
As noted recently by Damien Benveniste, author and founder of The AiEdge Newsletter and e.g. former ML Tech Lead at Facebook, it is actually trivial to build a GPT-3 model. ~100 lines of code would do it. But training it is another story altogether and takes a lot longer than the 4 days of training BERT in 2018. GPT-1, GPT-2, and GPT-3 are actually very similar in terms of architecture and differ mostly on the data and its size used for training and the number of Transformer blocks with the number of incoming tokens.
- GPT-1 trained with BooksCorpus — is mostly a set of 12 decoder Transformer blocks put one after the other.
- GPT-2 trained with WebText (Reddit articles), 32 TPU, trained for 1 week, cost $43k — has basically the same architecture as GPT-1 but the biggest model contains 48 Transformer blocks instead. The second normalization layer is moved to the first position in a block and the last block contains an additional normalization layer. The weights are initialized slightly differently and the vocabulary size is increased.
- GPT-3 trained with WebText, Wikipedia, Books1, Books2 — has the same architecture as GPT-2 but the number of blocks increased to 96 in the bigger model and the context size (the number of consecutive tokens) increased to 2048.
While the underpinning training algorithm remains roughly the same, the recent increase in model and data size has brought about qualitatively new behaviors such as writing basic code or solving logic puzzles.
Find below a great overview of ChatGPT by Yogesh Kulkarni:
How does training an LLM like ChatGPT work? Alex Wu gave recently a good summary.
To train a ChatGPT model, there are two main stages:
- Pre-training: In this stage, we train a GPT model (decoder-only Transformer) on a large chunk of Internet data. The objective is to train a model that can predict future words given a sentence in a way that is grammatically correct and semantically meaningful similar to the Internet data. After the pre-training stage, the model can complete given sentences, but it is not capable of responding to questions.
- Fine-tuning: This stage is a 3-step process that turns the pre-trained model into a question-answering ChatGPT model:
- Collect training data (questions and answers), and fine-tune the pre-trained model on this data. The model takes a question as input and learns to generate an answer similar to the training data.
- Collect more data (question, several answers) and train a reward model to rank these answers from most relevant to least relevant.
- Use reinforcement learning (PPO optimization) to fine-tune the model so the model’s answers are more accurate.
As a reminder, it’s very important to keep in mind that ChatGPT uses Transformer architectures that are pre-trained in a self-supervised manner. Self-supervised learning is something deep learning pioneers such as Yann LeCun and Yoshua Bengio have been advocating for a long time.
GPT-3 has in a few months been around for 3 years, and while it attracted lots of developers & enabled the spectacular success of companies like Jasper.ai, its speed of adoption was nothing compared to the never-seen-something-like-this-before ChatGPT explosion (5 days to 1 million users, you’ve most likely seen the charts going viral on social media). Large Language Models such as GPT-3 are generating significant interest due to their ability to deliver impressive completions to user prompts (as covered by the New York Times).
The main component that made ChatGPT so fun to use and human-like?
As noted by Lior Sinclair in this great Twitter thread (highly recommend reading it, no matter the technical background) the first step was to adjust GPT-3.5, the LLM behind ChatGPT, for conversations. They literally had human AI trainers provide conversations in which they played both sides — the user and an AI assistant. In other words, they paid people to chit-chat. As further noted by Lior, with a model capable of generating answers similar to humans, they needed a way to tell the AI what was a good/bad answer. To solve that, they used humans (again) to rank randomly selected answers that ChatGPT was spitting out from best to worst.
As Lior summarizes, the recipe for a ChatGPT model is:
- Have a model generate a human-like answer.
- Have a model score that answer.
- Have the model learn from the score and re-adjust the answer until it gets an A+.
- Repeat a million times until accurate.
ChatGPT was trained on massive amounts of data gathered from the Internet and other sources through 2021, by using Reinforcement Learning from Human Feedback (RLHF):
- It first demonstrates data from humans and trains a supervised policy;
- The next step is to run the model and let humans manually rank (label) the quality of outputs produced by the model from best to worst, then collect those new feedback data to train a reward model;
- Then use a reinforcement learning algorithm (Proximal Policy Optimization or PPO) to optimize a policy by training a model against the reward model (the key phases of RLHF).
In summary, GPT models are a blend of a straightforward algorithm and extensive amounts of data and raw computing power. They are trained by repeatedly playing a “guess the next word” game with themselves. The model analyzes a partial sentence and predicts the following word. If correct, it adjusts its parameters to increase confidence. If incorrect, it learns from the mistake and improves its predictions in the future.
Other players on the LLM market than OpenAI (there are plenty of them)
“Microsoft partnering with OpenAI might have been one of the most successful publicity stunts ever. The current layman’s perception is that nothing can compete with ChatGPT in terms of generative AI for text.”
Above is a great quote from Damien Beneviste.
However, as Yann LeCun recently noted, in terms of underlying techniques, ChatGPT is not particularly innovative. Even Sam Altman noted recently how he was surprised that no one built ChatGPT before OpenAI:
“We had the model for ChatGPT in the API for 10 months before we made ChatGPT… I sort of thought someone (else) was gonna just build it”.
As the hype around ChatGPT and generative AI cools down a bit, we can start having a more sober dialogue around LLMs. The notion of OpenAI being alone in its type of work is very inaccurate and caused by the hype.
OpenAI is not particularly advanced compared to the other labs. It’s not only just Google and Meta, but there are half a dozen startups that basically have very similar technology to it. E.g. Anthropic, an AI startup co-founded by former employees of OpenAI, has quietly begun testing a new, ChatGPT-like AI assistant named Claude. It’s rumored that Anthropic is close to raising roughly $300 million in new funding, the latest sign of feverish excitement for a new class of AI start-ups. The deal could value Anthropic at roughly $5 billion. The start-up, which was founded in 2021, previously raised $704 million, valuing it at $4 billion.
Anthropic is just one example.
Take HuggingFace, an open-source library of pre-trained Transformers that developers can fine-tune for different applications in production (e.g., text classification & generation) — it’s one of the fastest-growing open-source projects in history.
Google Deepminds Chinchilla is rumored to perform better than the engine behind ChatGPT, GPT-3. The list goes on and on. There are also rumors that Chinese Search Giant Baidu to Launch ChatGPT-Style Bot in March.
Google just made their LaMBDA model available via a closed beta in their AI test kitchen. LaMDA (Language Model for Dialog Applications)is built by fine-tuning Transformer-based neural language models specialized for dialogue, with 135B model parameters. You can sign up for the waitlist here.
Since LaMDA was trained on human dialogue and stories rather than text, it is different from other language models and can converse informally in open-ended conversations. It’s still unconfirmed, but there are some rumors that it’s trained on data without a cut-off (ChatGPT has a dataset cut-off of 2021).
Damien Beneviste has written a great post about the direct competitors of ChatGPT in terms of generative AI for text.
Here’s a great summary by Damien on Meta’s PEER, Google’s LaMDA and Google’s PaLM — all a few selected competitors to ChatGPT:
- PEER by Meta AI — a language trained to imitate the writing process. It is trained on Wikipedia’s edit history data. It specializes in predicting edits and explaining the reasons for those edits. It is capable of citing and quoting reference documents to back up the claims it generates. It is an 11B parameters Transformer with the typical encoder-decoder architecture, and it is outperforming GPT-3 on the task it specializes in.
- LaMDA by Google AI — a language model trained for dialog applications. It is pre-trained on ~3 B documents and ~1B dialogs and fine-tuned on human-generated data to improve on quality, safety and truthfulness of the generated text. It is also fine-tuned to learn to call an external information retrievals system such as Google Search, a calculator, and a translator making it potentially a much stronger candidate to replace Google Search than ChatGPT. It is a 135B parameter decoder-only transformer.
- PaLM by Google AI — the biggest of all with 540B parameters! Breakthrough capabilities in arithmetic and common-sense reasoning. It is trained on 780 billion tokens coming from multilingual social media conversations, filtered multilingual webpages, books, GitHub repo, multilingual Wikipedia, and news.
Do you remember when Blake Lemoine was fired by Google back in 2022 when he leaked information about the LaMDA model because he thought it was sentient? Google has nothing to fear when it comes to relevance in the area of text generation research and LLMs and foundation AI models in general.
E.g. believing all the posts about Google being completely disrupted by ChatGPT and OpenAI is a bit naive, to say the least. We should stop claiming that ChatGPT will destroy Google’s search engine — if there is an organization that knows LLMs and how to put them into production, it’s Google.
Reading this summary from Google truly demonstrates their extreme dominance of both the breadth and depth they have had and are continuing to have, in areas such as NLP, computer vision, multimodal, generative models, and not the least in how to apply AI responsibly. Here’s an interesting article on how Big Tech was moving cautiously on AI — then came ChatGPT.
On the other hand, some claim that BLOOM is the most important AI model of the decade. Why? BLOOM (BigScience Language Open-science Open-access Multilingual) is unique not because it’s architecturally different than GPT-3 — it’s actually the most similar of all the above, being also a transformer-based model with 176B parameters (GPT-3 has 175B) — but because it’s the starting point of a socio-political paradigm shift in AI that will define the coming years on the field — and will break the stranglehold big tech has on the research and development of large language models (LLMs).
The main point of this section is not to analyse what model is the most important, just highlight that GPT-3 et al are far from being the only kids on the block:
Shots, shots, shots…
LLMs like GPT-3 should be able to compete with specialized models on a lot of natural language processing tasks without fine-tuning, which is referred to as zero shot learning. Here’s an interesting benchmark looking into this on four tasks: keyword extraction, sentiment analysis, language detection and translation against state-of-the-art proprietary models from different companies like Google, Amazon, Microsoft, DeepL, etc.
What do we mean by zero shot training setting?
- The few-shot setting is similar to training an ML model, where input and output pairs are provided for the model to perform on unseen inputs. However, unlike normal ML algorithms, the model does not update its weights, but instead infers based on the few examples it has seen.
- The one-shot setting is similar to the few-shot setting, but only one example is given to the model, along with the task context.
- The zero-shot setting is when only the task context is provided, and no examples or demonstrations are given. This setting can be challenging, even for humans, as understanding the task without any context can be difficult.
As GPT-3 and many of the other models are pre-trained, it means that they should be ready to be used with largely “zero-shot” training (although “few-shot” training may prove to significantly improve its performance through feedback).
What OpenAI excelled with when launching ChatGPT
So what has OpenAI truly excelled at when it comes to ChatGPT? In ways it’s a story about engineering, shipping and UX — this is the reason it has gone viral. In a nutshell, ChatGPT’s main innovation is the user interface and how easy it is to interact with it. This might seem weird as there’s nothing that innovative about ChatGPT per se and chatbots haven’t historically had a very good reputation (to say the least). But as we now know today, the combination of a user interface that is easy to get started with for any layman and the power of GPT-3/3.5 enabled ChatGPT’s meteoric rise to 1 million users in 5 days.
And don’t get me wrong, I firmly believe that great design & UX are absolute core components in any startup today and a key differentiator savvy investors look at — so a big kudos for that to OpenAI.
I often compare what ChatGPT has done to AI to what Tesla did for the EV market. Tesla was certainly not the first one to produce modern EVs and is most definitely not the only one producing cutting-edge electric cars today or tomorrow. But Tesla brought the EVs truly to the masses and pushed the whole automotive market over the chasm when it comes to EVs. The same goes for ChatGPT; it truly brought the opportunities of AI to the masses — albeit not being the first one to create state-of-the-art LLMs and most certainly not the only one as we move forward.
Where are we heading from an investor perspective?
I believe we have not yet reached the peak of this AI hype cycle that started for the masses in late 2022 via ChatGPT, as the rapid pace of innovation and the expected release of GPT-4 will likely fuel further excitement.
While some of this enthusiasm may be warranted, there will likely be a significant amount of speculation as well. I anticipate that AI investing will have a low success rate in the short to medium term, primarily because investors are struggling to understand how generative AI companies can establish sustainable competitive advantages. This in addition to a lot of VCs with no background in AI jumping on the hype bandwagon.
Many of the most successful and well-funded companies in the sector rely heavily on publicly available foundation models, and the release of ChatGPT has highlighted the risks associated with this approach. For example, prior to OpenAI’s release of ChatGPT, Jasper.ai had generated over $130 million in investment in less than two years of operation, with no clear technological advantage.
However, with the introduction of ChatGPT, Jasper and its competitors now have to compete with a more advanced, widely available, and free alternative. As a result, Jasper has had to develop its own chatbot interface. While many successful companies do not have a technological edge, they may have other forms of defensibility such as distribution advantages and network effects, and it will be crucial for companies like Jasper to identify and capitalize on these opportunities.
Overall, I will be paying close attention to how venture capitalists evaluate and invest in startups with high-potential but fragile business models, as well as what strategies and tactics will emerge as successful in this space.
When it comes to data engineering and analytics, I expect VCs to invest in AI to write SQL, the storyline is too good to pass up for many investors. Will it really work? Let’s see, I’m honestly not sure. Here’s an interesting blog post testing if ChatGPT can write better SQL than a data analyst. However as noted by Patrik Liu Tran, one really interesting use case of ChatGPT and similar types of models is to extract semi-structured data from unstructured data. Studies have shown that somewhere around 80% of the data in any organization is unstructured — a reason why companies e.g. use object stores.
As mentioned previously, the data and AI/ML space has been the gift that keeps on giving, both for founders and investors. The term “megatrend” is overused, but it does apply here. The cloud, data, and AI/ML trends have been playing out for a few decades already and will continue to do so for a long time.
A lot of use cases for enterprise AI/ML has so far gravitated around structured tabular data (where still a lot of the value lies with impressive ROI). However, the next wave is gravitating around unstructured data, like computer vision, NLP, etc. which are still nascent use cases in many enterprises. This doesn’t mean that high ROI use cases utilizing tree-based models or XGboost to do predictive AI on business-specific tabular data would disappear, however!
There’s a lot of low-quality rumoring about GPT-4 due to the general ChatGPT hype
I highly recommend reading through this Twitter thread by Matthew Barnett to learn more about this topic. Will GPT-4 have 100 trillion parameters? Most likely not as Matthew highlights via some great background digging and calculations.
It has by now been said numerous times that they are not going to increase it so much, but rather make an improvement of the actual parameters. The 100 trillion parameter rumor was even partially debunked by OpenAI CEO Sam Altman in this tweet.
It’s not going to be about the parameters — GPT-4 will most likely have a more efficient system. E.g. one of the problems with 100 trillion parameters is that it would cost an arm and a leg per inference and with current data it would most likely be overfitted and low quality.
Further, training would cost a lot too. And improvements come so fast that it makes no sense to spend that much in training such a big model.
I would be surprised if GPT-4 goes above 10 trillion parameters, it will probably be much less. Based on readings, it seems unlikely that GPT-4 will have more than 1 trillion parameters. And if it does, we should expect it to be just over 1 trillion. Most likely, GPT-4 will be comparable in size of parameters to GPT-3 (which had 175 billion parameters). I wouldn’t actually be surprised if it would be smaller than GPT-3.
Based on how long they’ve trained other models, OpenAI will probably train GPT-4 for 6–12 months. E.g. their OpenAI Five model was trained over 10 months.
GPT-3.5 which ChatGPT is built on was finished training in early 2022. Since GPT-4 could be trained for up to 12 months, and they likely need to fine-tune and test it, a good guess is that we’re looking to see it in action during the first half of 2023.
Performance doesn’t equal the number of parameters. E.g. Google Deepminds Chinchilla language model has “only” 70B parameters and is claimed to outperform GPT-3. Chinchilla is trained on 4 times more data than the previous leader in large language models, Gopher (also built by DeepMind) and according to the studies, Chinchilla is superior to e.g. GPT-3.
Moreover, Chinchilla’s smaller size makes it more cost-effective for inference and fine-tuning, enabling the use of these models in scenarios where financial and hardware limitations could have been an issue. The advantages of a smaller, better-trained model extend beyond just improved performance.
The bottom line is that current big language models are apparently “considerably undertrained” due to the blindly followed scaling hypothesis by researchers. So the focus should shift to increasing the amount of good training data in order to increase performance.
Main lesson: model performance comes once again down to *good* data to train a model on and efficient feedback loops (utilizing reinforcement learning).
LLMs and foundation models — implications for startups and VCs
What kind of startups will succeed in the upcoming era defined by LLMs and foundation models such as GPT? As noted by Andre Retterah, the generative AI stack can be split into 4 different layers:
1. Application layer: Vertical or use-case-specific products that are ready to use by customers. Lowest entry barriers. Sustainable differentiation, product excellence, and superior go-to-market execution are key.
2. Middle layer: Reduces friction to build scalable applications on top of foundation models. Least mature but provides great potential á la “shuffles for the goldrush”.
3. Foundation model layer: LLMs got trained with a dataset on infrastructure and return contextualized inferencing results if prompted. High entry barriers, and similar dynamics to the cloud market with “few take all”.
4. Infrastructure layer: Required for training and inferencing. Important for low-level model optimization. High entry barriers due to scarcity and costs of GPUs.
As biased as he may be, how does OpenAI CEO Sam Altman see this playing out?
As visible in this fireside chat with Reid Hoffman, when it comes to the foundation model layer, he feels a company that tries to build its own LLMs from the ground up will be unlikely to succeed — probably because it’ll be too cost prohibitive and unnecessary to build these models when they are available off the shelf. In today’s world, it’s akin to building your data center when AWS, GCP and Azure are already available.
The application layer is a class Altman feels will be short-lived as the API callers. These companies are using out-of-the-box GPT class of models for their applications. There is no technology moat or a superlative value creation for the consumer in a vanilla GPT call. These companies will rise and fade unless they can find a way to become the middle layer company.
What about the middle layer? Well, this is the layer Sam is most bullish about (and surprisingly plays well with OpenAI’s commercial model) and where he sees startups that will be hugely successful.
Now, what’s a “middle layer” company and what does it take to become one?
A middle-layer company has a few key ingredients
1. Unique data set
2. Powerful AI/ML and data infrastructure
3. Rare talent to train models
This kind of company will be able to take GPT class of models and improve the performance of these models for their vertical — which could be medicine, coding, marketing, law or accounting to name a few.
This framing from Evan Armstrong covers the general frameworks of the technologies behind today’s applications:
Compute powers the foundation model research companies that train their models on huge volumes of data, to deliver a pre-trained Transformer model to the builders of applications. These application builders may elect to fine-tune the model with domain-specific data to derive superior performance for specific applications that serve as access points to AI for the general population.
Further, we can see two approaches to ML algorithm/foundation model distribution: closed and open source. We are increasingly seeing algorithms be commoditized, decreasing the defensibility of closed-sourced models offered as an API.
We’ve witnessed a Cambrian explosion of text-based major AI models during the past years — both open source and private/closed ones:
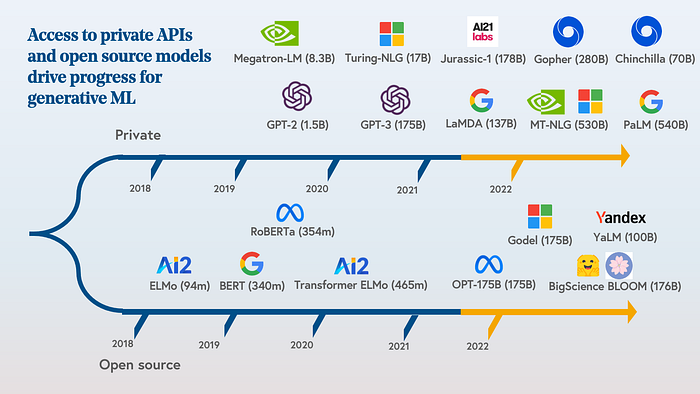
Further, managing costs is crucial for the effective usage of large language models like GPT-3 and ChatGPT. Pricing is usually determined by the number of tokens sent to the model (and received from it). Here’s a great blog post by CodiumAI on the topic.
Moats and defensibility for startups in the era of LLMs and foundation models
One of the areas that I was considering heavily when looking at startups that had received early access to GPT-3 in 2020 was defensibility.
As noted by Madrona, founders and developers at startups face an unappealing choice: easy to build but hard to defend — or the opposite. In the first option, foundation models allow developers to create apps in a weekend — or in minutes — which used to take months. But the developers are limited to those proprietary models’ off-the-shelf capabilities, which other developers can also use, meaning the developers must be creative to find a source of differentiation. In the second option, developers can extend the capabilities of open-source model architectures to build something novel and defensible. But that requires a galactic level of technical depth, which too few teams possess. That’s the opposite of the direction we need to go as an industry — we need more power in more hands, not even greater concentration.
As Andreessen Horowitz concluded in a recent article, there don’t appear to be today any systemic moats in generative AI. As a first-order approximation, applications lack strong product differentiation because they use similar models; models face unclear long-term differentiation because they are trained on similar datasets with similar architectures; cloud providers lack deep technical differentiation because they run the same GPUs; and even the hardware companies manufacture their chips at the same fabs.
In their analysis, Andreessen Horowitz divides the generative AI stack into three layers:
- Applications that integrate generative AI models into a user-facing product, either running their own model pipelines (“end-to-end apps”) or relying on a third-party API
- Models that power AI products, made available either as proprietary APIs or as open-source checkpoints (which, in turn, require a hosting solution)
- Infrastructure vendors (i.e. cloud platforms and hardware manufacturers) that run training and inference workloads for generative AI models
At the end of last year, I came across this really interesting article by Dan Shipper. In it, Dan notes how startups building infrastructure on current foundation models could be in trouble. Dan elaborates on how a fine-tuned product on the current generation of models will be instantly outperformed by non-fine-tuned next-generation models. Dan notes that it’s better to save your money and wait than build a sand castle on top of the current tech. Dan also recommends reading this article by Evan Armstrong.
As Evan says, AI is in many ways marketing gas. People are hungry for products that can perform tasks helping them in their vertical use cases. However, the winners will more often than not be determined by software and UX questions, not AI ones. For endpoints selling AI services, they will either need to fully own fine-tuned models or compete on the typical attributes of a SaaS startup.
Here we come back to the reality of product design and user experience being a key driver. To quote Christoph Janz, vertical SaaS startups usually win by:
- Having a deeper understanding of the customers in their industry
- Solving their specific problems in the absolute best way
- Marketing/selling exclusively to a narrowly defined segment of companies
- Adding more layers of functionality over time, increasing ACV and stickiness
Is AI coming for developer and data jobs?
One recurring theme I’ve seen on social media is LLMs replacing e.g. software or data engineers. In my opinion, LLMs like ChatGPT won’t initially replace any software data-related jobs.
One might think that ChatGPT can write boilerplate code faster and seemingly better than some programmers. So will it replace software engineers anytime soon? As Clement Mihailescu says: no.
E.g. ChatGPT seems to be much more of an assistant than any actual worker. It will help users get prompts, code, and generalized information faster than digging through e.g. Stack Overflow or just Googling something and it may even be more useful and personalized in some cases.
I think within the next 5–10 years it’ll just be an expectation that you can get more work done using tools like ChatGPT. So productivity should theoretically be going up in a shorter time. As noted by Jason Warner from Redpoint Ventures (he is the former CTO of GitHub), AI is not coming after developers' jobs. But the nature of the job is definitely changing — just as it changed in the 80s, 90s, 2000s, etc. Copilot was one of the last projects that Jason incubated at GitHub. The entire premise around Copilot was augmenting developers — not to replace them but give developers superpowers to become more efficient.
I love how Jason compares Copilot to an Ironman suit for developers, not a droid. There are elements of judgment and taste that can’t be taken away from humans in the unforeseeable future. Instead of replacing software or data engineers, LLMs such as ChatGPT will serve as an amazing quality-of-life-improvement tool for them, helping them perform certain programming tasks much faster.
Further, I’m hearing more and more software engineers being varied about using tools such as Copilot due to IP risks. Event Microsoft warned recently employees against sharing “sensitive data” with ChatGPT. Amazon issued similar guidance recently. Leaked internal communications revealed that Microsoft’s CTO cautioned employees against sharing sensitive data in case it’s used for future AI training models.
Leaked internal communications revealed that Microsoft’s CTO office told employees that using ChatGPT is fine. But it cautioned against sharing sensitive data in case it’s used for future AI training models.
If a company is looking to replace jobs utilizing tools such as ChatGPT, I firmly believe that their data quality would need to be more than top-notch for it to be realistic in any sense. This is not realistic for 99,99% of the companies in the near or mid-term future.
Interestingly, software engineers are becoming increasingly involved in machine learning — an emerging persona within AI/ML. As mentioned by Astasia Myers, this is because foundational models lower the barrier to building ML models and are a higher level of abstraction, for the first time we are seeing software developers become part of the ML development process.
Not everything is about LLMs — the increasing data gap
The rise of foundation models and LLMs is a significant shift for the masses right now. Subsequently, it might cause a data gap.
Here’s a great post by Alexander Ratner predicting how the gap between generative and predictive AI will widen.
Why? It all comes down to data.
As noted by Alexander, because of this data gap, predictive AI will seem stuck while generative AI accelerates in 2023. Most high-value AI will however still be predictive.
The truth is that not everything is about generating text or images. In reality, a lot of high-value AI/ML will still be predictive utilizing tabular datasets. The majority of business use cases out there for AI are still done with proprietary tabular business data.
The graph below is from a paper from July ’22 that looked at 45 mid-sized datasets and found that tree-based models (XGBoost & random forests) still outperformed deep neural networks on tabular datasets. Find the paper here.
Despite product and business model innovation in generative AI, real-world ROI also remains steadily concentrated around predictive AI, utilizing tabular datasets — which often leads to frustrating outcomes.
Why? It all comes down to the data, not the AI/ML models per se.
Reaching the performance needed to deploy predictive ML requires high-quality & well-labeled data for each use case and context. Building predictive ML models on top of foundation generative AI models can help, but does not e.g. solve the data quality challenge that often leads to disappointing results and failed AI/ML initiatives. The basics just can’t be removed. foundation models can be a complement, not a replacement.
I have used this quote by Chad Sanderson often, but it’s just spot on:
“Without high-quality data, every AI/ML initiative will be underwhelming at best and actively damaging the business at worst.”
Be excited about generative AI and foundation models, but never forget the basics. In the 2010s, cloud infrastructures enabled a generation of companies to build and scale their businesses. In this decade, cloud infrastructure is table stakes, and the differentiation of a company comes from data, analytics, and AI/ML (in that order).
As Chip Huyen has wisely said:
Machine learning algorithms don’t predict the future, but encode the past, perpetuating the biases in the data and more.
The model itself is actually a tiny part of getting an ML product or service live and deployed in a way where it delivers real business value.
As highlighted by Aurimas Griciūnas, data lifecycle in ML/AI systems start with data engineering pipelines; we should place an unproportionally high focus on making data engineering pipelines work smoothly an prevent any data quality issues downstream. Any issue in the data engineering flow will be multiplied each time it doesn’t get fixed and moves one step forward in the data value chain.
Focus on your data quality, that’s where you gain the most significant advantage in AI/ML.
Final thoughts
We should all be excited about AI and LLMs. We’re entering an era of AI-first software, which has the potential to create supercycle of opportunity and disruption in software not seen since mobile and cloud. One fascinating part of the ChatGPT discussion (and large language models in general) is how they’re going to go from impressive novelty to being built in everyday enterprise workflows.
Capabilities of generic large language models are starting to create value, but most value from such models will be created for specialized use cases using specialized data.
As noted by Bessemer Venture Partners, as LLMs improve, we are seeing the advances flow to downstream tasks and multi-modal models. These are models that can take multiple different input modalities (e.g. image, text, audio), and produce outputs of different modalities. This is not unlike human cognition; a child reading a picture book uses both the text and illustrations to visualize the story.
It’s good to remember that ChatGPT is far from the most impactful progress happening in AI and that we’re still in the very early days of the AI wave.
Picking winners and losers this early in the foundation model and generative AI space might be a fool’s errand. The frantic pace of innovation might still allow new startups to emerge and compete at scale with the big AI labs. Not easy, but certainly possible with the amount of capital chasing this market.
PS. As a closing to this section, I recently came across this really interesting paper, showcasing how LLMs-generated text can be detected by embedding signals that are invisible to humans but algorithmically detectable. It’s essentially a watermarking framework for language models. It appears to reach 99% confidence on 23 words.
Recommended further readings
📚 Here’s What I Saw at an AI Hackathon by Dan Shipper
📚 6 New Theories About AI by Evan Armstrong
📚 Who Owns the Generative AI Platform? by Andreessen Horowitz
📚 Foundation Models: The future (still) isn’t happening fast enough by Madrona
📚 Do Large Language Models learn world models or just surface statistics? by Kenneth Li
📚 Advice for Building in AI by Nathan Baschez
📚 Value accrual in the modern AI stack by Data-driven VC
📚 Quick thoughts on ChatGPT and why it matters for SaaS startups by Christoph Janz
📚 If You’re Not First, You’re Last: How AI Becomes Mission Critical by Base10
📚 A Basic Understanding of the ChatGPT Model by Renu Khandelwal
📚 Value Accrual in the Modern AI Stack by Earlybird Venture Capital
📚 AI Looks Like a Bubble — Investors need to take a cold shower by Evan Armstrong
📚 OpenAI’s Tiny Army vs Meta-Google’s Dream Team by Analytics India Magazine
📚 Huge “foundation models” are turbo-charging AI progress by The Economist
📚 Foundation Models: A Primer for Investors and Builders by Kenn So and Ben Lorica
📚 Foundation Models and the Future of Multi-Modal AI by Last Week in AI
📚 Foundational Model Orchestration (FOMO) — A Primer by Astasia Myers
Learn the basics:
📚 ChatGPT is everywhere. Here’s where it came from by MIT Technology Review
📚 What Is ChatGPT Doing … and Why Does It Work? by Stephen Wolfram
Generative AI startup market maps:
🗺️ NFX
🗺️ Base10
🗺️ Antler
🗺️ Madrona
🗺️ Sifted
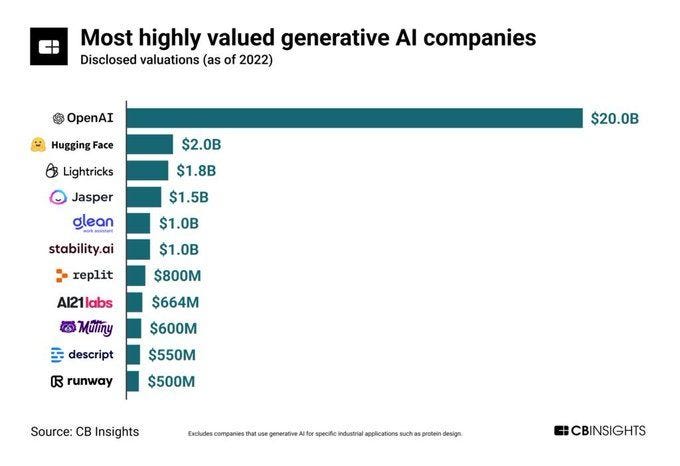
Other market maps that should be included? Feel free to comment below.

